基于深度学习的课堂举手人数统计系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着信息技术的快速发展,教育领域也逐渐开始应用新技术来改善教学质量和效果。在传统的课堂教学中,教师通常需要手动记录学生的举手情况,以便了解学生的参与度和理解程度。然而,这种方式存在一些问题,例如记录不准确、效率低下等。因此,基于深度学习的课堂举手人数统计系统应运而生。
深度学习是一种机器学习的方法,通过模拟人脑神经网络的工作原理,可以从大量的数据中学习和提取特征,进而实现各种复杂的任务。在课堂教学中,深度学习可以被应用于识别学生的举手动作,从而实现自动统计学生的举手人数。
基于深度学习的课堂举手人数统计系统具有以下几个方面的意义:
-
提高教学效果:通过自动统计学生的举手人数,教师可以更准确地了解学生的参与度和理解程度。这样,教师可以根据学生的反馈情况及时调整教学内容和方法,提高教学效果。
-
提高教学效率:传统的手动记录学生举手情况需要耗费大量的时间和精力,而基于深度学习的课堂举手人数统计系统可以实现自动化,大大提高了教学效率。教师可以将更多的时间和精力放在教学内容的准备和讲解上,提高教学质量。
-
个性化教学:基于深度学习的课堂举手人数统计系统可以实时监测学生的参与度和理解程度,为教师提供了更多的信息来进行个性化教学。教师可以根据学生的反馈情况,有针对性地给予不同的辅导和指导,满足学生的个性化学习需求。
-
科学研究:基于深度学习的课堂举手人数统计系统可以为教育研究提供更多的数据支持。通过分析学生的举手情况和教学效果的关系,可以深入研究教学方法和策略的有效性,为教育改革和教学改进提供科学依据。
总之,基于深度学习的课堂举手人数统计系统在提高教学效果和效率的同时,也为个性化教学和科学研究提供了新的可能性。随着深度学习技术的不断发展和应用,相信这一系统将在教育领域发挥越来越重要的作用。
2.图片演示
3.视频演示
基于深度学习的课堂举手人数统计系统_哔哩哔哩_bilibili
4.姿态估计经典结构简介
人体姿态估计又叫人体骨骼点检测,就是从一幅图像或一段视频中找出其中骨骼关键点位置的过程。
姿态估计根据输入的不同分为:基于RGB-D图的算法和基于RGB图像的算法。前者需要类似kinect的设备,不易于大规模的部署应用。而基于RGB图像的算法具有更广的应用前景,并且有大型的公开数据集供学术界研究和竞赛,是非常热门研究领域,达到了非常好的识别效果。
针对姿态估计的研究方法,则可以分为回归和检测。对于回归问题,我们希望直接回归出关键点的位置,对于检测问题,我们希望得到关键点的热度图。回归的缺点在于肢体的运动比较灵活,并且比较难以扩展到人数未知的场景下进行,因为这样输出不好控制,所以目前使用比较普遍的是通过热度图得到关节点的位置,如果某个像素点是关键点的话,该像素点在热度图上的响应就比其他地方大。
而针对姿态估计的网络结构的探索也主要围绕多尺度的信息融合来进行,因为如果我们只通过局部的视觉信息,很难看出某些部位是什么,并且也很难区分比如手肘和膝盖,手腕和脚踝等,如图所示。

只看方框内的部分,很难看出这是人体身上的哪个部位。而加上全图上下文信息之后,识别起来就容易得多。下面介绍针对姿态估计问题的几种流行的网络结构。
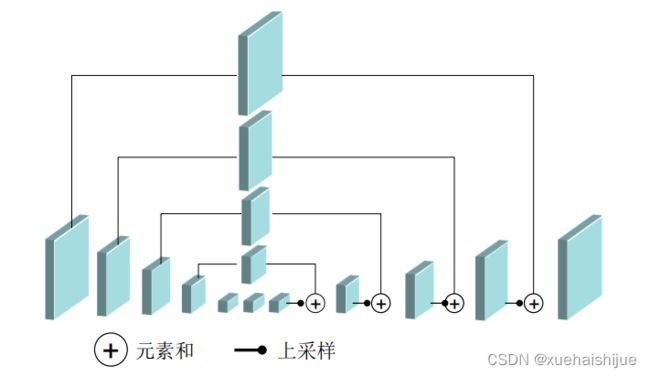
2016年在 MPII数据集夺冠的Hourglass结构!17是一种串行的结构,先进行下采样,再进行上采样,同时把下采样过程中和上采样过程中大小相同的特征图做元素相加,以此来结合不同尺度下的图片特征。这样的一个模块形状就像沙漏一样,如图2.6所示。通过这样模块的堆叠,来组成一个更深的,由粗到精的表达能力更好的网络结构。
2017年,Chen等人提出了Cascaded Pyramid Network(级联金字塔)[22结构,首先使用基于特征金字塔的GlobalNet学习一个好的特征表征,特征金字塔已经利用了深层的语义信息与浅层的纹理信息的结合,可以提供足够的语境信息,然后使用RefineNet 接受了来自所有金字塔层的特征信息,而不是类似Hourglass模块之间仅通过最后一个上采样特征进行信息传递,通过上采样到相同的尺寸,然后连接起来,结构如图所示。
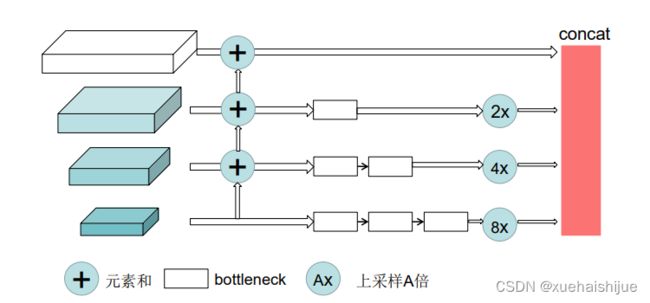
然后通过在线困难点挖掘(Online hard example mining),选取一半损失值较大的关键点,进行梯度回传,来处理较难检测的关键点。
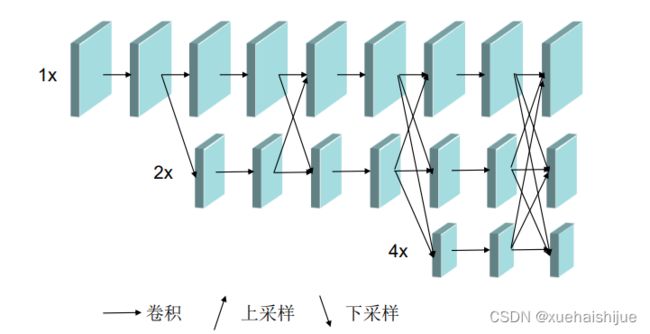
2019年,Sun等人提出的High-Resolution Netl34,能够在整个过程中保持高分辨率的特征表示,并行的生成分辨率由高到低的子网络,并且在高低分辨率子网络之间反复的交换信息。这种方法不是单纯的利用串行的连接,从高到低降低分辨率再由低到高恢复分辨率,也不是简单的将低层和高层融合起来,而是重复的多尺度融合,利用相同深度的低分辨率表示来提高高分辨率的表示,预测的热度图上会更加精确。目前在COCO关键点比赛3l中取得了最好的效果。该网络的结果如图所示。
除了在网络结构本身上的改进,也可以通过对人的整体或者各个部位引入注意力机制,或者利用人体结构化信息更好的预测最终的结果。本文的举手手势识别就是建立在姿态估计的基础上,通过得到学生身体关键点的信息来定位手臂和手掌的位置,然后进行进一步的分析。
5.核心代码讲解
5.1 detect.py
class PoseDetector:
def __init__(self, weight_path, cpu=False, track=1, smooth=1, height_size=256):
self.net = PoseEstimationWithMobileNet()
self.cpu = cpu
self.track = track
self.smooth = smooth
self.height_size = height_size
checkpoint = torch.load(weight_path, map_location='cpu')
load_state(self.net, checkpoint)
self.net = self.net.eval()
if not self.cpu:
self.net = self.net.cuda()
def angle_between_points(self, pose, k1, k2, k3):
x1, y1 = pose.keypoints[k1][0], pose.keypoints[k1][1]
x2, y2 = pose.keypoints[k2][0], pose.keypoints[k2][1]
x3, y3 = pose.keypoints[k3][0], pose.keypoints[k3][1]
v1 = (x1 - x2, y1 - y2)
v2 = (x3 - x2, y3 - y2)
dot_product = v1[0] * v2[0] + v1[1] * v2[1]
norm_v1 = math.sqrt(v1[0] ** 2 + v1[1] ** 2)
norm_v2 = math.sqrt(v2[0] ** 2 + v2[1] ** 2)
cos_theta = dot_product / (norm_v1 * norm_v2)
theta = math.acos(cos_theta)
angle = math.degrees(theta)
return angle
def infer_fast(self, img, stride, upsample_ratio, pad_value=(0, 0, 0), img_mean=np.array([128, 128, 128], np.float32), img_scale=np.float32(1/256)):
height, width, _ = img.shape
scale = self.height_size / height
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
scaled_img = normalize(scaled_img, img_mean, img_scale)
min_dims = [self.height_size, max(scaled_img.shape[1], self.height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = torch.from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float()
if not self.cpu:
tensor_img = tensor_img.cuda()
stages_output = self.net(tensor_img)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
return heatmaps, pafs, scale, pad
def detect(self, img):
stride = 8
upsample_ratio = 4
num_keypoints = Pose.num_kpts
previous_poses = []
delay = 1
orig_img = img.copy()
heatmaps, pafs, scale, pad = self.infer_fast(img, stride, upsample_ratio)
total_keypoints_num = 0
all_keypoints_by_type = []
for kpt_idx in range(num_keypoints):
total_keypoints_num += extract_keypoints(heatmaps[:, :, kpt_idx], all_keypoints_by_type, total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, pafs)
for kpt_id in range(all_keypoints.shape[0]):
all_keypoints[kpt_id, 0] = (all_keypoints[kpt_id, 0] * stride / upsample_ratio - pad[1]) / scale
all_keypoints[kpt_id, 1] = (all_keypoints[kpt_id, 1] * stride / upsample_ratio - pad[0]) / scale
current_poses = []
for n in range(len(pose_entries)):
if len(pose_entries[n]) == 0:
continue
pose_keypoints = np.ones((num_keypoints, 2), dtype=np.int32) * -1
for kpt_id in range(num_keypoints):
if pose_entries[n][kpt_id] != -1.0:
pose_keypoints[kpt_id, 0] = int(all_keypoints[int(pose_entries[n][kpt_id]), 0])
pose_keypoints[kpt_id, 1] = int(all_keypoints[int(pose_entries[n][kpt_id]), 1])
pose = Pose(pose_keypoints, pose_entries[n][18])
current_poses.append(pose)
for pose in current_poses:
pose.draw(img)
if self.track:
track_poses(previous_poses, current_poses, smooth=self.smooth)
previous_poses = current_poses
status = ''
for pose in current_poses:
try:
angel = self.angle_between_points(pose, 10, 1, 13)
except:
angel = 0
x, y, w, h = pose.bbox
sho_r = pose.keypoints[2]
sho_l = pose.keypoints[5]
sho_y = round((sho_l[1] + sho_r[1]) / 2)
ank_r = pose.keypoints[10]
ank_l = pose.keypoints[13]
ank_y = round((ank_l[1] + ank_r[1]) / 2)
status = ""
color = [0,255,0]
if (w < h):
if angel > 10:
status = "walk"
else:
if (abs(ank_y - sho_y) > 0.5 * max(w, h) and w < h):
status = "stand"
elif (h / w < 1.8):
status = "squat"
elif (w > h):
if (abs(ank_y - sho_y) > 0.5 * max(w, h) and w > h):
status = "fall"
color = [0, 0, 255]
elif (w > 1.5 * h):
status = "fall"
color = [0, 0, 255]
cv2.putText(img, status, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 3, (0, 0, 255),3)
cv2.rectangle(img, (pose.bbox[0], pose.bbox[1]), (pose.bbox[0] + pose.bbox[2], pose.bbox[1] + pose.bbox[3]),
color,5)
return status, img
这个程序文件名为detect.py,主要功能是使用深度学习模型进行人体姿势检测和动作识别。
程序首先导入了必要的库和模块,包括argparse、cv2、numpy、torch等。然后定义了一些辅助函数,如计算两个关键点之间的夹角、快速推理函数等。
接下来进行了一些初始化操作,包括加载网络模型、设置是否使用CPU、设置是否进行目标跟踪等。
然后定义了一个detect函数,该函数接受一张图像作为输入,首先对图像进行预处理,然后使用网络模型进行推理,得到关键点的热图和关键点连接的矢量场。接着根据热图和矢量场提取关键点,并进行关键点的分组。然后根据关键点的位置和姿势信息进行动作识别,判断人体的状态(站立、跌倒、行走、蹲坐等),并在图像上绘制相应的文本和边界框。
最后返回人体状态和处理后的图像。
整个程序的主要功能是对输入图像进行人体姿势检测和动作识别,并在图像上进行可视化展示。
5.2 detector_CPU.py
class Detector:
def __init__(self):
self.img_size = 640
self.threshold = 0.1
self.stride = 1
self.weights = './weights/output_of_small_target_detection.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.float()
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
pedestrian = 0
boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
pass
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
xm = x2
ym = y2
boxes.append((x1, y1, x2, y2, lbl, conf))
return boxes, pedestrian
这个程序文件名为detector_CPU.py,它是一个目标检测器的类。这个类使用了PyTorch库和OpenCV库来进行目标检测。
在类的初始化方法中,定义了一些参数,如图像大小、阈值和步长。还定义了模型的权重文件路径和设备类型。然后加载模型并将其移动到指定的设备上。
preprocess方法用于对输入图像进行预处理,包括调整图像大小、转换颜色通道、转换为张量等操作。
detect方法用于对输入图像进行目标检测。首先调用preprocess方法对图像进行预处理,然后使用加载的模型对图像进行推理,得到预测结果。接着对预测结果进行非最大抑制处理,得到检测到的目标框。最后根据目标框的类别进行筛选,将符合条件的目标框和行人数量返回。
整个程序文件的功能是使用已训练好的模型对输入图像进行目标检测,并返回检测到的目标框和行人数量。
5.3 detector_GPU.py
class Detector:
def __init__(self):
self.img_size = 640
self.threshold = 0.1
self.stride = 1
self.weights = './weights/Attention_mechanism.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half()
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
xm = x2
ym = y2
if ym +0.797* xm -509.77 > 0:
boxes.append((x1, y1, x2, y2, lbl, conf))
return boxes
这个程序文件名为detector_GPU.py,它是一个目标检测器的类。该类具有以下功能:
-
初始化函数:设置图像大小、阈值和步长等参数,并加载模型权重。根据是否有GPU可用,选择设备进行计算。
-
预处理函数:对输入的图像进行预处理,包括调整图像大小、转换颜色通道顺序、转换为numpy数组和转换为torch张量等操作。
-
检测函数:对输入的图像进行目标检测。首先对图像进行预处理,然后使用加载的模型进行推理。根据阈值和非最大抑制算法,筛选出检测到的目标框,并将其存储在一个列表中返回。
总体来说,这个程序文件实现了一个基于GPU的目标检测器,可以用于检测自行车、汽车、公交车和卡车等目标。
5.4 mysql_connect.py
class DatabaseConnection:
def __init__(self):
self.host = 'localhost'
self.user = 'root'
self.password = 'root'
self.database = 'openpose_data'
self.charset = 'utf8'
self.con = None
self.cur = None
def connect(self):
# 连接数据库
self.con = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
charset=self.charset
)
# 创建游标
self.cur = self.con.cursor()
def execute_query(self, sql):
# 执行查询语句
self.cur.execute(sql)
# 获取所有记录
all_records = self.cur.fetchall()
return all_records
def close(self):
# 关闭游标
self.cur.close()
# 关闭数据库连接
self.con.close()
这是一个名为mysql_connect.py的程序文件,它使用pymysql库连接到MySQL数据库。代码中的connect()函数用于连接数据库,并执行一个查询语句,然后打印出查询结果。连接数据库时使用了本地主机(localhost)、用户名(root)、密码(root)、数据库名(openpose_data)和字符集(utf8)。代码中还创建了一个游标对象用于执行SQL语句,获取查询结果后关闭游标和数据库连接,以释放内存。
5.5 tracker.py
class ObjectTracker:
def __init__(self):
cfg = get_config()
cfg.merge_from_file("./deep_sort/configs/deep_sort.yaml")
self.deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
def draw_bboxes(self, image, bboxes, line_thickness):
line_thickness = line_thickness or round(
0.002 * (image.shape[0] + image.shape[1]) * 0.5) + 1
list_pts = []
point_radius = 4
for (x1, y1, x2, y2, cls_id, pos_id) in bboxes:
color = (0, 255, 0)
# 撞线的点
check_point_x = x1
check_point_y = int(y1 + ((y2 - y1) * 0.6))
c1, c2 = (x1, y1), (x2, y2)
cv2.rectangle(image, c1, c2, color, thickness=line_thickness, lineType=cv2.LINE_AA)
font_thickness = max(line_thickness - 1, 1)
t_size = cv2.getTextSize(cls_id, 0, fontScale=line_thickness / 3, thickness=font_thickness)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(image, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(image, '{} ID-{}'.format(cls_id, pos_id), (c1[0], c1[1] - 2), 0, line_thickness / 3,
[225, 255, 255], thickness=font_thickness, lineType=cv2.LINE_AA)
list_pts.append([check_point_x - point_radius, check_point_y - point_radius])
list_pts.append([check_point_x - point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y - point_radius])
ndarray_pts = np.array(list_pts, np.int32)
cv2.fillPoly(image, [ndarray_pts], color=(0, 0, 255))
list_pts.clear()
return image
def update(self, bboxes, image):
bbox_xywh = []
confs = []
bboxes2draw = []
if len(bboxes) > 0:
for x1, y1, x2, y2, lbl, conf in bboxes:
obj = [
int((x1 + x2) * 0.5), int((y1 + y2) * 0.5),
x2 - x1, y2 - y1
]
bbox_xywh.append(obj)
confs.append(conf)
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
outputs = self.deepsort.update(xywhs, confss, image)
for x1, y1, x2, y2, track_id in list(outputs):
# x1, y1, x2, y2, track_id = value
center_x = (x1 + x2) * 0.5
center_y = (y1 + y2) * 0.5
label = self.search_label(center_x=center_x, center_y=center_y,
bboxes_xyxy=bboxes, max_dist_threshold=20.0)
bboxes2draw.append((x1, y1, x2, y2, label, track_id))
pass
pass
return bboxes2draw
def search_label(self, center_x, center_y, bboxes_xyxy, max_dist_threshold):
"""
在 yolov5 的 bbox 中搜索中心点最接近的label
:param center_x:
:param center_y:
:param bboxes_xyxy:
:param max_dist_threshold:
:return: 字符串
"""
label = ''
# min_label = ''
min_dist = -1.0
for x1, y1, x2, y2, lbl, conf in bboxes_xyxy:
center_x2 = (x1 + x2) * 0.5
center_y2 = (y1 + y2) * 0.5
# 横纵距离都小于 max_dist
min_x = abs(center_x2 - center_x)
min_y = abs(center_y2 - center_y)
if min_x < max_dist_threshold and min_y < max_dist_threshold:
# 距离阈值,判断是否在允许误差范围内
# 取 x, y 方向上的距离平均值
avg_dist = (min_x + min_y) * 0.5
if min_dist == -1.0:
# 第一次赋值
min_dist = avg_dist
# 赋值label
label = lbl
pass
else:
# 若不是第一次,则距离小的优先
if avg_dist < min_dist:
min_dist = avg_dist
# label
label = lbl
pass
pass
pass
return label
该程序文件名为tracker.py,主要功能是使用深度学习模型进行目标跟踪。程序导入了cv2、torch和numpy等库,并使用了deep_sort库中的函数。
程序首先通过读取deep_sort.yaml配置文件,创建了DeepSort对象deepsort。然后定义了一个绘制边界框的函数draw_bboxes,该函数接受图像、边界框和线条粗细作为参数,绘制了边界框和标签,并返回绘制后的图像。
接下来定义了一个更新函数update,该函数接受边界框和图像作为参数,将边界框转换为DeepSort所需的格式,并调用deepsort.update函数进行目标跟踪。最后,根据跟踪结果,将跟踪ID和标签添加到bboxes2draw列表中,并返回该列表。
最后定义了一个搜索标签的函数search_label,该函数接受目标中心点坐标、边界框列表和最大距离阈值作为参数,通过计算目标中心点与边界框中心点的距离,找到最接近的标签,并返回该标签。
整个程序的主要功能是使用深度学习模型进行目标跟踪,并在图像上绘制边界框和标签。
5.6 train.py
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
callbacks
):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
data_dict = None
# Loggers
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz)
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
del g0, g1, g2
# Scheduler
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) *
该程序文件是用于训练一个YOLOv5模型的。文件名为train.py。程序接受一些命令行参数,包括数据集配置文件、模型权重文件、图像尺寸等。程序首先加载模型和数据集配置,并根据参数设置训练相关的超参数。然后,程序创建模型实例,并根据参数冻结一些层的权重。接下来,程序创建优化器和学习率调度器,并加载预训练权重(如果有的话)。然后,程序开始训练过程,包括前向传播、计算损失、反向传播和优化器更新。训练过程中还会进行一些日志记录和模型保存。最后,程序输出训练结果。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于深度学习的课堂举手人数统计系统。它使用了多个程序文件来实现不同的功能,包括目标检测、目标跟踪、数据库连接、模型训练和界面展示等。
主要程序文件包括detect.py、detector_CPU.py、detector_GPU.py、mysql_connect.py、tracker.py、train.py和ui.py等。其中,detect.py用于人体姿势检测和动作识别;detector_CPU.py和detector_GPU.py用于目标检测;mysql_connect.py用于连接MySQL数据库;tracker.py用于目标跟踪;train.py用于模型训练;ui.py用于界面展示。
下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| detect.py | 人体姿势检测和动作识别 |
| detector_CPU.py | CPU上的目标检测 |
| detector_GPU.py | GPU上的目标检测 |
| mysql_connect.py | 连接MySQL数据库 |
| tracker.py | 目标跟踪 |
| train.py | 模型训练 |
| ui.py | 界面展示 |
| datasets\coco.py | COCO数据集处理 |
| datasets\transformations.py | 数据集变换 |
| datasets_init_.py | 数据集初始化 |
| deep_sort\deep_sort\deep_sort.py | 深度排序算法实现 |
| deep_sort\deep_sort_init_.py | 深度排序算法初始化 |
| deep_sort\deep_sort\deep\evaluate.py | 深度评估 |
| deep_sort\deep_sort\deep\feature_extractor.py | 特征提取器 |
| deep_sort\deep_sort\deep\model.py | 深度模型 |
| deep_sort\deep_sort\deep\original_model.py | 原始模型 |
| deep_sort\deep_sort\deep\test.py | 深度模型测试 |
| deep_sort\deep_sort\deep\train.py | 深度模型训练 |
| deep_sort\deep_sort\deep_init_.py | 深度模型初始化 |
| deep_sort\deep_sort\sort\detection.py | 目标检测 |
| deep_sort\deep_sort\sort\iou_matching.py | IoU匹配算法 |
| deep_sort\deep_sort\sort\kalman_filter.py | 卡尔曼滤波器 |
| deep_sort\deep_sort\sort\linear_assignment.py | 线性分配算法 |
| deep_sort\deep_sort\sort\nn_matching.py | NN匹配算法 |
| deep_sort\deep_sort\sort\preprocessing.py | 数据预处理 |
| deep_sort\deep_sort\sort\track.py | 跟踪 |
| deep_sort\deep_sort\sort\tracker.py | 跟踪器 |
| deep_sort\deep_sort\sort_init_.py | 跟踪初始化 |
| deep_sort\utils\asserts.py | 断言工具 |
| deep_sort\utils\draw.py | 绘图工具 |
| deep_sort\utils\evaluation.py | 评估工具 |
| deep_sort\utils\io.py | 输入输出工具 |
| deep_sort\utils\json_logger.py | JSON日志记录工具 |
| deep_sort\utils\log.py | 日志工具 |
| deep_sort\utils\parser.py | 解析器工具 |
| deep_sort\utils\tools.py | 工具函数 |
| deep_sort\utils_init_.py | 工具初始化 |
| models\common.py | 通用模型 |
| models\experimental.py | 实验模型 |
| models\export.py | 模型导出 |
| models\with_mobilenet.py | 带有MobileNet的模型 |
| models\yolo.py | YOLO模型 |
| models_init_.py | 模型初始化 |
| modules\conv.py | 卷积模块 |
| modules\get_parameters.py | 获取参数 |
| modules\keypoints.py | 关键点模块 |
| modules\load_state.py | 加载状态 |
| modules\loss.py | 损失函数 |
| modules\one_euro_filter.py | 一欧滤波器 |
| modules\pose.py | 姿势模块 |
| modules_init_.py | 模块初始化 |
| scripts\convert_to_onnx.py | 转换为ONNX格式脚本 |
| scripts\make_val_subset.py | 创建验证集子集脚本 |
| scripts\prepare_train_labels.py | 准备训练标签脚本 |
| utils\activations.py | 激活函数工具 |
| utils\autoanchor.py | 自动锚框工具 |
| utils\datasets.py | 数据集工具 |
| utils\general.py | 通用工具 |
| utils\google_utils.py | Google工具 |
| utils\loss.py | 损失函数工具 |
| utils\metrics.py | 指标工具 |
| utils\plots.py | 绘图工具 |
| utils\torch_utils.py | PyTorch工具 |
| utils_init_.py | 工具初始化 |
| utils\aws\resume.py | AWS恢复工具 |
| utils\aws_init_.py | AWS工具初始化 |
| utils\wandb_logging\log_dataset.py | WandB日志记录工具 |
| utils\wandb_logging\wandb_utils.py | WandB工具 |
| utils\wandb_logging_init_.py | WandB工具初始化 |
请注意,由于文件较多,可能有些文件的功能描述不够详细或准确。建议在具体使用时,查看每个文件的代码和注释以获得更详细的信息。
7.姿态估计算法
姿态估计目前的研究已经比较成熟并且有公开的大型数据集可以使用。对一张真实场景的RGB图像,姿态估计的方法可以得到每个学生的骨骼关键点的信息,包括脸部的关键点信息,比如鼻子、眼睛、耳朵,还有身体关键点的位置信息,包括肩膀、手腕、手肘、髋部、膝盖、脚踝。
在本文介绍了自上而下和自下而上两种姿态估计方案,以及各自的不足之处。不过,针对举手识别的问题,自下而上的方案有以下几个优势:(1)为了减少姿态估计漏检情况,本文只需要一个人身上包含左手或者右手的肩膀、手肘和手腕三个关键点,而不需要集成整个身体的关键点;(2)为了减少误检的情况,要求集成出来的关键点的平均得分高于本文设置的阈值;(3)自下而上方法的检测时间受课堂人数影响很小,所以本文采用了自下而上的姿态估计方法。
网络设计
姿态估计的网络结构通常要围绕多尺度的信息融合,本文的姿态估计算法的网络由一个基础的图片特征提取网络和六个级联的针对姿态的卷积网络组成,每个阶段在前一阶段的结果基础上,重复产生关键点的置信图和部位关系图,产生越来越精细的预测结果。由于图片中的人可能占据图片的大部分区域,也可能只占据一小部分区域,为了捕捉大范围的肢体尺度变化,利用较多的图片上下文信息,每个阶段的网络使用的卷积核尺寸都比较大,随着网络的深度增加,后续阶段在原图的感受野也越来越大。姿态估计的网络整体结构如图3.5。
W*H。
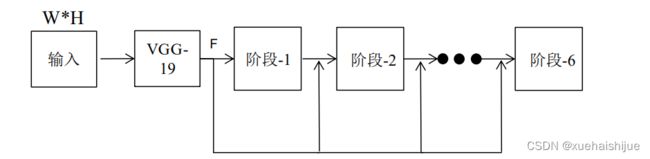
图中,首先一张W*H的图片经过VGG-19的前十层处理,得到图片特征F,然后经过6个阶段进行一个由粗到精的回归。每个阶段后面通过L2损失补充梯度,防止网络过深带来的梯度消失。第一个阶段仅仅处理图片特征F,后续的阶段则处理图片特征F和来自前一个阶段的结果,进行深层和浅层的特征融合。每个阶段的具体结构如图所示。
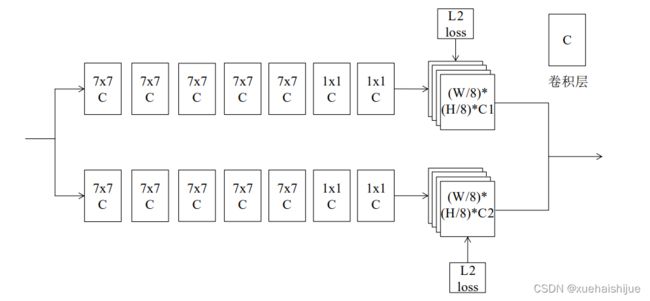
图中,遵循自下而上的原则,每个阶段都输出两个分支。第一个分支预测关键点置信图,输出大小为(W/8)(H/8)C1,C1表示关键点的数量,一个部位占一个通道,特征图上某个位置的值就表示该像素是该部位的概率。第二个分支预测部位关系图,输出大小为(W/8)(H/8)(C2*2),C2是定义的肢体的数量,每段肢体由两个特征图表示,一个表示肢体的x方向,一个表示y方向,两个特征图相同位置的像素就能够组成一个二维向量,表示肢体在该像素的方向。第一个分支预测出所有人的关键点位置,但是不知道那些关键点属于同一个人,第二个分支通过肢体的方向可以将关键点匹配连接,进而得到多个人关键点骨架。
本文使用姿态估计的方法得到学生的骨骼关键点坐标,由于人体骨骼结构空间关系,在后续阶段中,容易检测的身体部位比如肩膀、脖子有助于定位难检测的部位比如手肘、膝盖。
8.举手手势识别算法
在本文介绍了举手识别的国内外研究现状,将举手作为一个动作序列进行建模,或者直接在图像中找出举手的状态。而手势识别不同,主要应用于人机交互,着重于对手掌的分析,判断手掌是剪刀手、握拳等手势。
目前有很多文章对手势识别的领域进行了研究,一类方法是先将手部区域分割出来,Pisharady 等人[3提出了一种在杂乱环境下识别手势的方法,利用贝叶斯模型把手分割出来,提取手部的形状和纹理特征,最后用SVM分类器进行分类。另一类是基于深度学习的方法,Oyedotun 和 Khashman4利用卷积神经网络和堆叠去噪自动编码器(SDAE)识别24种美国手语(ASL)手势,Liang 等人[5l提出了一种用于使用点云识别手势的多视角框架,他们使用卷积神经网络作特征提取器,最终用SVM分类器区分手势。
从上述论文方法中可以看出,手势识别本质上是提取以手掌为主体的图片的特征,并对特征进行分类。而通过姿态估计可以得到手掌的区域,本文通过姿态估计得到了学生的身体关键点坐标之后,我们用关键点的坐标来推测前臂包括手掌的位置,通过关键点的逻辑关系定义手臂抬起的动作,然后得到估计的区域,这些区域包含了我们想要的举手情况和一些比如摸脸、托腮、拍手等非举手的情况,本文称之为举手候选区域。然后需要对这些区域进行特征的提取和分类,我们选择卷积神经网络作为分类器,训练一个二分类模型,来区分这些区域是举手还是非举手。
网络设计
为了区分候选区域中抬手、托腮的负样本和举手正样本的差别,本文设计了一个简单的分类网络,网络结构如图所示。

我们将输入的候选区域大小统一缩放成宽40像素,高80像素的尺寸,网络总共包含6个核大小为3x3的卷积层(Convolution),4个2x2的最大池化层(MaxPooling)和2个全连接层(FullyConnected)。卷积层通过填充操作能够更多利用图片边缘的信息,我们对每个3x3的卷积使用1个像素的填充保持图片大小不变,在每个卷积层后添加批归一化层(BatchNorm,BN),加快网络的收敛速度,减少权重初始化带来的影响。池化可以增加网络对于目标的平移不变性,然后缩小特征图的分辨率,使得相同大小的卷积核有更大的感受野。我们在分辨率下降的同时增加网络的宽度,将通道数增大,把空间的信息转换成高阶的抽象信息,同时在第一个全连接层后面添加了Dropout层,Dropout概率为0.5,增加网络泛化能力。第二个全连接层输出维度是2,经过Softmax 将特征向量转换为概率值,两个维度表示举手和非举手的概率,当举手的概率超过我们设定的阈值就认为这个候选区域是举手。
9.关键点的检测和集成
由于网络是全卷积网络,我们可以将任意大小的图片作为输入送进网络中进行前向传播,如果对图片进行了缩放,则需要将网络的预测结果进行相应的缩放来匹配原图。
网络的第二个分支预测部位关系图,我们定义了13段肢体,所以输出的部位关系图有26个通道,一段肢体占用两个通道的特征图。比如右肩到右肘这一段肢体的部位关系图,我们可以用L_X和L_Y两个特征图表示,L_X记录x方向的坐标,L_Y记录y方向的坐标,对图片中的一个像素点p,L_X§表示位置p的横坐标,L_Y(p表示位置p 的纵坐标,所以结合起来形成的二维向量(L_X§,L_Y§)就表示右肩到右肘这段肢体在位置p的预测方向。
置信图上得到的jl到j2单位向量的内积之和作为这段肢体的一个评侨分议由l代错误的肢体上(比如一个人的右肩和另一个人的右肘),由部位关系图预测的10个点方向与肢体方向不同,所以预测的分数接近于О或者是负数,而正确的肢体(同一个人的右肩和右肘)上的10个点会和肢体方向内积出一个正的分数,并且分数越高说明肢体的置信度越高。
手用KT作值作为这段肢体的分数。在所有筛选出来的肢体中,我们按照肢体的分数从高到低女连共用同一段肢体,并且我们之前对所有部位设置了全局唯一的编号,所以分数敢凯的肢体两端的序号不能再被使用,在其他序号没有重复的肢体中选出分数最高的那一段肢体,作为第二个筛选出来的肢体,剩下的筛选过程以此类推,直到筛选出来的肢体个数等于右肩和右肘个数的较小值,示意图展示了筛选过程。

所有的右肩右肘两两相连得到所有的肢体,红色的点检测到的右肩,绿色的点表示检测到的右肘,假如肢体AF分数最高,先将AF筛选出来,为了避免不同的人共用一段肢体,不再使用和AF有关的肢体,如图,再在剩下的六段肢体(BD,BE,BG,CD,CE,CG)中筛选分数最高的那段肢体,假如是 BD,筛选后的情况如图,最后在(CE,CG)两段肢体中选出分数较高的那一段肢体,比如CE,最后剩下的关键点G则丢弃。所以在这张图中,筛选出了3段右肩和右肘组成的肢体,即图中有三个人有这一段肢体。
现在我们判断出了右肩和右肘组成的肢体的情况,同理可以得到右肘和右腕组成的肢体的情况,我们知道AF,BD,CE是正确的右肩右肘肢体,那么在右肘右腕的肢体中,我们只要寻找右肘编号为F,D,E的那三段肢体就可以了,以此类推可以知道每个人的肢体连接情况。我们的推断是按照顺序进行,手腕依赖于手肘,手肘依赖于肩膀,肩膀依赖脖子等,所以最终可以组成一个人的完整或者部分骨架。集成的结果如图所示。

10.系统整合
下图完整源码&环境部署视频教程&自定义UI界面

参考博客《基于深度学习的课堂举手人数统计系统》
11.参考文献
[1]Tsung-Yi,Lin,Priyal,Goyal,Ross,Girshick,等.Focal loss for dense object detection.[J].IEEE Transactions on Pattern Analysis & Machine Intelligence.2018,(Spec).DOI:10.1109/TPAMI.2018.2858826 .
[2]Khashman, Adnan,Oyedotun, Oyebade K..Deep learning in vision-based static hand gesture recognition[J].Neural computing & applications.2017,28(12).
[3]Pramod Kumar Pisharady,Ai Poh Loh,Prahlad Vadakkepat.Attention Based Detection and Recognition of Hand Postures Against Complex Backgrounds[J].International Journal of Computer Vision.2013,101(3).403-419.
[4]Duchi, John,Hazan, Elad,Singer, Yoram.Adaptive Subgradient Methods for Online Learning and Stochastic Optimization.[J].Journal of Machine Learning Research.2011,12(7).2121-2159.
[5]J. Kiefer,J. Wolfowitz.Stochastic Estimation of the Maximum of a Regression Function[J].The Annals of Mathematical Statistics.1952,23(3).462-466.
[6]Toshev, Alexander,Szegedy, Christian.DeepPose: Human Pose Estimation via Deep Neural Networks[C].2014.
[7]Tsung-Yi Lin,Michael Maire,Serge Belongie,等.Microsoft COCO: Common Objects in Context[C].2014.
[8]Ladicky, Lubor,Torr, Philip H.S.,Zisserman, Andrew.Human Pose Estimation Using a Joint Pixel-wise and Part-wise Formulation[C].2013.
[9]Suarez, Jesus,Murphy, Robin R..Hand gesture recognition with depth images: A review[C].2012.
[10]Zhou Ren,Jingjing Meng,Junsong Yuan,等.Robust Hand Gesture Recognition with Kinect Sensor[C].2011.