ELK(六)—Filebeat安装部署
目录
- 一、介绍
-
- 1.1特点
- 1.2使用原因
- 1.3结构图
- 1.4工作流程
- 二、安装部署
-
- 2.1下载
- 2.2启动
- 2.3监控日志文件
- 2.4自定义字段
- 三、连接Elasticsearch
- 四、工作原理
一、介绍
Filebeat是一个轻量级的日志和文件数据收集器,属于Elastic Stack(ELK Stack)中的一个组件。它的主要作用是搜集、传输和转发各种类型的日志和事件数据,将这些数据发送到中央的Elasticsearch集群或者Logstash进行处理和存储。以下是Filebeat的一些关键特性和使用原因:
Filebeat的官网网址如下:https://www.elastic.co/cn/beats/filebeat
1.1特点
- 轻量级: Filebeat是一个小型的、轻量级的代理,对系统资源的消耗相对较低。
- 易于配置: Filebeat的配置相对简单,可以通过YAML文件轻松配置日志路径、数据输入、输出等。
- 多数据输入: 支持多种输入源,包括文件、日志文件、系统日志等。
- 多数据输出: 可以将数据发送到Elasticsearch、Logstash等多个目标。
- 模块化: 支持模块化的配置,可轻松集成到Elastic Stack中。
- 实时性: 提供近实时的数据传输,支持快速检测和响应。
1.2使用原因
- 集中日志管理: Filebeat帮助组织集中管理日志数据,通过将日志数据发送到Elasticsearch中,用户可以使用Kibana等工具来轻松搜索和分析数据。
- 实时监控: Filebeat的实时数据传输能力使得用户能够迅速监测系统中发生的事件,帮助实现实时监控和警报。
- 日志数据分析: Filebeat能够解析和发送各种日志格式,包括结构化和非结构化的数据,以便进行更深入的分析。
- 简化数据流程: Filebeat通过将数据发送到Elasticsearch或Logstash,使得整个数据流程更为简单和灵活。
- 集成到Elastic Stack: 作为Elastic Stack的一部分,Filebeat无缝集成到Elasticsearch、Logstash、Kibana等组件中,为日志和事件处理提供了完整的解决方案。
总体而言,Filebeat是一个强大的工具,使得日志和事件数据的搜集和处理变得更为简单和高效。通过与其他Elastic Stack组件配合使用,用户可以建立一个强大的实时日志分析和监控系统。
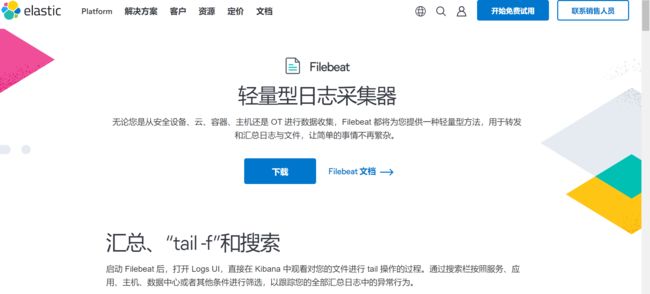
1.3结构图

1.4工作流程
Filebeat的工作流程可以总结为以下几个步骤:
- Input 输入: 在Filebeat的配置中,可以指定多个数据输入源,这些源可以是文件、日志文件、系统日志等。用户可以使用通配符指定多个源,以便匹配到相应的日志文件。
- Harvester 收割机: 一旦Filebeat匹配到日志文件,就会启动一个称为Harvester的组件。Harvester负责从日志文件中源源不断地读取数据,确保Filebeat可以实时地捕捉到新的日志事件。
- Spooler 卷轴: Harvester将收割到的日志数据传递给Spooler,这是Filebeat内部的一个组件。Spooler的作用是将接收到的数据进行缓冲和处理,并将它们传递到后续的输出目标。
- Output 输出: Filebeat支持将数据发送到多个输出目标,其中最常见的是Elasticsearch和Logstash。数据可以通过输出插件配置,灵活地传递到用户指定的目标,从而实现集中式存储、分析和可视化。
整个流程中,Filebeat保证了日志数据的实时性,从而满足了用户对于快速响应和实时监控的需求。通过将Filebeat与Elasticsearch、Logstash等组件结合使用,用户可以轻松地构建强大的实时日志处理和分析系统。
二、安装部署
2.1下载
机器是直接wget下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.1-linux-x86_64.tar.gz
也可以去官网上下载 https://www.elastic.co/cn/downloads/beats/filebeat


下载完成后,就是解压操作了
tar -zxvf filebeat-8.11.1-linux-x86_64.tar.gz
重命名
mv filebeat-8.11.1-linux-x86_64 filebeat
进入到filebeat目录下,进行操作(需要新建一个.yml文件)
vim hmiyuan.yml
在文件输入下面的内容
filebeat.inputs: # filebeat input输入
- type: stdin # 标准输入
enabled: true # 启用标准输入
setup.template.settings:
index.number_of_shards: 3 # 指定下载数
output.console: # 控制台输出
pretty: true # 启用美化功能
enable: true
filebeat.inputs: 定义Filebeat的输入源。在这里,您配置了一个stdin输入,表示通过标准输入读取日志。setup.template.settings: 配置模板的一些设置。在这里,您指定了索引的分片数为 3。output.console: 配置Filebeat的输出目的地。在这里,您将日志输出到控制台,并启用了美化功能。
2.2启动
./filebeat -e -c hmiyuan.yml
./filebeat -e -c hmiyuan.yml命令是在以hmiyuan.yml为配置文件运行 Filebeat,-e标志表示在启动时显示调试信息。
启动成功画面
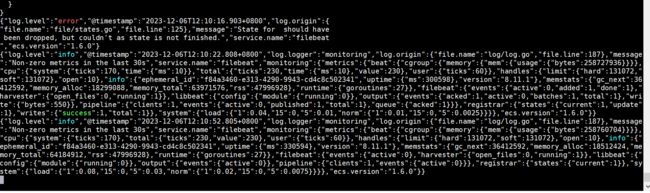
然后我们在控制台输入信息

随后我们在控制台可以看到一个json格式的输出,内容如下
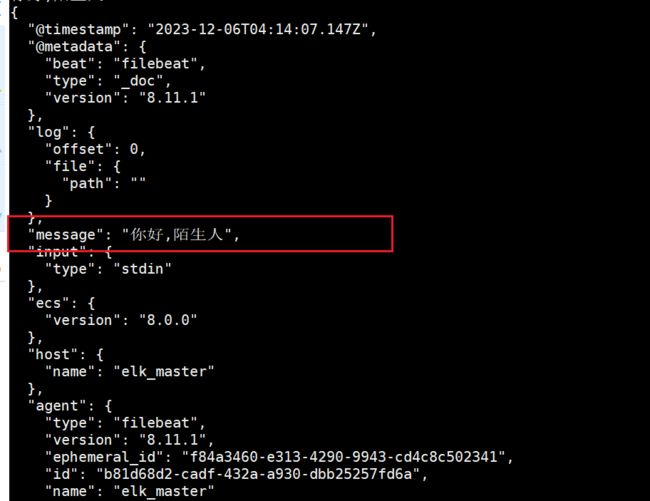 、
、
2.3监控日志文件
在filebeat目录下创建一个“hmiyuan-log.yml”文件,文件内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/elk/logs/*.log
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
filebeat.inputs: 定义 Filebeat 的输入配置,这里指定了一个日志输入。
type: log: 表示输入类型是日志文件。enabled: true: 启用该输入。paths: 指定要监视的日志文件路径。在这个例子中,它监视/opt/elk/logs/目录下所有以.log结尾的文件。
setup.template.settings: 用于设置模板相关的配置。
index.number_of_shards: 3: 设置 Elasticsearch 索引的分片数量为
output.console: 配置输出到控制台的设置。
pretty: true: 启用漂亮的输出,使日志更易读。enable: true: 启用控制台输出。
文件创建好了之后,我们需要创建上文中的path中文件了。
mkdir -p /opt/elk/logs
上面的配置完成后,我们就可以进行测试看是否配置完成了。
echo "hello world" >> /opt/elk/logs/test.log
重启启动filebeat并指定配置文件
./filebeat -e -c hmiyuan-log.yml
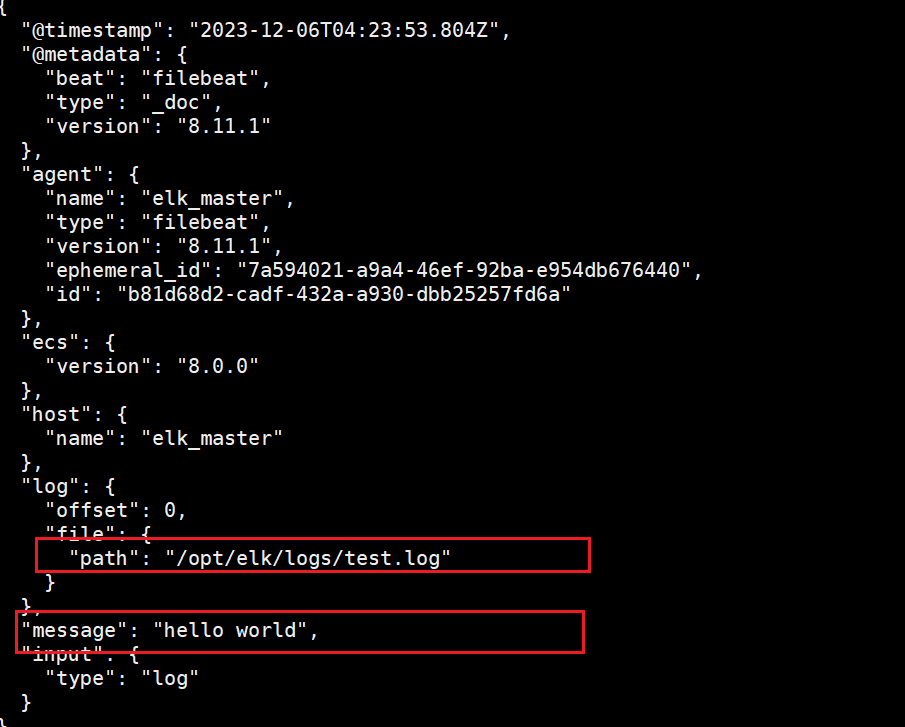
可以看到文件中的内容以及被filebeat读取出来了
追加数据
echo "你好,陌生人" >> test.log
可以看到新增的数据也成功被收集了

在"/opt/elk/log"中的添加新文件,同时添加数据
echo "a new directory" >> one.log
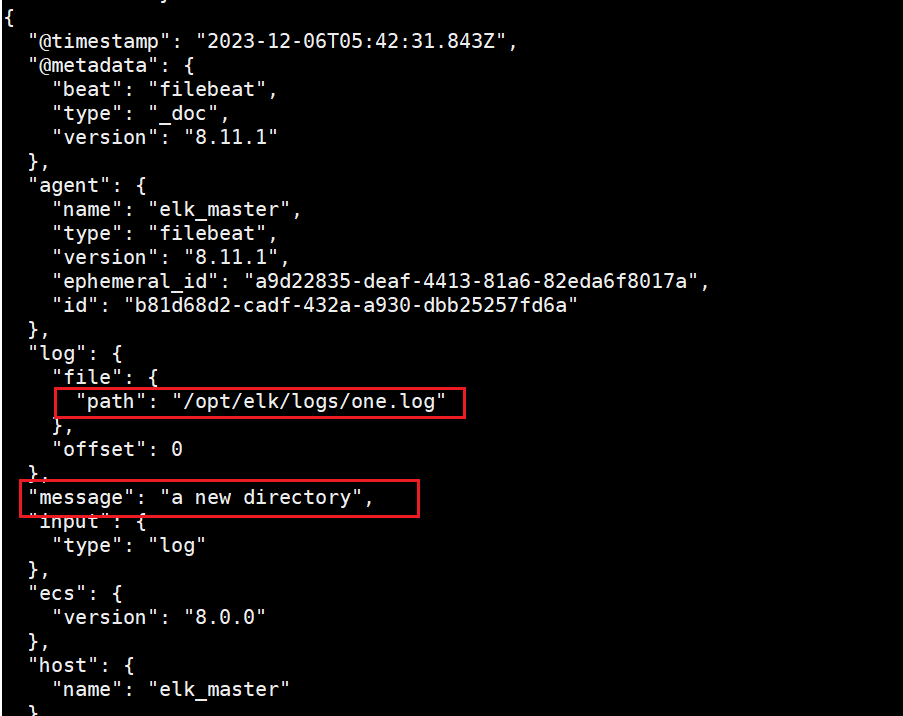
2.4自定义字段
当我们的元数据没办法支撑我们的业务时,我们还可以自定义添加一些字段.
修改"filebeat-log.yml"文件的内容。
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/elk/logs/*.log
tags: ["web", "test"]
fields:
from: web-test
fields_under_root: true
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
新添加部分解析
Tags(标签):
tags: ["web", "test"]这里通过
tags字段为事件添加了两个标签,即 “web” 和 “test”。标签是一种用于标识事件的方式,它可以在后续的处理中用于过滤或分类事件。Fields(字段):
fields: from: web-test通过
fields字段添加了一个自定义字段,即from: web-test。这是一种为事件添加额外信息的方式,您可以根据需要添加不同的字段。在这个例子中,为事件指定了来源是 “web-test”。Fields Under Root(添加到根节点):
fields_under_root: true
fields_under_root设置为true,这表示将自定义字段添加到事件的根节点,而不是作为子节点。这样,添加的字段会直接位于事件的顶层,而不是嵌套在其他字段中。这些配置的添加使您能够在 Filebeat 采集的日志事件中附加额外的信息,以便更好地进行后续处理和分析。
修改完成后,重启filebeat
./filebeat -e -c hmiyuan-log.yml
添加数据到“/opt/elk/logs/test.log”中
echo "a god day" >> /opt/elk/logs/test.log
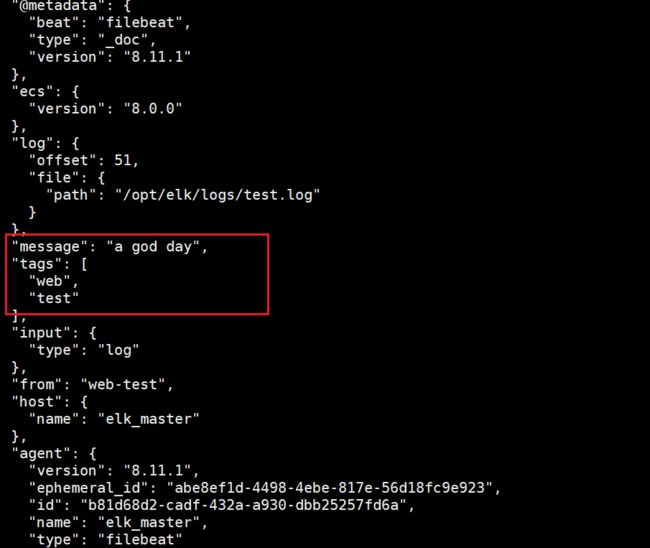
可以看到自定义字段已经成功显示出来了。
三、连接Elasticsearch
继续修改“hmiyuan-log.yml”文件,添加elasticsearch的ip以及暴露出来的端口号。
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/elk/logs/*.log
tags: ["web", "test"]
fields:
from: web-test
fields_under_root: false
setup.template.settings:
index.number_of_shards: 1
output.elasticsearch:
hosts: ["192.168.150.190:9200"] #这里填写elasticsearch机器的ip以及端口,可以添加多台机器
重启启动filebeat
./filebeat -e -c hmiyuan-log.yml
查看filebeat启动的时候输出的相关信息,可以看到已经成功连接到了190这台机器上了,接下来继续向"/opt/elk/log/"目录下的文件输入信息,查看elasticsearch是否也可以接收到数据。
![]()
向“test.log”文件追加信息。
echo "dog" >> /opt/elk/logs/test.log
在ES中,我们可以看到,多出了一个 filebeat的索引库
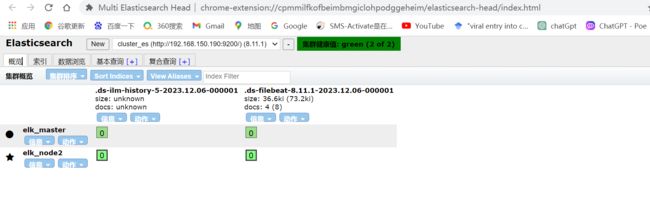
然后我们浏览对应的数据,看看是否有插入的数据内容
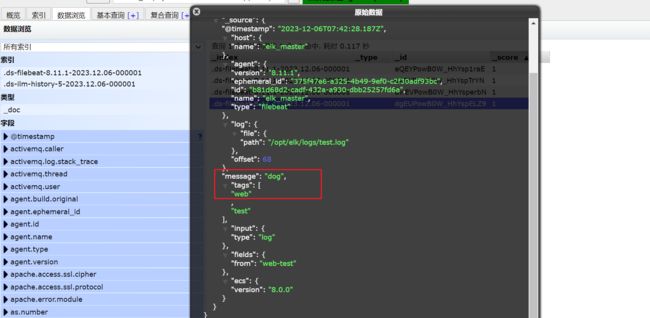
elasticsearch已经拿到了数据了,并展示到了elasticsearch-head中。
四、工作原理
Filebeat工作原理
Filebeat主要由下面几个组件组成: harvester、prospector 、input
harvester
负责读取单个文件的内容
harvester逐行读取每个文件(一行一行读取),并把这些内容发送到输出
每个文件启动一个harvester,并且harvester负责打开和关闭这些文件,这就意味着harvester运行时文件描述符保持着打开的状态。
在harvester正在读取文件内容的时候,文件被删除或者重命名了,那么Filebeat就会续读这个文件,这就会造成一个问题,就是只要负责这个文件的harvester没用关闭,那么磁盘空间就不会被释放,默认情况下,Filebeat保存问价你打开直到close_inactive到达
prospector
prospector负责管理harvester并找到所有要读取的文件来源
如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester
Filebeat目前支持两种prospector类型:log和stdin
Filebeat如何保持文件的状态
Filebeat保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中
该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
如果输出(例如ElasticSearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可以用时继续读取文件。
在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,当重新启动Filebat时,将使用注册文件的数量来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取
文件状态记录在data/registry文件中
input
一个input负责管理harvester,并找到所有要读取的源
如果input类型是log,则input查找驱动器上与已定义的glob路径匹配的所有文件,并为每个文件启动一个harvester
每个input都在自己的Go例程中运行