Map学习记录
Map
键值对
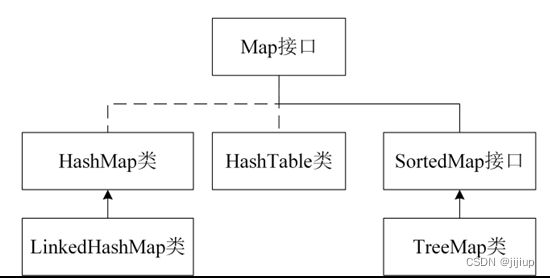
HashMap
- Key是无序、不重复的,Value是无序可重复的
- 线程不安全
- 有参构造时,底层数组长度是最接近参数的2的幂次方
JDK1.7,HashMap的底层结构是数组(长度16)+链表
- put(key,value)时,根据key获取hashcode值,进行映射后获取在数组中的位置,如果该位置上元素为空,那么可直接添加,如果元素不为空,那么比较哈希值是否相同,如果不相同,头插法插入链表,如果相同,进一步使用equals是否相同,如果相同,value覆盖,如果不相同,头插法插入链表
- 如果数组中的元素数量超过了临界值(负载因子0.75*数组长度),则数组扩容为原来的2倍
JDK1.8,HashMap的底层结构是数组(长度16)+链表+红黑树
- 如果链表长度大于8,且数组长度大于64(当数组长度小于64时,数组扩容),则将链表转换为红黑树
- 类似,无参构建时底层数组初始化为{},第一次put元素时,才初始化长度为16的数组
- 其他与JDK1.7类似
为啥线程不安全?
JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,造成死循环、数据丢失。
- HashMap的扩容操作:重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码(判断是否出现hash碰撞)后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
引用自https://juejin.cn/post/6917526751199526920
无序性
无序性不等同于随机性,向多个HashMap添加相同顺序的元素,遍历顺序是一致的,无序是指元素在底层数组中的存储顺序不是按照添加顺序来存储,而是按照哈希值来存储。
负载因子0.75
数组元素个数 > 负载因子*数组长度,则扩容
负载因子的大小决定了HashMap的数据密度
- 负载因子越大,数组扩容的阈值越大,则数组的密度越大,发生碰撞的几率也越高,即链表的长度越长,查找的效率变慢
- 负载因子越小,数组扩容的阈值越小,则数组的密度越小,数组的利用率不高,很快就要进行数组扩容,性能消耗过多
- 通过泊松分布确定0.75(好像)
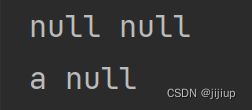
HashMap的key可以存null,value也可以存null
public static void main(String[] args) {
HashMap map = new HashMap<>();
map.put(null, "a");
map.put(null, null);
map.put("a", null);
for(Map.Entry entry: map.entrySet()){
System.out.println(entry.getKey() + " " + entry.getValue());
}
} 
底层数组长度是2的幂次方大小
通过(n-1) & hash确定put元素时在数组中的位置
hash%length == hash&(length-1) 的前提是 length 是 2 的 n 次方,位运算的计算速度比取余运算的计算速度要快
LinkedHashMap
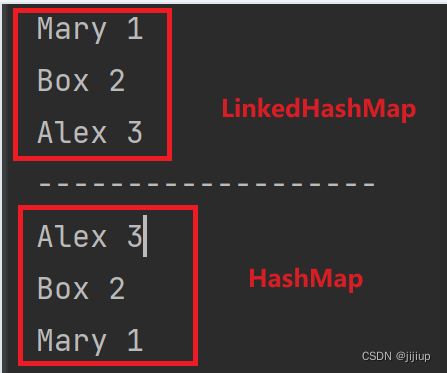
- 在HashMap的基础上引入了双向链表
- 遍历元素时,可按照添加顺序遍历
public static void main(String[] args) {
LinkedHashMap tt = new LinkedHashMap<>();
tt.put("Mary",1);
tt.put("Box",2);
tt.put("Alex",3);
for(Map.Entry entry: tt.entrySet()){
System.out.println(entry.getKey() + " " + entry.getValue());
}
System.out.println("-------------------");
HashMap aa = new HashMap<>();
aa.put("Mary", 1);
aa.put("Box", 2);
aa.put("Alex", 3);
for(Map.Entry entry: aa.entrySet()){
System.out.println(entry.getKey() + " " + entry.getValue());
}
} 
HashTable
- 线程安全,方法用synchronized修饰,性能低
- 底层是数组,默认容量为11
不可以存null的key和null的value
- 当value值为null时主动抛出空指针异常
- 会对key值进行哈希计算,如果为null的话,无法调用该方法,会抛出空指针异常
CocurrentHashMap
线程安全
JDK1.7时,底层结构是分段数组+链表
- 线程安全的实现是对Segment数组的每一段加锁,Segment数组的长度是16,意味值可同时支持16个并发线程。
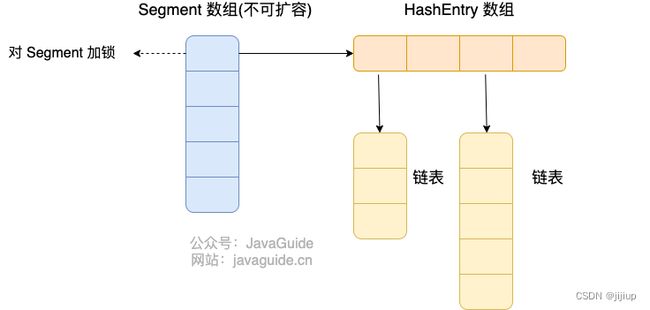
引用自JavaGuide
JDK1.8时,底层与HashMap一样,均为数组+链表+红黑树
- 锁粒度更细,线程安全的实现是只给链表或红黑树的首节点加锁,并发程度更高
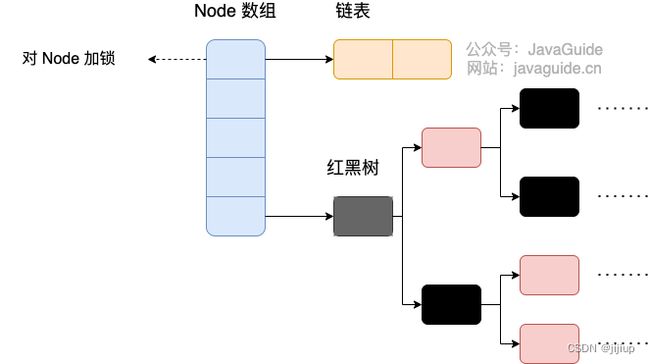
引用自JavaGuide
TreeMap
- 底层是红黑树
- 可以按照key进行排序,默认是升序
如果key是对象,可实现Comparable接口,重写compareTo方法,从而实现定制排序
public class Person implements Comparable{
private int age;
public Person(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age;
}
@Override
public int hashCode() {
return Objects.hash(age);
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
'}';
}
@Override
public int compareTo(Object o) {
Person p = (Person) o;
int re = this.age - p.age;
return re;
}
}
//重写compareTo方法
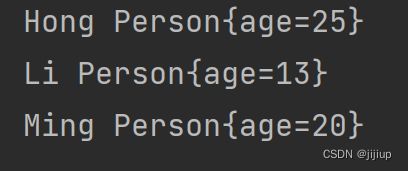
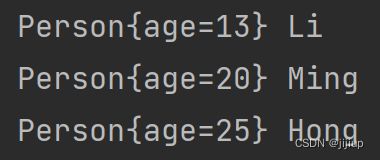
public static void main(String[] args) {
TreeMap treeMap = new TreeMap<>();
treeMap.put(new Person(20), "Ming");
treeMap.put(new Person(25),"Hong");
treeMap.put(new Person(13),"Li");
for(Map.Entry entry: treeMap.entrySet()){
System.out.println(entry.getKey() + " " + entry.getValue());
}
} 
使用匿名内部类或lambda表达式,重写Comparator接口的compare方法,从而实现定制排序
//匿名内部类
public static void main(String[] args) {
TreeMap treeMap = new TreeMap<>(new Comparator() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
treeMap.put("Ming", new Person(20));
treeMap.put("Hong", new Person(25));
treeMap.put("Li", new Person(13));
for(Map.Entry entry: treeMap.entrySet()){
System.out.println(entry.getKey() + " " + entry.getValue());
}
}