SRE 原则指南
站点可靠性工程 (SRE) 是一门构建自动化软件系统来管理产品或服务的开发运营 (DevOps) 的学科。换句话说,SRE 通过软件系统自动化运营团队的功能。
SRE 的主要目的是鼓励大规模系统的部署和正确维护。特别是,站点可靠性工程师负责确保给定系统的行为始终满足性能和可用性的业务要求。
此外,虽然传统的运营团队和开发团队往往有相反的激励措施,但站点可靠性工程师能够调整激励措施,从而同时促进功能开发和可靠性。
SRE 基本原则
本文介绍了 SRE 的关键原则,提供了这些关键原则的一些示例,并包括相关细节和插图来阐明这些示例。
| 原则 | 描述 | 例子 |
|---|---|---|
| 拥抱风险 | 任何系统都不能指望具有完美的性能。识别潜在的故障点并制定缓解计划非常重要。此外,预算一定比例的业务成本来实时解决这些故障也很重要。 | 一周包括 168 小时的潜在可用时间。该企业预计每周正常运行时间为 165 小时,以应对计划内维护和计划外故障。 |
| 设定服务级别目标 (SLO) | 对系统性能设定合理的期望,以确保客户和内部利益相关者了解系统在各个级别上应如何执行。请记住,没有任何系统可以期望具有完美的性能。 |
|
| 通过自动化消除工作 | 自动化尽可能多的任务和流程。工程师应该专注于开发新功能和增强现有系统,至少与解决实时故障一样频繁。 | 只要违反 SLO,生产代码就会自动生成警报。自动警报将票证发送给相应的事件响应团队以及相关的行动手册以采取行动。 |
| 监控系统 | 使用工具来监控系统性能。观察绩效、事件和趋势。 |
|
| 保持简单 | 频繁发布可轻松恢复的小更改,以最大程度地减少生产错误。删除不必要的代码,而不是保留它以供将来使用。引入的代码和系统越多,产生的复杂性就越大;防止意外膨胀很重要。 | 代码的更改始终通过版本控制系统推送,该系统跟踪代码编写者、审批者和之前的状态。 |
| 概述发布工程流程 | 记录您已建立的开发、测试、自动化、部署和生产支持流程。确保该流程可访问且可见。 | 已发布的剧本列出了解决重启失败的步骤。该手册包含对相关 SLO、仪表板、以前的票证、代码库部分以及事件响应团队的联系信息的引用。 |
拥抱风险
任何系统都不能指望具有完美的性能。为内部利益相关者和外部用户创建对系统性能的合理期望非常重要。
关键指标
对于直接面向用户的服务,例如静态网站和流媒体,衡量性能的两种常见且重要的方法是时间可用性和聚合可用性。

本文提供了计算服务的时间可用性的示例。
对于其他服务,其他因素也很重要,包括速度(延迟)、准确性(正确性)和容量(吞吐量)。

延迟计算示例如下:
-
假设 10 个不同的用户向您的网站提供相同的 HTTP 请求,并且它们都得到了正确的处理。
-
返回时间的监控和记录如下:1 ms、3 ms、3 ms、4 ms、1 ms、1 ms、1 ms、5 ms、3 ms 和 2 ms。
-
平均响应时间或延迟为 24 毫秒 / 10 个返回 = 2.4 毫秒。
选择关键指标可以明确如何评估服务的性能,从而明确哪些因素会对服务健康构成风险。在上面的示例中,将延迟确定为关键指标表明平均返回时间是服务的基本属性。因此,服务可靠性的风险是“缓慢”或低延迟。
定义失败
除了衡量风险之外,明确定义系统在不影响质量的情况下可以承受哪些风险以及必须解决哪些风险以确保质量也很重要。
本文提供了解决故障问题的两种测量类型的示例:平均无故障时间 (MTTF) 和平均故障间隔时间 (MTBF)。
定义故障的最可靠方法是设置 SLO,监视服务是否违反 SLO,并创建警报和流程来修复违规行为。这些将在以下各节中讨论。
错误预算
新生产功能的开发总是会带来新的潜在风险和故障;追求 100% 无风险的服务是不现实的。协调推动开发和维护可靠性的竞争激励的方法是通过错误预算。
错误预算提供了一个明确的指标,允许在给定的计划周期内新版本出现一定比例的失败。如果故障的数量或长度超出了错误预算,则在新的计划期开始之前不会出现新的版本。
以下是错误预算示例。
| 规划周期 | 四分之一 |
| 总可能的可用性 | 2,190 小时 |
| 斯洛伐克 | 99.9% 的时间可用性 |
| 错误预算 | 0.1% 可用时间 = 21.9 小时 |
假设开发团队计划在本季度发布 10 个新功能,并且发生以下情况:
-
第一个功能不会导致任何停机。
-
第二个功能会导致 10 个小时的停机时间直至修复。
-
第三和第四个功能均会导致 6 小时的停机时间直至修复。
-
此时,已经超出了该季度的错误预算(10 + 6 + 6 = 22 > 21.9),因此第五个功能无法发布。
通过这种方式,错误预算确保了可接受的功能发布速度,同时不会影响可靠性或降低用户体验。
设定服务级别目标 (SLO)
设定绩效预期的最佳方法是针对不同的系统风险设定具体的目标。这些目标称为服务级别目标或 SLO。下表列出了基于不同风险衡量的 SLO 示例。
| 时间安排 | 网站99%的时间都在运行 |
| 总可用性 | 99% 的用户请求得到处理 |
| 潜伏 | 每个请求的平均响应率为 1 毫秒 |
| 吞吐量 | 每秒处理 10,000 个请求 |
| 正确性 | 99% 的数据库读取准确率 |
根据服务的不同,某些 SLO 可能比单个数字更复杂。例如,数据库在读取时可能表现出 99.9% 的正确性,但其产生的 0.1% 的错误始终与最新数据相关。如果客户严重依赖过去 24 小时记录的数据,那么服务就不可靠。在这种情况下,根据客户的需求创建分层 SLO是有意义的。这是一个例子:
| 1级(最近24小时内的记录) | 99.99% 读取准确度 |
| 2级(最近7天内的记录) | 99.9% 读取准确度 |
| 3级(最近30天内的记录) | 99% 读取准确度 |
| 4级(最近6个月内的记录) | 95% 读取准确度 |
改进成本
建立 SLO 的主要目的之一是跟踪可靠性如何影响收入。重新审视上一节中的示例错误预算,假设该季度的预计服务收入为 500,000 美元。这可用于将 SLO 和错误预算转换为实际金额。因此,SLO 也是衡量与系统性能间接相关的目标的一种方法。
| 斯洛伐克 | 错误预算 | 收入损失 |
|---|---|---|
| 95% | 5% | 25,000 美元 |
| 99% | 1% | 5,000 美元 |
| 99.90% | 0.10% | 500 美元 |
| 99.99% | 0.01% | 50 美元 |
使用 SLO 跟踪间接指标(例如收入)可以评估改进服务的成本。在这种情况下,花费 10,000 美元将 SLO 从 95% 提高到 99% 是一个值得的商业决策。另一方面,花费 10,000 美元将 SLO 从 99% 提高到 99.9% 则不然。
通过自动化消除工作
SRE 与传统 DevOps 的区别之一是能够在不降低服务成本的情况下扩大服务范围。这称为次线性增长,这是通过自动化实现的。
在传统的开发-运营分离中,开发团队推出新功能,而运营团队将 100% 的时间用于维护。因此,一个纯粹的运营团队需要按照其所维护的服务的规模和范围以 1:1 的比例增长:如果需要 O(10) 系统工程师来服务 1000 个用户,那么需要 O(100) 工程师来服务 10K用户。

相比之下,根据最佳实践运营的 SRE 团队将投入至少 50% 的时间来开发系统,以消除运营工作负载中的基本工作要素。以下是一些例子:
-
一项服务,用于检测大型机群中的哪些机器需要软件更新,并定期按批次安排软件重新启动。
-
“push-on-green”模块提供自动工作流程,用于测试新代码并将其发布到相关服务。
-
一个警报系统,可自动生成票证并通知事件响应团队。
监控系统
为了保持可靠性,必须监控服务的相关分析并使用监控来检测 SLO 违规情况。如前所述,一些重要指标包括:
-
服务启动并运行的时间量(时间可用性)
-
成功完成的请求数(聚合可用性)
-
处理请求所需的时间(延迟)
-
提供预期结果的响应比例(正确性)
-
系统当前正在处理的请求量(吞吐量)
-
消耗的可用资源的百分比(饱和度)
有时也会测量耐久性,即数据准确存储的时间长度。
仪表板
实施监控的一个好方法是通过仪表板。有效的仪表板将显示 SLO,包括错误预算,并显示与 SLO 相关的不同风险指标。
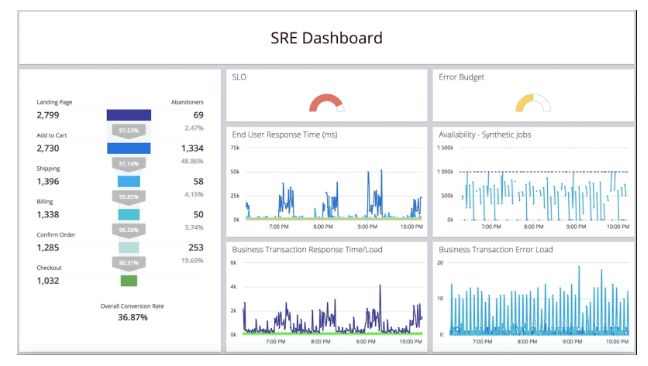
有效的 SRE 仪表板示例
日志
实现监控的另一个好方法是通过日志。既可以及时搜索又可以根据请求分类的日志是最有效的。如果通过仪表板检测到 SLO 违规,则可以通过查看受影响时间范围内生成的日志来创建更详细的情况。
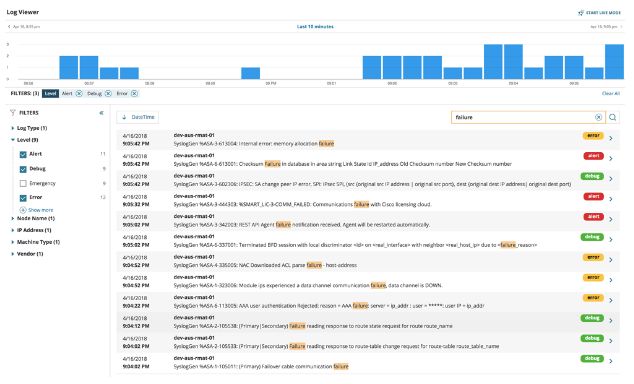
监控日志示例
白盒与黑盒
上面讨论的跟踪服务内部分析的监控类型称为白盒监控。有时,从“外部”监控系统的行为也很重要,这意味着从外部用户的角度测试服务的工作流程;这称为黑盒监控。黑盒监控可能会揭示访问权限或冗余的问题。
自动警报和票务
SRE 减少工作量的最佳方法之一是在监控警报和票务期间使用自动化。SRE 流程比传统运营流程高效得多。
传统的操作响应可能如下所示:
-
网络开发人员推出了向用户投放广告的算法的新更新。
-
开发人员注意到,由于未知原因,最新的推送正在减少网站流量,因此向网络运营团队手动提交了有关流量减少的票证。
-
Web 运营团队的系统工程师收到了有关流量减少问题的通知单。排除故障后,问题被诊断为缓存卡住导致的延迟问题。
-
Web 运营工程师联系数据库团队的成员寻求帮助。数据库团队研究代码库并确定缓存设置的修复程序,以便更快地刷新数据并减少延迟。
-
数据库团队更新缓存刷新设置,将修复推送到生产环境,并关闭票证。
相反,SRE 操作响应可能如下所示:
-
广告 SRE 团队创建了一个部署工具,用于监控三种不同的流量 SLO:可用性、延迟和吞吐量。
-
一位 Web 开发人员准备向服务广告的算法推送新的更新,为此他使用了 SRE 部署工具。
-
几分钟之内,部署工具就检测到网站流量减少。它可以识别延迟 SLO 违规并创建警报。
-
值班站点可靠性工程师收到警报,其中包含更新缓存刷新设置的建议,以加快处理请求的速度。
-
站点可靠性工程师接受建议的更改,将新设置推送到生产中,并关闭票证。
通过使用自动化系统来警告和建议对数据库进行更改,所需的通信、涉及的人员数量以及解决问题的时间都减少了。
以下代码块是延迟和吞吐量阈值以及检测到违规时触发的自动警报的通用语言实现。
# Define the latency SLO threshold in seconds and create a histogram to track
LATENCY_SLO_THRESHOLD = 0.1
REQUEST_LATENCY = Histogram('http_request_latency_seconds', 'Request latency in seconds', ['method', 'endpoint'])
# Define the throughput SLO threshold in requests per second and a counter to track
THROUGHPUT_SLO_THRESHOLD = 10000
REQUEST_COUNT = Counter('http_request_count', 'Request count', ['method', 'endpoint', 'http_status'])
# Check if the latency SLO is violated and send an alert if it is
def check_latency_slo():
latency = REQUEST_LATENCY.observe(0.1).observe(0.2).observe(0.3).observe(0.4).observe(0.5).observe(0.6).observe(0.7).observe(0.8).observe(0.9).observe(1.0)
quantiles = latency.quantiles(0.99)
latency_99th_percentile = quantiles[0]
if latency_99th_percentile > LATENCY_SLO_THRESHOLD:
printf("Latency SLO violated! 99th percentile response time is {latency_99th_percentile} seconds.")
# Check if the throughput SLO is violated and send an alert if it is
def check_throughput_slo():
request_count = REQUEST_COUNT.count()
current_throughput = request_count / time.time()
if current_throughput > THROUGHPUT_SLO_THRESHOLD:
printf("Throughput SLO violated! Current throughput is {current_throughput} requests per second.")保持事情简单
确保系统保持可靠性的最佳方法是保持系统简单。SRE 团队应该对添加新代码犹豫不决,而宁愿在可能的情况下修改和删除代码。添加到生产软件中的每一个附加 API、库和功能都会以难以跟踪的方式增加依赖性,从而引入新的故障点。
站点可靠性工程师应该致力于保持代码模块化。也就是说,API 中的每个函数都应该只服务于一个目的,就像更大堆栈中的每个 API 一样。这种类型的组织使依赖关系更加透明,也使诊断错误变得更加容易。
剧本
作为事件管理的一部分,应公开编写和发布典型待命调查和解决方案的手册。针对特定场景的剧本应描述事件(以及可能的变化),列出相关的 SLO,引用适当的监控工具和代码库,提供建议的解决方案,并对以前的方法进行分类。
概述发布工程流程
正如 SRE 代码库应该强调简单性一样,SRE 发布过程也应该强调简单性。通过以下几个原则鼓励简单性:
-
更小的尺寸和更高的速度:不是大规模、不频繁的发布,而是以更高的频率发布较小的版本。这使得团队能够逐步观察系统行为的变化,并减少发生大型系统故障的可能性。
-
自助服务:SRE 团队应该完全拥有其发布流程,并且该流程应该有效自动化。这既消除了工作量,又鼓励小规模、高速的推动。
-
密封构建:构建新版本的过程应该是密封的或独立的。也就是说,构建过程必须锁定到现有工具(例如编译器)的已知版本,并且不依赖于外部工具。
版本控制
所有代码版本都应在版本控制系统内提交,以便在出现错误、冗余或无效代码时轻松恢复。
代码审查
提交版本的过程应该伴随着清晰可见的代码审查过程。基本更改可能不需要批准,而更复杂或有影响力的更改将需要其他站点可靠性工程师或技术主管的批准。
SRE 原则回顾
SRE 的主要原则是接受风险、设置 SLO、通过自动化消除工作、监控系统、保持简单以及概述发布工程流程。
拥抱风险涉及明确定义失败并设定错误预算。做到这一点的最佳方法是创建和实施 SLO,它直接跟踪系统性能,还有助于确定系统改进的潜在成本。适当的 SLO 取决于风险的衡量方式和客户的需求。实施 SLO 需要进行监控,通常通过仪表板和日志进行监控。
除了开发运营之外,站点可靠性工程师还专注于项目工作,这使得服务能够扩大范围和规模,同时保持低成本。这称为次线性增长,是通过自动化重复任务来实现的。自动发出警报的监控创建了简化的操作流程,从而提高了可靠性。
站点可靠性工程师应通过减少编写的代码量、鼓励模块化开发以及发布具有标准操作程序的手册来保持系统简单。SRE 发布流程应该是密封的,并使用版本控制和代码审查来推动小的、频繁的更改。
作者:Vishal Padghan
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。