RKE2部署Kubernetes(四)rancher2.7.9日志管理Logging Operator
rancher2.7.9日志管理Logging Operator
这里写目录标题
- rancher2.7.9日志管理Logging Operator
- 一级目录
-
- 二级目录
-
- 三级目录
- 1、Logging Operator 工作原理
- 2、启用 Logging
- 3、CRD方式配置
-
- Flow 和 ClusterFlow
-
- match
- filters
- Parser 插件
- Prometheus 插件
- 小结
- Output 和 ClusterOutput
-
- Output
- Output-Kafka
- Output-Elasticsearch
- flow 和 output 相关联
- 小结
- 4、在 Rancher UI 上对 flow 和 output 进行配置
-
-
- 创建 outputs/clusteroutputs
- 创建 flow/clusterflow
- 验证
-
- 总结
- 一些 Tips
一级目录
二级目录
三级目录
历史背景:
在 SUSE Rancher 2.5 以前,日志收集的架构是使用 Fluentd 收集指定目录日志或者容器标准输出流后,再通过 UI 日志功能页面的配置发送到指定的后端。如 Elasticsearch、splunk、kafka、syslog、fluentd 等常见的后端工具,可以自动化地收集 kubernetes 集群和运行于集群之上的工作负载日志。这种方式无疑是非常简单、易用、方便的,但是随着用户对云原生理解的加深,对业务日志分析颗粒度要求的提高,之前的日志收集方式有些太过死板,灵活性非常差,已经无法满足对日志收集具有更高要求的用户了。
于是从 SUSE Rancher 2.5 版本开始,BanzaiCloud 公司的开源产品 Logging Operator 成为了新一代 SUSE Rancher 容器云平台日志采集功能的组成组件。SUSE Rancher 2.5 版本作为新日志组件的过渡版本,保留了老版本的日志收集方式,并将全新的 Logging Operator 作为实验性功能使用;SUSE Rancher 2.6 版本则已经完全使用了 Logging Operator 作为日志收集工具。 本文将由浅到深地探索全新的 SUSE Rancher 2.6 Logging Operator 功能和它的使用方式。
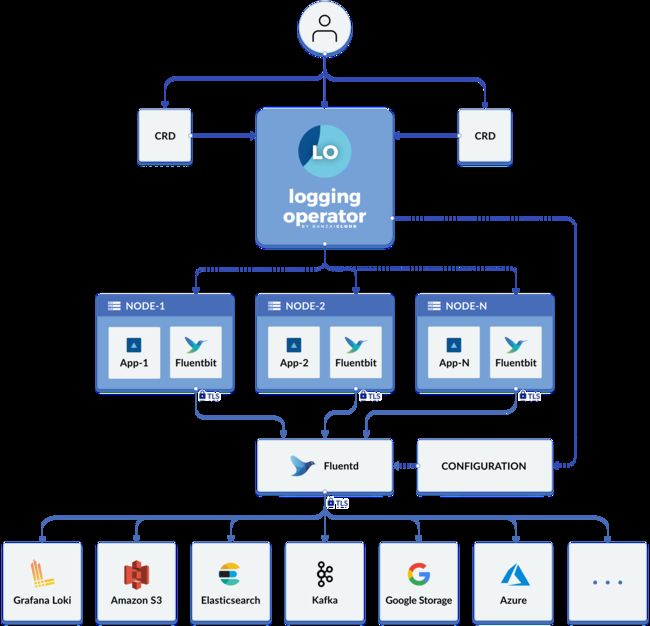
1、Logging Operator 工作原理
Logging Operator 自动部署和配置 Kubernetes 日志流水线。它会在每个节点上部署和配置一个 Fluent Bit DaemonSet,从而收集节点文件系统中的容器和应用程序日志。
Fluent Bit 查询 Kubernetes API 并使用 pod 的元数据来丰富日志,然后将日志和元数据都传输到 Fluentd。Fluentd 会接收和过滤日志并将日志传输到多个Output。
以下自定义资源用于定义了如何过滤日志并将日志发送到 Output:
Flow是一个命名空间自定义资源,它使用过滤器和选择器将日志消息路由到对应的Output。ClusterFlow用于路由集群级别的日志消息。Output是一个命名空间资源,用于定义发送日志消息的位置。ClusterOutput定义了一个所有Flow和ClusterFlow都可用的Output。
每个 Flow 都必须引用一个 Output,而每个 ClusterFlow 都必须引用一个 ClusterOutput。
2、启用 Logging
使用RKE2创建kubernetes集群后,使用helm部署rancher是服务,登录rancher 2.7 UI,可以在集群工具页面找到 Logging 工具的部署入口,如下图所示:


点击安装按钮后,选择组件安装的项目,一般选择为 System 项目,在该项目中运行与集群运行相关的组件;点击下一步后,UI 会要求输入配置 Docker 根目录和 System Log Path;
- 注意:如果底层容器运行时 (Runtime)为 container,默认为:/run/log/journal。如果自定义过,请填写正确的 Docker Root Dir 目录,可以通过 docker info | grep Docker Root Dir 命令查看;
- 注意:System Log Path 用于收集主机操作系统 Journal 日志,如果填写错误会导致主机操作系统日志无法收集,确认该路径的方法如下:
## 确认Journal Log Path检查方式,在节点上执行以下命令
cat /etc/systemd/journald.conf | grep -E ^\#?Storage | cut -d"=" -f2
1、如果返回persistent,则systemdLogPath应该是/var/log/journal;
2、如果返回volatile,则systemdLogPath应该是/run/log/journal;
3、如果返回auto,则检查/var/log/journal是否存在;
- 如果/var/log/journal存在,则使用/var/log/journal;
- 如果/var/log/journal不存在,则使用/run/log/journal;
输入正确的 Docker 根目录和 systemdLogPath 后,点击安装,SUSE Rancher 2.6 会自动部署 Logging Operator
执行以下命令检查部署是否成功
14:46 root@k8s-rke2-worker01:~
$kubectl get pod -n cattle-logging-system
NAME READY STATUS RESTARTS AGE
rancher-logging-597664d885-nrj2h 1/1 Running 0 44h
rancher-logging-root-fluentbit-48psd 1/1 Running 0 44h
rancher-logging-root-fluentbit-7lxn2 1/1 Running 0 51m
rancher-logging-root-fluentbit-7mn8n 1/1 Running 1 (7m28s ago) 23m
rancher-logging-root-fluentbit-fnvdg 1/1 Running 0 44h
rancher-logging-root-fluentbit-nf7c2 1/1 Running 0 44h
rancher-logging-root-fluentbit-x5x7x 1/1 Running 0 44h
rancher-logging-root-fluentd-0 2/2 Running 0 44h
rancher-logging-root-fluentd-configcheck-ac2d4553 0/1 Completed 0 44h
15:37 root@k8s-rke2-worker01:~
部署完成后,SUSE Rancher 2.6 集群 UI 上多了一个日志选项卡,可以由此配置上文提到的 flow、clusterflow、output、clusteroutput 资源对象,从而完成整个日志采集、过滤路由、输出的全流程配置。
3、CRD方式配置
从 Rancher 2.7 UI 上直接进行日志采集流程的配置固然方便,但是对 Logging Operator 比较熟悉的“大神”或者经常使用的“大佬”,可以使用 Rancher 2.7 UI 直接进行配置,从而完成整个日志采集、过滤路由、输出的全流程配置;对于刚刚升级为 Rancher 2.7 或者刚刚接触 Logging Operator 的“小白”朋友们,咱们还是不要着急上手了,深入浅出、循序渐进,继续往下读完,看看这些 CRD 是怎么配置和工作的。
Flow 和 ClusterFlow
整个 Logging Operator 最为核心的两个概念就是 flow 和 output,其中 flow 就是用来处理日志流的,决定了从哪里采集、怎么过滤、如何路由分发;clusterflow 具有相同的功能,是个全局 flow。
在了解 flow CRD 的定义之前,先用一个简单的 flow 示例来进行以下分析:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name} ##在fluentd里面使用${namespace_name}.${pod_name}.${container_name}的格式
localOutputRefs:
- "elasticsearch-output" ## 定义Output
match: ## Kubernetes标签来定义哪些日志需要被采集
- select:
labels: ## 使用标签匹配采集日志
app: nginx
这个 flow 的意思是,只会采集 default 命名空间内标签 app=nginx 的容器日志,采集日志后按照 nginx 格式进行解析,并且将这个日志流的 tag 在 fluentd 最终汇总时重定向为
${namespace_name}.${pod_name}.${container_name}
格式。
match
上面的例子里有一个非常重要的定义 match,它定义了哪些日志需要被采集,根据 Logging Operato 官方文档给出的说明,当前可以使用的字段有以下几种:
- namespaces 使用命名空间进行匹配;
- labels 使用标签进行匹配;
- hosts 使用主机进行匹配;
- container_names 使用容器名称进行匹配。
设想一个场景,在一个 Kubernetes 集群中,我们只想不采集某些容器的日志,使用匹配需要写无数个匹配规则,这显然是不合理的,所以官方给了 exclude 字段,使用排除。例子如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name} ##在fluentd里面使用${namespace_name}.${pod_name}.${container_name}的格式
localOutputRefs:
- "es-output" ## 定义Output
match: ## Kubernetes标签来定义哪些日志需要被采集
- exclude: ##排除所有标签是app:nginx的容器
labels:
app: nginx
上面这个例子会排除采集所有标签是 app:nginx 的容器日志;exclude 和 select 可以同时存在,也可以有多个 exclude 和 select 存在,更灵活的定义需要采集哪些容器日志。
除了 flow 以外还有 clusterflow。设想一个场景,我们有 N 个 namespaces,但是我们需要采集除了某一个 namespaces 以外的所有 namespaces 的容器日志。这个时候,每个 namespaces 设定一条 flow 明显是不合理的,这就需要使用 clusterflow 设置规则来进行采集,示例如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow ##定义为clusterflow
metadata:
name: default-cluster-flow
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name} ##在fluentd里面使用${namespace_name}.${pod_name}.${container_name}的格式
localOutputRefs:
- "es-output" ## 定义Output
match: ## Kubernetes标签来定义哪些日志需要被采集
- exclude: ##排除不想要采集的namespaces
namespaces:
- default
- kube-system
上面的示例表示这是一个 cluster 级别的 flow,根据 match 定义,将采集除了 default 和 kube-system 命名空间以外的所有命名空间日志;与 flow 相同的是, clusterflow 中的 match 定义的 exclude 和 select 可以同时存在,也可以有多个 exclude 和 select 同时存在,从而制定更细致的规则。
filters
filters 是 Logging Operator 中的日志处理插件,目前官方支持的日志处理插件如下:
- Concat: 用于 fluentd 处理日志多行的插件;
- Dedot: 处理带.的字段替换插件,通常用于输出到 elaticsearch 前的字段转化;
- Exception Detector: Exception 日志捕获器,支持 java, js, csharp, python, go, ruby, php;
- Enhance K8s Metadata: banzaicloud 开发的 k8s 扩展元数据;
- Geo IP: fluentd 的 GeoIP 地址库;
- Grep: fluentd 的 grep 过滤器;
- Parser: fluentd 的 Parser 解析器,parse 支持 apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none;
- Prometheus: Prometheus 插件,可用于对日志做计数;
- Record Modifier: fluentd 字段修改插件;
- Record Transformer: Mutates/transforms incoming event streams;
- Stdout: 标准输出插件;
- SumoLogic: Sumo Logic 公司的日志处理插件;
- Tag Normaliser: fluentd 中的 tag 修改器。
Parser 插件
Parser 插件最常用、最简单,支持解析持 apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none 格式的日志。如果需要解析 nginx 的日志,可以直接用 Parser 插件进行处理,示例如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-nginx-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
如果需要解析 json 格式的日志,示例如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse:
type: json ##解析为json格式
time_key: time ##自定义key
time_format: "%Y-%m-%dT%H:%M:%S"
我们可以在Parser插件指定多种类型的日志解析格式,示例如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse:
type: multi_format
patterns:
- format: nginx ##解析Nginx格式
- format: json ##解析json格式
time_key: time
time_format: "%Y-%m-%dT%H:%M:%S"
从上面的几个例子可以看出来,处理解析日志格式是非常灵活的,可以搭配不同的插件和解析格式来应对不同类型的日志格式。
介绍完常用的 Parser 插件后,再给大家介绍一个以往可能都没有遇到过或者配置起来比较复杂的场景:如果需要统计业务日志在一定时间段内打印了多少总数,用于分析业务运营指标,怎么办呢?可能大家第一时间想到的是,反正都已经处理完丢到类似 Kibana 的工具上了,直接过滤一下不就出数据了?这个方法是可以的,但是假设一下,想要通过日志条目数量持续分析业务运营指标怎么办?接下来分享另外一个插件。
Prometheus 插件
Prometheus 作为云原生时代的监控利器,强大的时序型数据库,配合 PromQL 和 Grafana 还有众多的Exporter,基本可以监控我们需要的任何指标;Logging Operator 中也引入了 Prometheus 插件,用于统计暴露收集的指定日志条目。示例如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
- prometheus: ##Pormetheus插件
metrics:
- desc: The total number of nginx in log. ##指标说明
name: nginx_log_total_counter ##指标名称
type: counter ##指标Prometheus类型
labels: ## 指标标签
app: nginx
labels: ##指标标签
host: ${hostname}
tag: ${tag}
namespace: $.kubernetes.namespaces
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name} ##在fluentd里面使用${namespace_name}.${pod_name}.${container_name}的格式
localOutputRefs:
- "es-output" ## 定义Output
match: ## Kubernetes标签来定义哪些日志需要被采集
- select:
labels: ## 使用标签匹配采集日志
app: nginx
以上例子使用了 Parser 插件对 Nginx 日志进行处理,使用了 Prometheus 插件对输出的 Nginx 日志进行统计。Prometheus 插件主要有以下几个字段:
- desc: 对该指标的描述;
- name: 指标的名称;
- type: 指标的 Prometheus 数据类型(了解更多请参考 Prometheus 数据类型文档);
- labels: 指标的标签(了解更多请参考 Prometheus Label 文档)。
通过上面这个 Flow 就可以统计总共处理了多少行 Nginx 的日志,并使用 Prometheus 暴露 counter 类型指标以做监控分析。
小结
通过以上两个插件的使用示例可以看出 Logging Operator 的灵活、强大之处,此外,您还可以配合其他众多的插件,灵活地完成对日志采集处理的需求。关于更多 Logging Operator 的 filter 支持的插件说明,请查看 banzaicloud.com/docs/one-ey…
Output 和 ClusterOutput
Output 和 ClusterOutput 两个 CRD 定义了处理完成的日志应该输出到哪个地方。与 flow 和 clusterflow 相同的是,output 同样是 namespaces 级别的,它只能被同命名空间下的 flow 引用;clusterflow 是集群级别的,可以被不同命名空间的 flow 和 clusterflow 引用。
Output
Output 定义了日志的输出方式,目前 Logging Operator 支持输出插件如下:
- Alibaba Cloud
- Amazon CloudWatch
- Amazon Elasticsearch
- Amzon Kinesis
- Amazon S3
- Amzon Storage
- Buffer
- Datadog
- Elasticsearch
- File
- Format
- Format rfc5424
- Forward
- GELF
- Goole Cloud Storage
- Grafana Loki
- Http
- Kafka
- LogDNA
- LogZ
- NewRelic
- Splunk
- SumoLogic
- Syslog
可以看到 Logging Operator 支持输出的插件还是非常丰富的,基本上涵盖了使用场景中的工具。下面我们将以常用的两种插件 Kafka 和 Elasticsearch 进行举例,配置 Output CRD。
Output-Kafka
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: kafka-output
spec:
kafka:
brokers: kafka-headless.kafka.svc.cluster.local:29092 ##kafka地址
default_topic: topic
topic_key: kafka-output ##kafka topic名称;
sasl_over_ssl: false ##是否使用ssl
format:
type: json ##类型
buffer: ##发送buff配置
tags: topic
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
在上面这个简单例子中,我们定义了一个输出到 kafka 的 output CRD,可以看到几个关键配置,kafka 的地址、topic 的名称、是否使用 ssl;下面的 buffer指发送 buffer 配置,这样一个发送到 kafka 的 output CRD 就完成了。Buff 配置也可以根据实际情况进行调整。
Output-Elasticsearch
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: elasticsearch-output
spec:
elasticsearch:
host: elasticsearch-elasticsearch-cluster.default.svc.cluster.local
port: 9200
scheme: https
ssl_verify: false
ssl_version: TLSv1_2
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
在上面这个简单例子中,我们定义了一个输出到 elasticsearch 的 output CRD,其实和 kafka的 output 配置类似,需要定义 elasticsearch 的地址、端口、是否需要 ssl 认证;buffer 配置定义了发送时的 buff 配置。
关于更多配置项,查看文档:banzaicloud.com/docs/one-ey…
flow 和 output 相关联
在定义好了 flow 和 output 之后,需要在 flow 定义 localOutputRefs 来与 output 进行关联,以进行日志的发送处理。示例如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name} ##在fluentd里面使用${namespace_name}.${pod_name}.${container_name}的格式
localOutputRefs:
- "elasticsearch-output" ## 输出到elasticsearch-output
match: ## Kubernetes标签来定义哪些日志需要被采集
- select:
labels: ## 使用标签匹配采集日志
app: nginx
在上面这个例子中,localOutputRefs 配置了 elasticsearch-output,这样就与我们刚刚定义的名称为 elasticsearch-output 的 output 进行了关联,日志就可以从指定的 output 进行输出。值得一提的是,Logging Operator 充分考虑了相同日志需要输出到不同地点的需求。比如下面这个例子,就可以将日志同时输出到 kafka 和 elasticsearch:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default-flow
namespace: default ##定义收集日志的命名空间
spec:
filters: ##定义过滤器,一个flow可以定义一个或者多个
- parser:
remove_key_name_field: true
parse: ##parse支持apache2, apache_error, nginx, syslog, csv, tsv, ltsv, json, multiline, none, logfmt类型解析
type: nginx ##采集日志按照Nginx格式进行处理
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name} ##在fluentd里面使用${namespace_name}.${pod_name}.${container_name}的格式
localOutputRefs:
- "elasticsearch-output" ## 输出到elasticsearch-output
- "kafka-output" ##输出到kafka-output
match: ## Kubernetes标签来定义哪些日志需要被采集
- select:
labels: ## 使用标签匹配采集日志
app: nginx
小结
上文介绍的 flow、clusterflow 和 output、clusteroptput 功能都是灵活而强大的。在 SUSE Rancher 2.6 版本部署完 Logging 后,可以通过 yaml 编写 CRD 并直接应用到集群中,也可以直接在 SUSE Rancher UI 上进行配置。下一章将会介绍如何在 SUSE Rancher UI 上对 flow 和 output 进行配置。
4、在 Rancher UI 上对 flow 和 output 进行配置
本章节内容将会描述在 SUSE Rancher UI 上进行日志采集配置。
创建 outputs/clusteroutputs
在 SUSE Rancher UI 上配置首先需要创建一个 flow 或者 clusterflow,进入日志页面选择 outputs/clusteroutputs,选择将要发送的后端工具,示例中以 es 为例,配置索引名称、主机地址、端口、outputs 名称,如果有 https 或者 ssl 需要先创建 secrets。
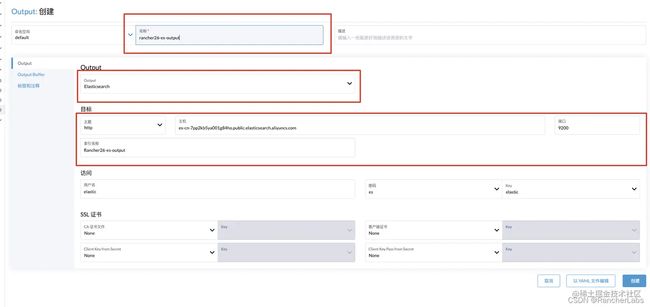
创建完成后的 CRD yaml 如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: rancher26-es-output
namespace: default
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_use_utc: true
timekey_wait: 30s
host: 172.16.0.14
index_name: rancher26
port: 9200
scheme: http
创建 flow/clusterflow
Outputs 创建完成之后,开始创建 flow/clusterflow 规则:进入日志页面选择 flows/clusterflows,点击创建,进行 flow 配置,示例中将采集标签为 app:nginx 的容器日志:
- 输入容器标签匹配规则、名称;如果有不想采集的主机或者容器,也可以进行选择;页面上也可以添加多个标签匹配规则;

- 配置输出规则,这里选择我们刚刚创建的 outputs,这里可以选择多个 outputs 和 clusteroutput,也可以同时选择 output 和 clusteroptput;
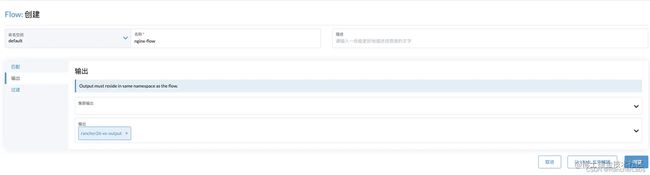
- 配置过滤规则,这里我们收集的是 nginx 日志,所以使用 parser 插件,自动格式化 nginx 规则;
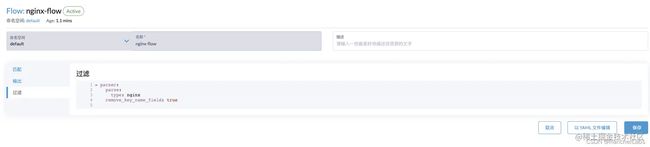
创建完成后的 CRD yaml 如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: nginx-flow
namespace: default
fields:
- nginx-flow
spec:
filters:
parser:
parse:
type: nginx
remove_key_name_field: true
localOutputRefs:
- rancher26-es-output
match:
- select:
labels:
app: nginx
验证
配置完成后,如果集群中有符合标签要求的容器,就会自动采集并发送到 es;
- 通过查看 fluentd 的配置,可以查看 outputs 是否生效
## 进入rancher-logging-fluentd-0 Pod命令行
cat fluentd/app-config/fluentd.conf
<match **>
@type elasticsearch
@id flow:default:nginx-flow:output:default:rancher26-es-output
exception_backup true
fail_on_putting_template_retry_exceed true
host 172.16.0.14
index_name rancher26
port 9200
reload_connections true
scheme http
ssl_verify true
utc_index true
verify_es_version_at_startup true
<buffer tag,time>
@type file
chunk_limit_size 8MB
path /buffers/flow:default:nginx-flow:output:default:rancher26-es-output.*.buffer
retry_forever true
timekey 1m
timekey_use_utc true
timekey_wait 30s
</buffer>
</match>
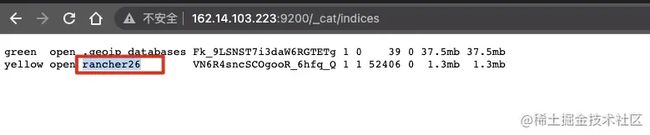
- 查看 elasticsearch 中的索引
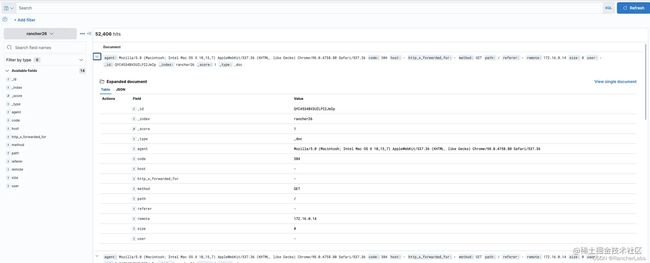
- 查看 kibana 中的日志详情
总结
至此,Rancher 2.7 全新的 Logging Operator 开箱使用就已经全部结束了。对比之前的日志收集功能,的确强大了不少,配置非常灵活,可以自定义多种过滤器,甚至使用 Prometheus 暴露自定义指标进行业务运营分析等内容。但是与之前只需要输入目标端地址就能使用的场景相对比,Logging Operator 确实也增加了一定的学习成本,建议“小白”朋友还是从零开始学习,搞清楚整体的运行架构和逻辑,这样有助于故障发生时的定位排查。
一些 Tips
- 整体架构是由 Daemonst 类型的 fluentbit 组件进行日志采集,fluentbit 组件日志中会有日志文件的打印输出,当发现某些日志未被采集的时候,可以查看 fluentbit 组件的日志是否发现了这些日志;
- Fluentd 组件负责汇总、处理、发送,当发现目标端没有收到日志,比如说 ES 没有创建索引的时候,可以看看 Fluentd 组件的日志。需要注意的是,截止文章发表时,Fluentd 的日志没有打印在标准输出中,需要进入 Pod 内执行命令查看:
tail -f fluentd/log/out
- 无论是 UI 还是 CRD 的 flow/outputs 配置,最终都会转化为 fluentbit 和 Fluentd 的配置,如果对这两个组件比较熟悉,出现异常的时候可以进入 Pod 中查看具体生效的配置是否正确;
- 由于过滤器的存在,错误的过滤、匹配的条件可能会导致日志无法发送出去,这个时候需要检查 flow 中配置的规则情况。
参考:https://ranchermanager.docs.rancher.com/zh/v2.7/integrations-in-rancher/logging/logging-architecture
https://www.bookstack.cn/read/rancher-2.7-zh/1ae3d0b742922109.md