Imagen 2 发布、Gemini Pro 免费体验、代码平台 Duet AI 上线,谷歌大爆发
在上周发布 Gemini 后,本周谷歌又有了新动作。
12 月 13 日,谷歌在其云平台上推出了一系列 AI 模型以供用户体验并实际应用:向开发者和企业开放 Gemini Pro、面向开发者和安全运营的 Duet AI、图像生成 Imagen 2 以及用于医疗保健场景的 MedLM。
01
Gemini Pro 开发者 API 上线,目前免费试用
谷歌 Gemini 发布一周之后,面向开发者的 API 也终于上线了。
目前,不管是 Gemini Pro,还是 Gemini Pro Vision,都可以免费体验。虽然每分钟最多支持 60 次请求,但基本上可以满足大多数应用程序开发的需求。
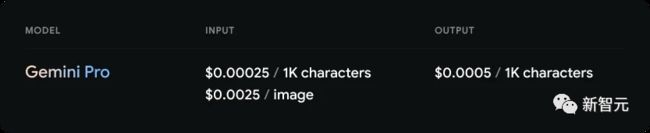
而到了明年初上线时,谷歌将正式开启收费。API 定价,也将和 GPT-3.5 看齐,都是 0.001 刀每千 token 输入,0.002 刀每千 token 输出。
![]()
Gemini Pro

GPT-3.5
具体来说:
-
目前支持 32K 的上下文窗口,之后还会进一步扩大。
-
其他基本的功能也都支持:函数调用、嵌入、语义检索、自定义知识。
-
支持全球 180 多个国家和地区的 38 种语言。
-
支持文本的 API 输出,不过输出暂时还只支持文字。
-
提供了 Python、Android (Kotlin)、Node.js、Swift 和 JavaScript 的 SDK 支持。
-
在当前版本中,Gemini Pro 接受文本作为输入,并可生成文本输出。谷歌此次还发布了专用的 Gemini Pro Vision 多模态端点,可接受文本和图像作为输入,并据此输出文本响应。
微调方面,用户可以通过 Google AI Studio 直接接入 Gemini Pro API,而且用户还可以通过 Vertex AI 来全面地自定义 Gemini。
其中,用户可以使用自己的数据,在无代码环境构建自己的 Gemini 对话机器人,支持 RAG,搜索,嵌入,对话剧本等功能。而且谷歌保证,所有用户的数据和 IP 谷歌都不会用来训练模型。
借助 Vertex AI,同样可以访问 Gemini 模型,并能够:
-
使用自有企业数据微调及蒸馏 Gemini,立足底层对模型进行增强,使其包含最新信息和扩展以获取实际功能。
-
在低代码 / 无代码环境中构建 Gemini 支持的搜索和对话 agent,包括支持检索增强生成(RAG)、混合搜索、嵌入、对话 playbook 等。
-
安心进行应用部署。谷歌不会利用 Google Cloud 上的客户输入或输出数据训练 Gemini 模型,相关数据与 IP 将始终归客户所有。
目前,开发者可以通过 Google AI Studio 免费访问 Gemini Pro 与 Gemini Pro Vision,每分钟最多支持 60 条请求,可以满足大部分应用开发需要。Vertex AI 计划于明年发布正式版本,在此之前开发者同样能以每分钟 60 条请求的方式访问 Gemini 基础模型。
02
文生图模型 Imagen 2 发布,图像更逼真
距离上个版本 Imagen 的发布已经过去了一年半。Imagen 2 包含了更强的提示一致性,更逼真的图像生成,支持了图像编辑功能,包括图像修复和图像扩展。
自然语言理解能力
为提高生成图像的质量和准确性,Imagen 2 增加了图像描述的详细信息。这使得 Imagen 2 能更好地理解不同风格的标题,从而更准确地响应用户的指令。通过这种细化的图像-描述配对,Imagen 2 提高了对图文关系以及上下文细节的理解和感知。
除了 DALL·E 3 之外,我们又有了一个仅凭自然语言就能生图的模型。
对于依赖视觉内容的行业来说,这彻底改变了游戏规则,大大减少了传统内容制作所需的时间,内容创作者可以以前所未有的速度,制作高质量的视觉效果。
同时,Imagen 2 还具有无可比拟的图像质量和多功能性。Imagen 2 用到了谷歌最先进的文本到图像扩散技术,生图质量极高、效果逼真,而且和用户的提示具有高度的一致性。
原因在于,它是使用训练数据的自然分布来生成更逼真的图像,而非采用预先编程的样式。

A jellyfish on a dark blue background
水母在深蓝色的背景下悠然漂浮
可以看到,Imagen 2 的图像生成能力非常惊人。
创新的图像编辑,更强的「修复」和「扩图」
Imagen 2 带来了创新的图像编辑功能,包括「inpainting(图像修复)」和「outpainting(图像扩展)」。

用户可通过 inpainting 功能在原始图像中添加新内容,或利用 outpainting 功能结合参考图像和遮罩,将图像扩展到原有边界之外。
这项技术是一个计划发布,计划在未来一年内融入谷歌云的 Vertex AI 中。
除了英语,Imagen 2 还支持其他 6 种语言(中文、印地语、日语、韩语、葡萄牙语、西班牙语),并计划在 2024 年初增加更多语言。这项功能还包括提示与输出之间的翻译能力,比如,可以用西班牙语提示,但指定输出为葡萄牙语。
为了帮助降低文本到图像生成技术的潜在风险和挑战,谷歌从设计和开发到产品部署都设置了强大的护栏。
Imagen 2 集成了 SynthID——用于加水印和识别 AI 生成内容的尖端工具包。这样,Google Cloud 平台的客户可以直接在图像中添加数字水印,同时不会降低图像质量。即使在对图像进行过滤、裁剪或使用有损压缩方案保存后,SynthID 仍然可以检测出。
需要注意的是:Imagen 2 目前还未提供用户 UI,仅供开发人员和云客户使用,需要通过谷歌云 Vertex AI 中的 Imagen API 使用。
03
Duet AI:代码生成平台
谷歌正式宣布全面推出 Duet AI for Developers,用于代码补全和生成的人工智能辅助工具套件。
更令人兴奋的是,未来几周将得到 Gemini 模型的加持。
要知道,当今开发者中最受欢迎的代码平台工具,非微软的 GitHub 的 Copilot 莫属。
与之不同的是,谷歌采用了 25 家公司的平台的数据集,来帮助开发人员构建应用程序,并排除代码故障。比如,Confluent、HashiCorp 和 MongoDB 将提供数据来训练 Duet AI for Developers,以帮助开发人员为其平台编写代码。

虽然这些合作伙伴的数据在代码补全和生成体验中大多有用,但 Datadog、JetBrains 和 LangChain 将提供文档和知识源。这些文档和知识源可能在 Duet AI for Developers 聊天体验中最有用。
例如,利用这些数据,该服务将能够为开发和运营团队提供有关如何创建测试自动化、解决生产中的问题和修复漏洞的信息。
谷歌云的一位宣传者 Richard Seroter 表示,人工智能如何帮助摆脱我们不喜欢做的事情?我们如何让编码变得更好?这就是我们一直在追逐的很多东西。我们如何构建一种人工智能助手,既能满足开发人员使用的工具,又能在其中加入一点谷歌的元素?

那么,如何在这些工具中加入谷歌的元素?
比如,在开发人员已经使用的所有流行集成开发环境之上,确保模型经过最新云原生实践的训练,并将其集成到谷歌云控制台中。Seroter 强调,谷歌着眼于整个 Duet AI 产品系列,其中 Duet AI in Security Operations 现在也作为企业级产品正式发布。
谷歌的 AI 编码工具研发过程与其他所有科技公司的产品基本相同。
例如,Seroter 指出,开发人员已经熟悉的 IDE 中的代码自动补全功能有助于开发人员保持工作流不变。与其他大厂一样,谷歌自身不认为这些工具会取代编码技能,但有助于提高开发人员的工作效率。
目前,一家「人工智能驱动的技术服务公司」Turing,在采用 Duet AI for Developers 后,生产力提高了 33%。
Duet AI for Developers 目前支持 20+种语言,包括 C、C++、Java、JavaScript 和 Python。除了常用的编码功能之外,它还包括对 AI 日志汇总和错误解释的支持,例如还支持与 Cloud Logging、以及 Smart Actions 的集成,谷歌将其描述为执行单元测试生成等任务的一键式快捷方式。
明年 1 月底之前,Duet AI for Developers 将免费开放。之后,谷歌也会采取收费制,每月 19 美元,按年度为单位。
04
其他产品
此外,谷歌还推出了 MedLM,这是一个面向医疗保健用例的大语言模型。其中的两套模型均基于谷歌自家的 Med-PaLM 2 系列。其中较大、更强的模型专为较复杂的任务而设计,例如筛选学术论文及技术文档以提供潜在的新药研发线索;另一套模型则负责处理比较简单的杂务,例如总结医患对话和回应常见的医疗咨询问题。
MedLM 模型的早期采用者包括 HCA Healthcare 诊所、药物设计企业 BenchSci,以及埃森哲与德勤等。
谷歌表示,未来几周,MedLM 模型将正式入驻谷歌的开放 Model Garden,后续还将有更多基于 Gemini 的模型被纳入 MedLM 家族以提供更多功能。
参考链接:
https://blog.google/technology/ai/google-gemini-pro-imagen-duet-ai-update/
https://blog.google/technology/ai/gemini-api-developers-cloud/
https://www.theregister.com/2023/12/13/google_gemini_duet_ai/
https://deepmind.google/technologies/imagen-2/
https://cloud.google.com/blog/products/ai-machine-learning/imagen-2-on-vertex-ai-is-now-generally-available
文章转自公众号「AI 前线」、「新智元」