SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】
笑小枫的专属目录
-
- 1. 项目背景
- 2. 什么是Lucene
- 3. 引入依赖,配置索引
-
- 3.1 引入Lucene依赖和分词器依赖
- 3.2 表结构和数据准备
- 3.3 创建索引
- 3.4 修改索引
- 3.5删除索引
- 4. 数据检索
-
- 4.1 基础搜索
- 4.2 一个关键词,在多个字段里面搜索
- 4.3 搜索结果高亮显示
- 4.4 分页检索
- 4.5多个关键词搜索
- 5. IK扩展词处理
- 6. 项目源码
1. 项目背景
同样,本文的出现,也是我的个人网站笑小枫搭建的过程中产生的,作为一个技术博客为主的网站,Mysql的搜索已经满足不了我的野心了,于是,我便瞄上了全文检索。最初,是打算直接使用比较熟悉的ES,但是考虑到部署ES额外的服务器资源开销,最后选择了Lucene,搭配IK分词器,直接在项目中整合。
2. 什么是Lucene
看看官网上的介绍吧~
Apache Lucene™ is a high-performance, full-featured search engine library written entirely in Java. It is a technology suitable for nearly any application that requires structured search, full-text search, faceting, nearest-neighbor search across high-dimensionality vectors, spell correction or query suggestions.
Apache Lucene is an open source project available for free download.
看不懂,翻译过来就是:
Apache Lucene™是一个完全用Java编写的高性能、全功能的搜索引擎库。它是一种几乎适用于任何需要结构化搜索、全文搜索、切面、跨高维向量的最近邻搜索、拼写纠正或查询建议的应用程序的技术。Apache Lucene是一个免费下载的开源项目。
没错,它就是我们需要的全文搜索引擎,接下来让我们一起看看怎么在SpringBoot项目中集成使用它吧。
3. 引入依赖,配置索引
3.1 引入Lucene依赖和分词器依赖
先看看需要的依赖吧。
算了,还是先说说我的需求吧,算了,没有需求,具体参考百度搜索框吧~反正就是那样
直接上依赖吧,默认分词器对中文不友好。这里使用IK分词器(不多介绍)
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>7.6.0version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>7.6.0version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-commonartifactId>
<version>7.6.0version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-highlighterartifactId>
<version>7.6.0version>
dependency>
<dependency>
<groupId>com.jianggujingroupId>
<artifactId>IKAnalyzer-luceneartifactId>
<version>8.0.0version>
dependency>
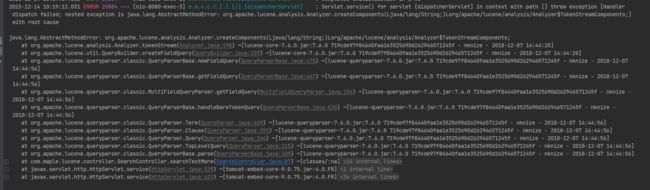
这里使用com.jianggujin:IKAnalyzer-lucene:8.0.0可以兼容新版本的lucene。
新版本的lucene和com.janeluo:ikanalyzer:2012_u6版本冲突,会报以下错误。
解决方案放在源码中了,这里不展开了。使用com.janeluo:ikanalyzer:2012_u6版本,把com.maple.lucene.util.MyIKAnalyzer和MyIKTokenizer的注释放开就行。
3.2 表结构和数据准备
准备表结构,这里是简化过的表结构,只提供演示效果。
CREATE TABLE `blog_title` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`title` VARCHAR(255) NOT NULL COMMENT '标题',
`description` VARCHAR(255) NULL DEFAULT NULL COMMENT '描述',
PRIMARY KEY (`id`) USING BTREE
)
COMMENT='博客标题' COLLATE='utf8_general_ci' ENGINE=InnoDB;
准备测试数据:
INSERT INTO `blog_title` (`id`, `title`, `description`) VALUES
(808, '0.SpringBoot目录', 'https://xiaoxiaofeng.com'),
(809, '1.SpringBoot项目创建', '大家好,我是笑小枫,跟我一起玩转SpringBoot项目吧,本文讲一下如何搭建SpringBoot项目。'),
(810, '10.SpringBoot处理请求跨域问题', 'CORS全称Cross-Origin Resource Sharing,意为跨域资源共享。当一个资源去访问另一个不同域名或者同域名不同端口的资源时,就会发出跨域请求。如果此时另一个资源不允许其进行跨域资源访问,那么访问就会遇到跨域问题。跨域指的是由于浏览器的安全性限制,不允许前端页面访问协议不同、域名不同、端口号不同的http接口。'),
(811, '11.SpringBoot接口日志信息统一记录', '为什么要记录接口日志?\n至于为什么,详细看到这里的小伙伴心里都有一个答案吧,我这里简单列一下常用的场景吧用户登录记录统计、重要增删改操作留痕、需要统计用户的访问次数、接口调用情况统计、线上问题排查、等等等...既然有这么多使用场景,那我们该怎么处理,总不能一条一条的去记录吧面试是不是老是被问Spring的Aop的使用场景,那这个典型的场景就来了,我们可以使用Spring的Aop,完美的实现这个功能,接下来上代码'),
(812, '12.SpringBoot导入Excel', '在java处理excel方便从简单的实现功能到自己封装工具类,一路走了好多,阿里的easyExcel对POI的封装更加精简这里介绍一下简单使用。'),
(813, '13.SpringBoot导出Excel', '在java处理excel方便从简单的实现功能到自己封装工具类,一路走了好多,阿里的easyExcel对POI的封装更加精简这里介绍一下简单使用。'),
(814, '14.SpringBoot发送邮件', '本文主要介绍了使用SpringBoot发送邮件,主要包含如何获取发送邮件的授权码,这里以QQ邮箱为例,然后介绍了功能如何实现,包括通过模板发送邮件,发送带图片的邮件,发送带附件的邮件,发送带有多个附件的邮件。'),
(815, '15.SpringBoot根据模板生成Word', '本文主要讲了SpringBoot基于模板的形式生成word的功能实现,感兴趣或有类似功能需求的小伙伴可以看一下,包括word模板制作,功能代码实现,支持导出图片、表格等功能。'),
(816, '16.SpringBoot生成PDF', '本文主要介绍了在SpringBoot项目下,通过代码和操作步骤,详细的介绍了如何操作PDF。希望可以帮助到准备通过JAVA操作PDF的你。\n本文涉及pdf操作,如下:\nPDF模板制作、 基于PDF模板生成,并支持下载、自定义中文字体、完全基于代码生成,并保存到指定目录、合并PDF,并保存到指定目录、合并PDF,并支持下载\n'),
(817, '17.SpringBoot文件上传下载', '在java开发中文件的上传、下载、删除功能肯定是很常见的,本文主要基于上传图片或文件到指定的位置展开,通过详细的代码和工具类,讲述java如何实现文件的上传、下载、删除。'),
(818, '18.SpringBoot中的Properties配置', 'springboot在使用过程中,我们有很多配置,比如mysql配置、redis配置、mybatis-plus、调用第三方的接口配置等等...\n\n我们现在都是放在一个大而全的配置里面的,如果我们想根据功能分为不同的配置文件管理,让配置更加清晰,应该怎么做呢?'),
(819, '19.使用Docker部署最佳实践', '使用Docker部署最佳实践'),
(820, '2.SpringBoot配置基于swagger2的knife4j接口文档', 'SpringBoot项目如果前后端分离,怎么把写好了的接口返回给前端的小伙伴呢,试试这款基于Swagger2的knife4j吧,简直好用到爆!'),
(821, '3.SpringBoot集成Mybatis Plus', '本文主要介绍了SpringBoot集成mysql数据库、集成Mybatis Plus框架;通过一个简单的例子演示了一下使用Mybatis Plus进行数据插入和查询;使用Knife4j进行接口调试;集成阿里巴巴Druid数据连接池;通过Druid页面进行执行sql查询、分析。'),
(822, '4.SpringBoot返回统一结果包装', '前后端分离的时代,如果没有统一的返回格式,给前端的结果各式各样,估计前端的小伙伴就要骂娘了。 \n我们想对自定义异常抛出指定的状态码排查错误,对系统的不可预知的异常抛出友好一点的异常信息。 \n我们想让接口统一返回一些额外的数据,例如接口执行的时间等等。 那就进来一起康康吧~......'),
(823, '5.SpringBoot返回统一异常处理', '如果程序抛异常了,我们是否也可以返回统一的格式呢?\n答案是,当然可以的,不光可以抛出我们想要的格式,还可以对指定的异常类型进行特殊处理\n例如使用@Validated对入参校验的异常,我们自定义的异常等等...'),
(824, '6.SpringBoot日志打印Logback详解', 'Logback 旨在作为流行的 log4j 项目的继承者,是SpringBoot内置的日志处理框架,spring-boot-starter其中包含了spring-boot-starter-logging,该依赖内容就是 Spring Boot 默认的日志框架 logback。这里给大家介绍一下在SpraingBoot中Logback的配置。'),
(825, '7.SpringBoot控制台自定义banner', '熬夜整理完logback相关的内容,突然发现我们的《笑小枫系列-玩转SpringBoot》已经6篇文章了,我们的配套程序居然没有一个属于自己的log,这简直说不过去了,我这处女座的小暴脾气,赶紧整一个,于是便有了此文。好了,接下来言归正传,毕竟本文也是属于我们系列的一份子嘛,不能落下'),
(826, '8.SpringBoot集成Redis', 'SpringBoot中怎么使用Redis做缓存机制呢?本文为大家揭开Redis的面纱,内容偏基础,但详细。本文核心:SpringBoot继承redis、SpringBoot常用的redis操作演示、监听Redis的key过期机制。'),
(827, '9.SpringBoot用户登录拦截器', '本文主要介绍了SpringBoot实现登录功能,使用JWT+Redis进行功能实现,从最基础的建表开始,详细的介绍了功能的实现。学习完本文,你将掌握登录功能的核心技能。'),
(832, '【笑小枫的按步照搬系列】JDK8下载安装配置', '本文主要讲解了JDK8在windows环境下的下载、安装、已经环境变量的配置,参照本文,你只需要按步照搬,便可快速的安装好JAVA环境。'),
(833, '【笑小枫的按步照搬系列】Maven环境配置', '本文主要介绍了maven的安装配置,包括配置本地仓库,配置阿里镜像等。安装maven环境之前要先安装java jdk环境(没有安装java环境的可以先去看安装JAVA环境的教程)Maven 3.3+ require JDK 1.7 及以上。'),
(834, '【笑小枫的按步照搬系列】Node.js安装', 'Node.js安装'),
(835, '【笑小枫的按步照搬系列】Redis可视化工具-RedisInsight', 'RedisInsight是Redis官方出品的可视化管理工具,可用于设计、开发、优化你的Redis应用。支持深色和浅色两种主题,界面非常炫酷!可支持String、Hash、Set、List、JSON等多种数据类型的管理,同时支持远程使用CLI功能,功能非常强大!'),
(836, '【笑小枫的按步照搬系列】Redis多系统安装(Windows、Linux、Ubuntu)', 'Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。本文主要讲述了Redis如何安装。'),
(837, '【笑小枫的按步照搬系列】开源的服务器远程工具-FinalShell', '之前一直使用 xshell + ftp 组合的方式来部署项目,后来发现了FinalShell 这款软件,瞬间就爱上了。FinalShell 相当于 xshell + ftp 的组合,即:FinalShell = xshell + ftp ;FinalShell 只用一个程序,将xshell 、ftp同屏显示,既可以输入命令,也可以传输数据,还能以树的形式展示文件路径。'),
(840, '【笑小枫的按步照搬系列】本地安装Mysql数据库', '本文主要介绍了在windows环境下如何下载安装mysql8+版本,你只需要按步照搬就可以完美解决你安装软件的困扰。本文主要包括mysql的下载、安装、配置my.ini文件、修改初始化密码等。'),
(841, '【笑小枫的按步照搬系列】版本控制工具git安装过程详解', 'Git 是个免费的开源分布式版本控制系统,下载地址为git-scm.com 或者 gitforwindows.org,本文介绍 Git-2.35.1.2-64-bit.exe 版本的安装方法,需要的小伙伴可以看一看。');
对数据库的操作使用的Mybatis Plus,这里演示比较简单,只是单纯的取数据,不贴详细代码了,需要的去源码里面获取。不想连数据库可以直接用个List模拟掉,简单的贴个对象吧。
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
*
* blog标题
*
*
* @author 笑小枫 3.3 创建索引
这里直接从数据库查询所有数据,然后创建索引了,只为演示,实际使用中根据数据量大小,业务需要哪些字段,是否需要回表查询等等考虑生产方案,钓无定法,技术多彩。
直接上代码了,索引建在d:\\indexDir目录下,实际使用该封装封装,该放配置放配置哈。这里为了演示效果好(方便你们copy),集中都放在这里了。 注释比较详细,不单独介绍功能了。
如果新增数据追加的话,使用conf.setOpenMode(IndexWriterConfig.OpenMode.APPEND);模式即可。
@GetMapping("/createIndex")
public String createIndex() {
List<BlogTitle> list = blogTitleMapper.selectList(Wrappers.lambdaQuery(BlogTitle.class));
// 创建文档的集合
Collection<Document> docs = new ArrayList<>();
for (BlogTitle blogTitle : list) {
// 创建文档对象
Document document = new Document();
// StringField: 这个 Field 用来构建一个字符串Field,不分析,会索引,Field.Store控制存储
// LongPoint、IntPoint 等类型存储数值类型的数据。会分析,会索引,不存储,如果想存储数据还需要使用 StoredField
// StoredField: 这个 Field 用来构建不同类型,不分析,不索引,会存储
// TextField: 如果是一个Reader, 会分析,会索引,,Field.Store控制存储
document.add(new StringField("id", String.valueOf(blogTitle.getId()), Field.Store.YES));
// Field.Store.YES, 将原始字段值存储在索引中。这对于短文本很有用,比如文档的标题,它应该与结果一起显示。
// 值以其原始形式存储,即在存储之前没有使用任何分析器。
document.add(new TextField("title", blogTitle.getTitle(), Field.Store.YES));
// Field.Store.NO,可以索引,分词,不将字段值存储在索引中。
// 个人理解:说白了就是为了省空间,如果回表查询,其实无所谓,如果不回表查询,需要展示就要保存,设为YES,无需展示,设为NO即可。
document.add(new TextField("description", blogTitle.getDescription(), Field.Store.NO));
docs.add(document);
}
// 引入IK分词器,如果需要解决上面版本冲突报错的问,使用`new MyIKAnalyzer()`即可
Analyzer analyzer = new IKAnalyzer();
// 索引写出工具的配置对象
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 索引目录类,指定索引在硬盘中的位置,我的设置为D盘的indexDir文件夹
// 创建索引的写出工具类。参数:索引的目录和配置信息
try (Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
IndexWriter indexWriter = new IndexWriter(directory, conf)) {
// 把文档集合交给IndexWriter
indexWriter.addDocuments(docs);
// 提交
indexWriter.commit();
} catch (Exception e) {
log.error("创建索引失败", e);
return "创建索引失败";
}
return "创建索引成功";
}
创建索引后,在d:\\indexDir目录下会出现索引文件,如下图

3.4 修改索引
数据变更时,索引应该怎么变更呢?该如何怎么设计呢?
- 在程序中数据变更的时候,更新索引,但是对业务的侵入性比较大。新增、修改、删除时都要多一套操作Lucene的接口。
- 监听数据库数据变更,然后更新索引,引入额外中间件,复杂度变高。
有舍有得吧,看权衡点在哪了,大家有什么好的方案可以留言哟。
@GetMapping("/updateIndex")
public String update() {
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(new IKAnalyzer());
// 创建目录对象
// 创建索引写出工具
try (Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
IndexWriter writer = new IndexWriter(directory, conf)) {
// 获取更新的数据,这里只是演示
BlogTitle blogTitle = blogTitleMapper.selectById("808");
// 创建新的文档数据
Document doc = new Document();
doc.add(new StringField("id", "808", Field.Store.YES));
doc.add(new TextField("title", blogTitle.getTitle(), Field.Store.YES));
doc.add(new TextField("description", blogTitle.getDescription(), Field.Store.YES));
writer.updateDocument(new Term("id", "808"), doc);
// 提交
writer.commit();
} catch (Exception e) {
log.error("更新索引失败", e);
return "更新索引失败";
}
return "更新索引成功";
}
修改前搜索
然后将id=808的title修改为0.SpringBoot不是目录,更新索引。可以看到数据已变更,但是分词查询,数据仍然查询出来了。

3.5删除索引
@GetMapping("/deleteIndex")
public String deleteIndex() {
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(new IKAnalyzer());
// 创建目录对象
// 创建索引写出工具
try (Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
IndexWriter writer = new IndexWriter(directory, conf)) {
// 根据词条进行删除
writer.deleteDocuments(new Term("id", "808"));
// 提交
writer.commit();
} catch (Exception e) {
log.error("删除索引失败", e);
return "删除索引失败";
}
return "删除索引成功";
}
只能删除id=808的索引,然后再进行查询,可以看到数据消失了。

4. 数据检索
4.1 基础搜索
最基础的模糊搜索,功能不用文字解释了,写个sql的案例吧,很明显就能懂。
当然走Lucene支持分词检索,计算得分展示等等,只为了容易懂,不杠…
select * from blog_title where title like ('%#{title}%')
/**
* 简单搜索
*/
@RequestMapping("/searchText")
public List<BlogTitle> searchText(String text) throws IOException, ParseException {
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<BlogTitle> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docId = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docId);
BlogTitle content = blogTitleMapper.selectById(doc.get("id"));
list.add(content);
}
return list;
}
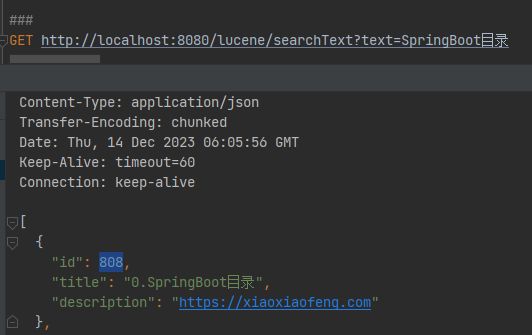
GET http://localhost:8080/lucene/searchText?text=笑小枫
可以看到 title 中包含笑小枫的数据都搜索出来了

4.2 一个关键词,在多个字段里面搜索
关键词在title和description两个字段里面检索,类似于下面的sql。
select * from blog_title where title like ('%#{searchPram}%') or description like ('%#{searchPram}%')
/**
* 一个关键词,在多个字段里面搜索
*/
@RequestMapping("/searchTextMore")
public List<BlogTitle> searchTextMore(String text) throws IOException, ParseException {
String[] str = {"title", "description"};
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new IKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 100);
// 获取总条数
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<BlogTitle> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docId = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docId);
BlogTitle content = blogTitleMapper.selectById(doc.get("id"));
list.add(content);
}
return list;
}
GET http://localhost:8080/lucene/searchTextMore?text=笑小枫
可以看到title和description中包含笑小枫的数据都搜索出来了

4.3 搜索结果高亮显示
这个功能基本必备吧,让用户明确知道搜索的匹配程度
/**
* 搜索结果高亮显示
*/
@RequestMapping("/searchTextHighlighter")
public List<BlogTitle> searchTextHighlighter(String text) throws IOException, ParseException, InvalidTokenOffsetsException {
String[] str = {"title", "description"};
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new IKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 100);
// 获取总条数
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
//高亮后的段落范围在100字内
Fragmenter fragmenter = new SimpleFragmenter(100);
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<BlogTitle> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docId = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docId);
BlogTitle content = blogTitleMapper.selectById(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new IKAnalyzer(), "title", doc.get("title"));
if (title == null) {
title = content.getTitle();
}
// 因为创建索引的时候description设置的Field.Store.NO,所以这里doc没有description数据,取不出来值,设为YES则可以,可以断点看一下,直接设置content.getDescription()也可以高亮显示
// String description = highlighter.getBestFragment(new IKAnalyzer(), "description", doc.get("description"));
// if (description == null) {
// description = content.getDescription();
// }
// content.setDescription(description);
content.setDescription(content.getDescription());
content.setTitle(title);
list.add(content);
}
return list;
}
GET http://localhost:8080/lucene/searchTextHighlighter?text=笑小枫
因为创建索引的时候description设置的Field.Store.NO,所以这里doc没有description数据,取不出来值,故不做高亮,当然,从数据库中查询出来再做高亮也是可以的。

4.4 分页检索
不多说,你需要的我都整活,直接上代码,分页直接再程序中写死了,正常需要传分页参数,返回分页数据,总条数等,不利于演示,和普通分页一样,自己封装吧
/**
* 分页搜索
*/
@RequestMapping("/searchTextPage")
public List<BlogTitle> searchTextPage(String text) throws IOException, ParseException, InvalidTokenOffsetsException {
String[] str = {"title", "description"};
int page = 1;
int pageSize = 5;
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new IKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 分页获取数据
TopDocs topDocs = searchByPage(page, pageSize, searcher, query);
// 获取总条数
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
//高亮后的段落范围在100字内
Fragmenter fragmenter = new SimpleFragmenter(100);
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<BlogTitle> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docId = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docId);
BlogTitle content = blogTitleMapper.selectById(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new IKAnalyzer(), "title", doc.get("title"));
if (title == null) {
title = content.getTitle();
}
String description = highlighter.getBestFragment(new IKAnalyzer(), "description", content.getDescription());
content.setDescription(description);
content.setTitle(title);
list.add(content);
}
return list;
}
private TopDocs searchByPage(int page, int perPage, IndexSearcher searcher, Query query) throws IOException {
TopDocs result;
if (query == null) {
log.info(" Query is null return null ");
return null;
}
ScoreDoc before = null;
if (page != 1) {
TopDocs docsBefore = searcher.search(query, (page - 1) * perPage);
ScoreDoc[] scoreDocs = docsBefore.scoreDocs;
if (scoreDocs.length > 0) {
before = scoreDocs[scoreDocs.length - 1];
}
}
result = searcher.searchAfter(before, query, perPage);
return result;
}
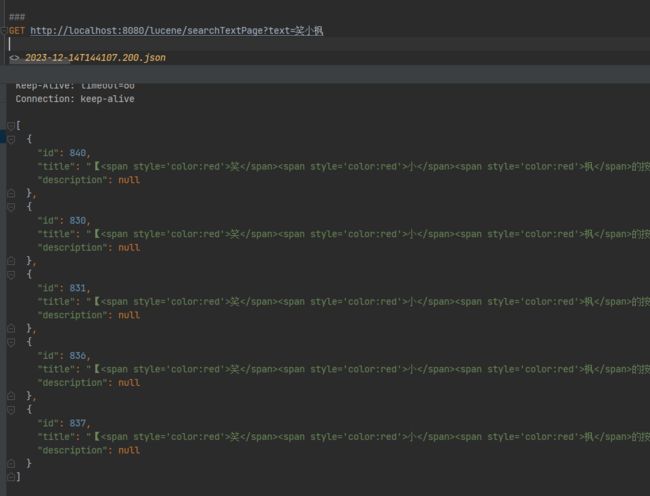
GET http://localhost:8080/lucene/searchTextPage?text=笑小枫
第一页数据:

第二页数据:
手动修改int page = 2;保证没偷懒~
4.5多个关键词搜索
最起码满足你的日常使用吧。
/**
* 多关键词搜索
*/
@GetMapping("/searchTextMoreParam")
public List<BlogTitle> searchTextMoreParam(String text) throws IOException, ParseException, InvalidTokenOffsetsException {
String[] str = {"title", "description"};
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
//多条件查询构造
BooleanQuery.Builder builder = new BooleanQuery.Builder();
// 条件一
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new IKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
builder.add(query, BooleanClause.Occur.MUST);
// 条件二
// TermQuery不使用分析器所以建议匹配不分词的Field域(StringField, )查询,比如价格、分类ID号等。这里只能演示个ID了。。。
Query termQuery = new TermQuery(new Term("id", "839"));
builder.add(termQuery, BooleanClause.Occur.MUST);
// 获取前十条记录
TopDocs topDocs = searcher.search(builder.build(), 100);
// 获取总条数
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
//高亮后的段落范围在100字内
Fragmenter fragmenter = new SimpleFragmenter(100);
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<BlogTitle> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docId = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docId);
BlogTitle content = blogTitleMapper.selectById(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new IKAnalyzer(), "title", doc.get("title"));
if (title == null) {
title = content.getTitle();
}
String description = highlighter.getBestFragment(new IKAnalyzer(), "description", content.getDescription());
content.setDescription(description);
content.setTitle(title);
list.add(content);
}
return list;
}
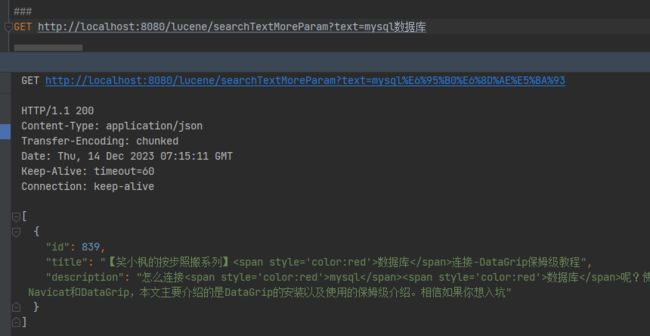
GET http://localhost:8080/lucene/searchTextMoreParam?text=mysql数据库
5. IK扩展词处理
什么是扩展词呢?字面意思。
就如笑小枫,我认为它是一个完整的词汇,但是人家IK不认呀,怎么办呢?
还有就是的,和,了这些分词检索没有太大意义的词,我们可以过滤掉,不参与检索。
不说废话,怎么做呢?看图~

添加上图文件即可,生不生效,看高亮就很明显,下文演示。
说说坑哈
坑一:注意打包后有没有文件,如果没有打进去的话,就会不生效
坑二:设置后,需要重新创建索引,不然可能会查不到数据
注意这个名字不能错IKAnalyzer.cfg.xml,放在resources目录下
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IKAnalyzer扩展配置comment>
<entry key="ext_dict">extend.dicentry>
<entry key="ext_stopwords">stop.dicentry>
properties>
extend.dic对应上面文件中的名字(名字可以自定义,同步IKAnalyzer.cfg.xml修改)和路径,输入多个回车即可
笑小枫系列
笑小枫
按步照搬
stop.dic对应上面文件中的名字(名字可以自定义)和路径,输入多个回车即可
的
好
了
设置前:

设置后:

6. 项目源码
本文到此就结束了,如果帮助到你了,帮忙点个赞
本文源码:https://github.com/hack-feng/maple-product/tree/main/maple-lucene
我是笑小枫,全网皆可搜的【笑小枫】