perl脚本中使用eval函数执行可能有异常的操作
perl脚本中有时候执行的操作可能会引发异常,为了直观的说明,这里举一个json反序列化的例子,脚本如下:
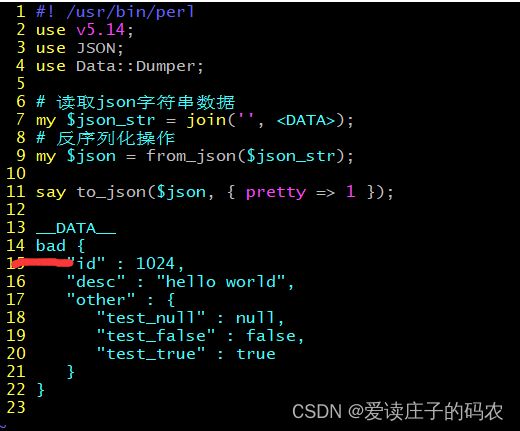
#! /usr/bin/perl
use v5.14;
use JSON;
use Data::Dumper;
# 读取json字符串数据
my $json_str = join('', );
# 反序列化操作
my $json = from_json($json_str);
say to_json($json, { pretty => 1 });
__DATA__
bad {
"id" : 1024,
"desc" : "hello world",
"other" : {
"test_null" : null,
"test_false" : false,
"test_true" : true
}
}
脚本中有意把正确json字符串之前加了几个字符,显然这个json字符串是不符合规范格式的,在git bash中执行这个脚本,结果如下:
![]()
下面用perl的eval函数改造这个脚本:
#! /usr/bin/perl
use v5.14;
use JSON;
use Data::Dumper;
# 读取json字符串数据
my $json_str = join('', );
# 反序列化操作
my $json = eval {
return from_json($json_str);
};
unless (defined $json) {
say "from_json failed !!!!";
} else {
say to_json($json, { pretty => 1 });
}
__DATA__
bad {
"id" : 1024,
"desc" : "hello world",
"other" : {
"test_null" : null,
"test_false" : false,
"test_true" : true
}
}
脚本中用把from_json的操作放在eval函数中,输出结果如下:
![]()
显然,这个结果是可控的,可预期的。比如就可以使用这种方法判断json字符串是否合法,能够正常反序列化的就是合法的,否则就是非法的。eval函数的具体使用可以使用perldoc -f eval查看。
eval EXPR
eval BLOCK
eval "eval" in all its forms is used to execute a little Perl
program, trapping any errors encountered so they don't crash the
calling program.
Plain "eval" with no argument is just "eval EXPR", where the
expression is understood to be contained in $_. Thus there are
only two real "eval" forms; the one with an EXPR is often called
"string eval". In a string eval, the value of the expression
(which is itself determined within scalar context) is first
parsed, and if there were no errors, executed as a block within
the lexical context of the current Perl program. This form is
typically used to delay parsing and subsequent execution of the
text of EXPR until run time. Note that the value is parsed every
time the "eval" executes.
The other form is called "block eval". It is less general than
string eval, but the code within the BLOCK is parsed only once
(at the same time the code surrounding the "eval" itself was
parsed) and executed within the context of the current Perl
program. This form is typically used to trap exceptions more
efficiently than the first, while also providing the benefit of
checking the code within BLOCK at compile time. BLOCK is parsed
and compiled just once. Since errors are trapped, it often is
used to check if a given feature is available.
In both forms, the value returned is the value of the last
expression evaluated inside the mini-program; a return statement
may also be used, just as with subroutines. The expression
providing the return value is evaluated in void, scalar, or list
context, depending on the context of the "eval" itself. See
"wantarray" for more on how the evaluation context can be
determined.
If there is a syntax error or runtime error, or a "die"
statement is executed, "eval" returns "undef" in scalar context,
or an empty list in list context, and $@ is set to the error
message. (Prior to 5.16, a bug caused "undef" to be returned in
list context for syntax errors, but not for runtime errors.) If
there was no error, $@ is set to the empty string. A control
flow operator like "last" or "goto" can bypass the setting of
$@. Beware that using "eval" neither silences Perl from printing
warnings to STDERR, nor does it stuff the text of warning
messages into $@. To do either of those, you have to use the
$SIG{__WARN__} facility, or turn off warnings inside the BLOCK
or EXPR using "no warnings 'all'". See "warn", perlvar, and
warnings.
Note that, because "eval" traps otherwise-fatal errors, it is
useful for determining whether a particular feature (such as
"socket" or "symlink") is implemented. It is also Perl's
exception-trapping mechanism, where the "die" operator is used
to raise exceptions.
Before Perl 5.14, the assignment to $@ occurred before
restoration of localized variables, which means that for your
code to run on older versions, a temporary is required if you
want to mask some, but not all errors:
# alter $@ on nefarious repugnancy only
{
my $e;
{
local $@; # protect existing $@
eval { test_repugnancy() };
# $@ =~ /nefarious/ and die $@; # Perl 5.14 and higher only
$@ =~ /nefarious/ and $e = $@;
}
die $e if defined $e
}
There are some different considerations for each form:
String eval
Since the return value of EXPR is executed as a block within
the lexical context of the current Perl program, any outer
lexical variables are visible to it, and any package
variable settings or subroutine and format definitions
remain afterwards.
Under the "unicode_eval" feature
If this feature is enabled (which is the default under a
"use 5.16" or higher declaration), EXPR is considered to
be in the same encoding as the surrounding program. Thus
if "use utf8" is in effect, the string will be treated
as being UTF-8 encoded. Otherwise, the string is
considered to be a sequence of independent bytes. Bytes
that correspond to ASCII-range code points will have
their normal meanings for operators in the string. The
treatment of the other bytes depends on if the
"'unicode_strings"" feature is in effect.
In a plain "eval" without an EXPR argument, being in
"use utf8" or not is irrelevant; the UTF-8ness of $_
itself determines the behavior.
Any "use utf8" or "no utf8" declarations within the
string have no effect, and source filters are forbidden.
("unicode_strings", however, can appear within the
string.) See also the "evalbytes" operator, which works
properly with source filters.
Variables defined outside the "eval" and used inside it
retain their original UTF-8ness. Everything inside the
string follows the normal rules for a Perl program with
the given state of "use utf8".
Outside the "unicode_eval" feature
In this case, the behavior is problematic and is not so
easily described. Here are two bugs that cannot easily
be fixed without breaking existing programs:
* It can lose track of whether something should be
encoded as UTF-8 or not.
* Source filters activated within "eval" leak out into
whichever file scope is currently being compiled. To
give an example with the CPAN module
Semi::Semicolons:
BEGIN { eval "use Semi::Semicolons; # not filtered" }
# filtered here!
"evalbytes" fixes that to work the way one would
expect:
use feature "evalbytes";
BEGIN { evalbytes "use Semi::Semicolons; # filtered" }
# not filtered
Problems can arise if the string expands a scalar containing
a floating point number. That scalar can expand to letters,
such as "NaN" or "Infinity"; or, within the scope of a "use
locale", the decimal point character may be something other
than a dot (such as a comma). None of these are likely to
parse as you are likely expecting.
You should be especially careful to remember what's being
looked at when:
eval $x; # CASE 1
eval "$x"; # CASE 2
eval '$x'; # CASE 3
eval { $x }; # CASE 4
eval "\$$x++"; # CASE 5
$$x++; # CASE 6
Cases 1 and 2 above behave identically: they run the code
contained in the variable $x. (Although case 2 has
misleading double quotes making the reader wonder what else
might be happening (nothing is).) Cases 3 and 4 likewise
behave in the same way: they run the code '$x', which does
nothing but return the value of $x. (Case 4 is preferred for
purely visual reasons, but it also has the advantage of
compiling at compile-time instead of at run-time.) Case 5 is
a place where normally you *would* like to use double
quotes, except that in this particular situation, you can
just use symbolic references instead, as in case 6.
An "eval ''" executed within a subroutine defined in the
"DB" package doesn't see the usual surrounding lexical
scope, but rather the scope of the first non-DB piece of
code that called it. You don't normally need to worry about
this unless you are writing a Perl debugger.
The final semicolon, if any, may be omitted from the value
of EXPR.
Block eval
If the code to be executed doesn't vary, you may use the
eval-BLOCK form to trap run-time errors without incurring
the penalty of recompiling each time. The error, if any, is
still returned in $@. Examples:
# make divide-by-zero nonfatal
eval { $answer = $a / $b; }; warn $@ if $@;
# same thing, but less efficient
eval '$answer = $a / $b'; warn $@ if $@;
# a compile-time error
eval { $answer = }; # WRONG
# a run-time error
eval '$answer ='; # sets $@
If you want to trap errors when loading an XS module, some
problems with the binary interface (such as Perl version
skew) may be fatal even with "eval" unless
$ENV{PERL_DL_NONLAZY} is set. See perlrun.
Using the "eval {}" form as an exception trap in libraries
does have some issues. Due to the current arguably broken
state of "__DIE__" hooks, you may wish not to trigger any
"__DIE__" hooks that user code may have installed. You can
use the "local $SIG{__DIE__}" construct for this purpose, as
this example shows:
# a private exception trap for divide-by-zero
eval { local $SIG{'__DIE__'}; $answer = $a / $b; };
warn $@ if $@;
This is especially significant, given that "__DIE__" hooks
can call "die" again, which has the effect of changing their
error messages:
# __DIE__ hooks may modify error messages
{
local $SIG{'__DIE__'} =
sub { (my $x = $_[0]) =~ s/foo/bar/g; die $x };
eval { die "foo lives here" };
print $@ if $@; # prints "bar lives here"
}
Because this promotes action at a distance, this
counterintuitive behavior may be fixed in a future release.
"eval BLOCK" does *not* count as a loop, so the loop control
statements "next", "last", or "redo" cannot be used to leave
or restart the block.
The final semicolon, if any, may be omitted from within the
BLOCK.