CogVLM大模推理代码详细解读
文章目录
- 前言
- 一、参数介绍
-
- 1.cogvlm-grounding-generalist参数介绍
- 二、模型构建
-
- 1、创建主函数(get_model)
- 2、调用sat库模型构建函数(base_model.py)
- 3、模型类构建模型(self.add_mixin)
- 4、整体结构
- 5、模型运行结果
- 三、CogVLM推理源码解读
-
- 1、推理整体代码
- 2、CogVLMModel.from_pretrained
- 3、from_pretrained函数
- 4、from_pretrained_base函数
- 5、token与后处理
- 6、整体结构
前言
最近,我一直在查看多模态大模型相关内容,而CogVLM是我们公司需要重点研究模型。同时,CogVLM模型很少有文章涉及到代码相关解读,令更多小白困惑。介于此,我会陆续解读源码并分享。本篇文章,我将分享CogVLM推理整个pipeline走向,带大家熟知CogVLM模型推理过程,这里推理过程有别于hugginggface通用推理构建方法,本篇文章主要内容为作者训练好的参数说明、模型构建与推理stream。最终帮助大家熟知模型整个推理pipeline,特别是对sat库使用有一定认识。
注:CogVLM代码可读性不那么友好,因很多内容被sat库封装。
一、参数介绍
官网代码可查看已开源模型有如下:
We open-source different checkpoints for different downstreaming tasks:
cogvlm-chat-v1.1 The model supports multiple rounds of chat and vqa simultaneously, with different prompts.
cogvlm-base-224 The original checkpoint after text-image pretraining.
cogvlm-base-490 Amplify the resolution to 490 through position encoding interpolation from cogvlm-base-224.
cogvlm-grounding-generalist. This checkpoint supports different visual grounding tasks, e.g. REC, Grounding Captioning, etc.
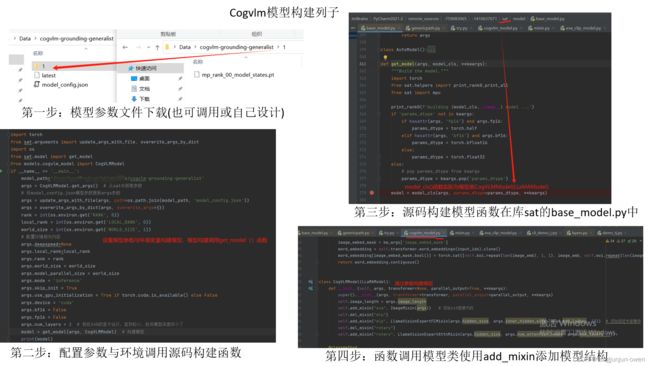
我大概看了下,里面有一个文件是模型相关配置文件(model_cofig.json-基本差不多)和一个权重文件,我将是使用cogvlm-grounding-generalist作为列子介绍。
1.cogvlm-grounding-generalist参数介绍
下载解压后文件内容如下:

其中模型参数文件如下(其它基准参数文件差不多):
{
"model_class": "CogVLMModel",
"tokenizer_type": "vicuna-7b-v1.5",
"num_layers": 32,
"hidden_size": 4096,
"num_attention_heads": 32,
"vocab_size": 32000,
"layernorm_order": "pre",
"model_parallel_size": 1,
"max_sequence_length": 4096,
"use_bias": false,
"inner_hidden_size": 11008,
"image_length": 1225,
"eva_args": {
"model_class": "EVA2CLIPModel",
"num_layers": 63,
"hidden_size": 1792,
"num_attention_heads": 16,
"vocab_size": 1,
"layernorm_order": "post",
"model_parallel_size": 1,
"max_sequence_length": 1226,
"inner_hidden_size": 15360,
"use_final_layernorm": false,
"layernorm_epsilon": 1e-06,
"row_parallel_linear_final_bias": false,
"image_size": [
490,
490
],
"pre_len": 1,
"post_len": 0,
"in_channels": 3,
"patch_size": 14
},
"bos_token_id": 1,
"eos_token_id": 2,
"pad_token_id": 0
}
二、模型构建
在这一部分,我想使用清华提供库构建cogvlm-grounding-generalist模型。大致模型构建模型使用get_model函数(下面推理内容模型创立是对get_model模型进行包装),而get_model函数在sat库中base_model.py文件中,在通过类的classmethod(细节可参看点击这里)方式调用CogVLMModel模型类,在根据参数使用self.add_mixin创建模型模块,而构建完模型。
1、创建主函数(get_model)
说白了,设置一些列参数给模型入口函数get_model提供args参数,其代码如下:
import torch
from sat.arguments import update_args_with_file, overwrite_args_by_dict
import os
from sat.model import get_model
from models.cogvlm_model import CogVLMModel
if __name__ == '__main__':
model_path='/home/oem/Project/tj/weights/cogvlm-grounding-generalist'
args = CogVLMModel.get_args() # 从sat中获取参数
# 将model_config.json模型参数更新args参数
args = update_args_with_file(args, path=os.path.join(model_path, 'model_config.json'))
args = overwrite_args_by_dict(args, overwrite_args={})
rank = int(os.environ.get('RANK', 0))
local_rank = int(os.environ.get('LOCAL_RANK', 0))
world_size = int(os.environ.get('WORLD_SIZE', 1))
# 配置环境相关内容
args.deepspeed=None
args.local_rank=local_rank
args.rank = rank
args.world_size = world_size
args.model_parallel_size = world_size
args.mode = 'inference'
args.skip_init = True
args.use_gpu_initialization = True if torch.cuda.is_available() else False
args.device = 'cuda'
args.bf16 = False
args.fp16 = False
args.num_layers = 2 # 我在24G的显卡运行,显存较小,故将模型深度改小了
model = get_model(args, CogVLMModel) # 构建模型
print(model)
其中以下第一行是model_config.json模型文件参数替换args参数,使用update_args_with_file函数,第二行是田间overwrite_args参数到args中,使用overwrite_args_by_dict函数实现。
args = update_args_with_file(args, path=os.path.join(model_path, 'model_config.json'))
args = overwrite_args_by_dict(args, overwrite_args={})
这里我要说明模型参数也可使用此方式args = CogVLMModel.get_args()调用,后面会在get_model使用model_cofig.json文件替换args中的值!
其整体如图:

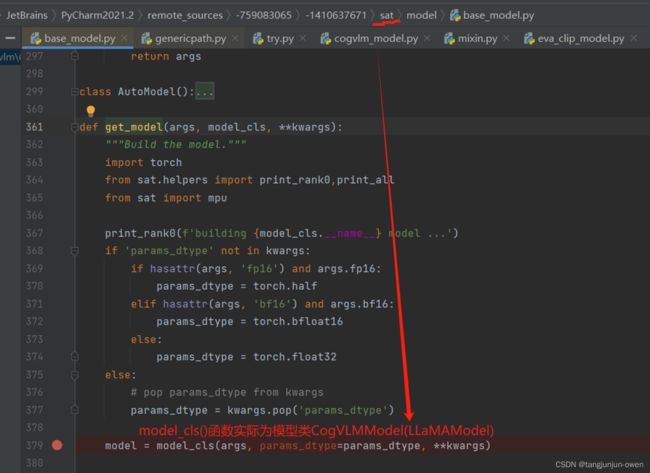
2、调用sat库模型构建函数(base_model.py)
然后进入sat库中base_model.py文件的get_model函数,在通过类的classmethod方式调用CogVLMModel模型类,如下图:
3、模型类构建模型(self.add_mixin)
最后进入cofvlm_model.py文件的CogVLMModel类中,更具参数使用self.add_mixin创建模型模块,而完成模型构建。当然,每一个self.add_mixin的字符都是调用隐藏在sat库中模块实现,我暂时不做说明。

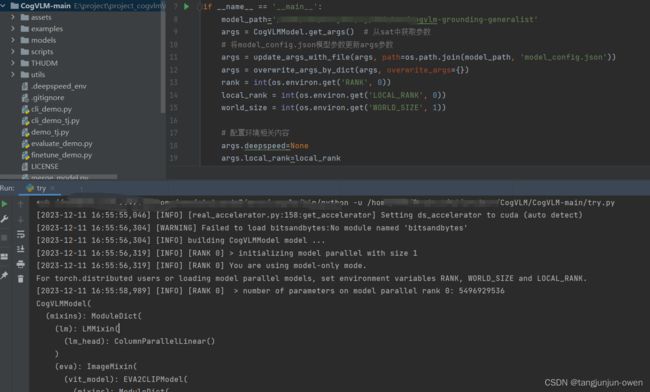
4、整体结构
最后,我也给出整个模型构建流程,如下:
5、模型运行结果
模型运行结果如下:
三、CogVLM推理源码解读
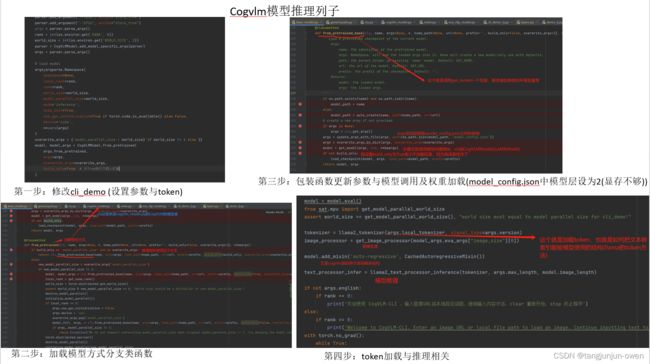
CogVLM推理模型构建大致和上面模型构建流程差不多CogVLMModel.from_pretrained包装处理。当然,除了模型构建,推理部分也包含token编码与后处理,我使用源码cli_demo.py,做了一些小的修改。
1、推理整体代码
推理整体代码如下,可直接运行出结果,而我这里鉴于显存不足,我将model_cofig.json文件的number_layer=32改成2,且不加载作者提供权重,使用build_only=True可实现权重不加载。
# -*- encoding: utf-8 -*-
import os, sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import torch
import argparse
from sat.model.mixins import CachedAutoregressiveMixin
from utils.chat import chat
from models.cogvlm_model import CogVLMModel
from utils.language import llama2_tokenizer, llama2_text_processor_inference
from utils.vision import get_image_processor
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--max_length", type=int, default=2048, help='max length of the total sequence')
parser.add_argument("--top_p", type=float, default=0.4, help='top p for nucleus sampling')
parser.add_argument("--top_k", type=int, default=1, help='top k for top k sampling')
parser.add_argument("--temperature", type=float, default=.8, help='temperature for sampling')
parser.add_argument("--english", action='store_true', help='only output English')
parser.add_argument("--version", type=str, default="chat", help='version to interact with')
parser.add_argument("--from_pretrained", type=str, default="/home/weights/cogvlm-grounding-generalist", help='pretrained ckpt')
parser.add_argument("--local_tokenizer", type=str, default="/home/project/CogVLM/CogVLM-main/lmsys/vicuna-7b-v1.5", help='tokenizer path')
parser.add_argument("--no_prompt", action='store_true', help='Sometimes there is no prompt in stage 1')
parser.add_argument("--fp16", action="store_true")
parser.add_argument("--bf16", action="store_true")
args = parser.parse_args()
rank = int(os.environ.get('RANK', 0))
world_size = int(os.environ.get('WORLD_SIZE', 1))
parser = CogVLMModel.add_model_specific_args(parser)
args = parser.parse_args()
# load model
args=argparse.Namespace(
deepspeed=None,
local_rank=rank,
rank=rank,
world_size=world_size,
model_parallel_size=world_size,
mode='inference',
skip_init=True,
use_gpu_initialization=True if torch.cuda.is_available() else False,
device='cuda',
**vars(args)
)
overwrite_args = {'model_parallel_size': world_size} if world_size != 1 else {}
model, model_args = CogVLMModel.from_pretrained(
args.from_pretrained,
args=args,
overwrite_args=overwrite_args,
build_only=True
)
model = model.eval()
from sat.mpu import get_model_parallel_world_size
assert world_size == get_model_parallel_world_size(), "world size must equal to model parallel size for cli_demo!"
tokenizer = llama2_tokenizer(args.local_tokenizer, signal_type=args.version)
image_processor = get_image_processor(model_args.eva_args["image_size"][0])
model.add_mixin('auto-regressive', CachedAutoregressiveMixin())
text_processor_infer = llama2_text_processor_inference(tokenizer, args.max_length, model.image_length)
if not args.english:
if rank == 0:
print('欢迎使用 CogVLM-CLI ,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序')
else:
if rank == 0:
print('Welcome to CogVLM-CLI. Enter an image URL or local file path to load an image. Continue inputting text to engage in a conversation. Type "clear" to start over, or "stop" to end the program.')
with torch.no_grad():
while True:
history = None
cache_image = None
if not args.english:
if rank == 0:
image_path = [input("请输入图像路径或URL(回车进入纯文本对话): ")]
else:
image_path = [None]
else:
if rank == 0:
image_path = [input("Please enter the image path or URL (press Enter for plain text conversation): ")]
else:
image_path = [None]
if world_size > 1:
torch.distributed.broadcast_object_list(image_path, 0)
image_path = image_path[0]
assert image_path is not None
if image_path == 'stop':
break
if args.no_prompt and len(image_path) > 0:
query = ""
else:
if not args.english:
if rank == 0:
query = [input("用户:")]
else:
query = [None]
else:
if rank == 0:
query = [input("User: ")]
else:
query = [None]
if world_size > 1:
torch.distributed.broadcast_object_list(query, 0)
query = query[0]
assert query is not None
while True:
if query == "clear":
break
if query == "stop":
sys.exit(0)
try:
response, history, cache_image = chat(
image_path,
model,
text_processor_infer,
image_processor,
query,
history=history,
image=cache_image,
max_length=args.max_length,
top_p=args.top_p,
temperature=args.temperature,
top_k=args.top_k,
invalid_slices=text_processor_infer.invalid_slices,
no_prompt=args.no_prompt
)
except Exception as e:
print(e)
break
if rank == 0:
if not args.english:
print("模型:"+response)
if tokenizer.signal_type == "grounding":
print("Grounding 结果已保存至 ./output.png")
else:
print("Model: "+response)
if tokenizer.signal_type == "grounding":
print("Grounding result is saved at ./output.png")
image_path = None
if not args.english:
if rank == 0:
query = [input("用户:")]
else:
query = [None]
else:
if rank == 0:
query = [input("User: ")]
else:
query = [None]
if world_size > 1:
torch.distributed.broadcast_object_list(query, 0)
query = query[0]
assert query is not None
if __name__ == "__main__":
main()
运行结果如下:

2、CogVLMModel.from_pretrained
使用上面推理代码给到参数进入CogVLMModel.from_pretrained包装函数,主要加载模型参数和权重(但我没加载权重)。

3、from_pretrained函数
通过上面进入类@classmethod的from_pretrained函数调用,进入from_pretrained_base函数。如下图:

4、from_pretrained_base函数
通过上面进入类@classmethod的from_pretrained_base函数调用。对于将调用get_model函数, 这和上面模型构建说明一致;对于权重加载,在最后使用load_checkpoint加载。如下图:

5、token与后处理
最后,推理token与后处理也是源码内容,解释如下图:

6、整体结构
最后,我也给出整个模型构建流程,如下: