深度学习 Day15——P4猴痘病识别
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊 | 接辅导、项目定制
文章目录
- 前言
- 1 我的环境
- 2 代码实现与执行结果
-
- 2.1 前期准备
-
- 2.1.1 引入库
- 2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
- 2.1.3 导入数据
- 2.1.4 可视化数据
- 2.1.4 图像数据变换
- 2.1.4 划分数据集
- 2.1.4 加载数据
- 2.1.4 查看数据
- 2.2 构建CNN网络模型
- 2.3 训练模型
-
- 2.3.1 设置超参数
- 2.3.2 编写训练函数
- 2.3.3 编写测试函数
- 2.3.4 正式训练
- 2.4 结果可视化
- 2.4 指定图片进行预测
- 2.6 保存并加载模型
- 3 知识点详解
-
- 3.1 torch.utils.data.DataLoader()参数详解
- 3.2 torch.squeeze()与torch.unsqueeze()详解
- 3.3 拔高尝试--更改优化器为Adam
- 3.4 拔高尝试--更改优化器为Adam+增加dropout层
- 3.5 拔高尝试--更改优化器为Adam+增加dropout层+保存最好的模型
- 总结
前言
本文将采用pytorch框架创建CNN网络,实现猴痘病识别。讲述实现代码与执行结果,并浅谈涉及知识点。
关键字: torch.utils.data.DataLoader()参数详解,torch.squeeze()与torch.unsqueeze()详解,拔高尝试–更改优化器为Adam,增加dropout层,保存最好的模型
1 我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:
torch == 1.9.1+cu111
torchvision == 0.10.1+cu111 - 显卡:NVIDIA GeForce RTX 4070
2 代码实现与执行结果
2.1 前期准备
2.1.1 引入库
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import time
from pathlib import Path
from PIL import Image
from torchinfo import summary
import torch.nn.functional as F
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
"""前期准备-设置GPU"""
# 如果设备上支持GPU就使用GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))
输出
Using cuda device
2.1.3 导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\monkeypox_recognition"
data_dir = Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
print(classeNames)
输出
['Monkeypox', 'Others']
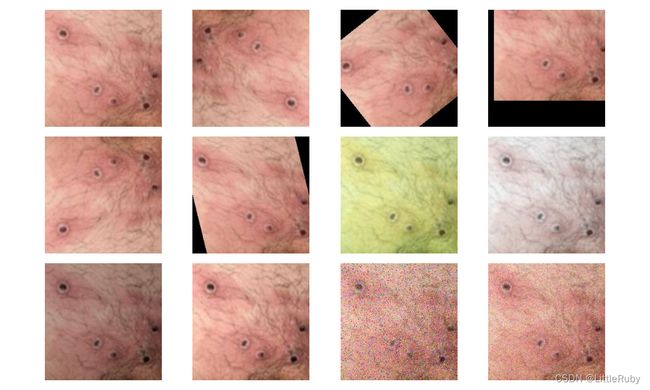
2.1.4 可视化数据
'''前期工作-可视化数据'''
cloudyPath = Path(data_dir)/"Monkeypox"
image_files = list(p.resolve() for p in cloudyPath.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])
plt.figure(figsize=(10, 6))
for i in range(len(image_files[:12])):
image_file = image_files[i]
ax = plt.subplot(3, 4, i + 1)
img = Image.open(str(image_file))
plt.imshow(img)
plt.axis("off")
# 显示图片
plt.tight_layout()
plt.show()
2.1.4 图像数据变换
'''前期工作-图像数据变换'''
total_datadir = data_dir
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
输出
Dataset ImageFolder
Number of datapoints: 2142
Root location: D:\DeepLearning\data\monkeypox_recognition
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
{'Monkeypox': 0, 'Others': 1}
2.1.4 划分数据集
'''前期工作-划分数据集'''
train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。
# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,
# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))
print("train_size={}\ntest_size={}".format(train_size, test_size))
输出
train_dataset=
test_dataset=
train_size=1713
test_size=429
2.1.4 加载数据
'''前期工作-加载数据'''
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
2.1.4 查看数据
'''前期工作-查看数据'''
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
输出
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
2.2 构建CNN网络模型

"""构建CNN网络"""
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2, 2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24 * 50 * 50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24 * 50 * 50)
x = self.fc1(x)
return x
model = Network_bn().to(device)
print(model)
summary(model)
输出
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=60000, out_features=2, bias=True)
)
=================================================================
Layer (type:depth-idx) Param #
=================================================================
Network_bn --
├─Conv2d: 1-1 912
├─BatchNorm2d: 1-2 24
├─Conv2d: 1-3 3,612
├─BatchNorm2d: 1-4 24
├─MaxPool2d: 1-5 --
├─Conv2d: 1-6 7,224
├─BatchNorm2d: 1-7 48
├─Conv2d: 1-8 14,424
├─BatchNorm2d: 1-9 48
├─Linear: 1-10 120,002
=================================================================
Total params: 146,318
Trainable params: 146,318
Non-trainable params: 0
=================================================================
2.3 训练模型
2.3.1 设置超参数
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(), lr=learn_rate) # 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大
2.3.2 编写训练函数
"""训练模型--编写训练函数"""
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)
X, y = X.to(device), y.to(device) # 用于将数据存到显卡
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # 清空过往梯度
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
2.3.3 编写测试函数
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()#统计预测正确的个数
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
2.3.4 正式训练
"""训练模型--正式训练"""
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
输出
Epoch: 1, duration:7062ms, Train_acc:59.7%, Train_loss:0.679, Test_acc:62.5%,Test_loss:0.651
Epoch: 2, duration:5408ms, Train_acc:68.9%, Train_loss:0.580, Test_acc:66.4%,Test_loss:0.650
Epoch: 3, duration:5328ms, Train_acc:74.2%, Train_loss:0.543, Test_acc:67.8%,Test_loss:0.630
Epoch: 4, duration:5345ms, Train_acc:77.6%, Train_loss:0.493, Test_acc:68.5%,Test_loss:0.575
Epoch: 5, duration:5340ms, Train_acc:77.8%, Train_loss:0.471, Test_acc:74.6%,Test_loss:0.565
Epoch: 6, duration:5295ms, Train_acc:81.8%, Train_loss:0.435, Test_acc:73.2%,Test_loss:0.555
Epoch: 7, duration:5309ms, Train_acc:83.1%, Train_loss:0.418, Test_acc:74.8%,Test_loss:0.517
Epoch: 8, duration:5268ms, Train_acc:85.4%, Train_loss:0.392, Test_acc:76.9%,Test_loss:0.504
Epoch: 9, duration:5395ms, Train_acc:85.8%, Train_loss:0.374, Test_acc:77.6%,Test_loss:0.490
Epoch:10, duration:5346ms, Train_acc:87.9%, Train_loss:0.356, Test_acc:76.0%,Test_loss:0.498
Epoch:11, duration:5297ms, Train_acc:88.3%, Train_loss:0.336, Test_acc:77.6%,Test_loss:0.464
Epoch:12, duration:5291ms, Train_acc:89.6%, Train_loss:0.323, Test_acc:78.1%,Test_loss:0.470
Epoch:13, duration:5259ms, Train_acc:89.7%, Train_loss:0.311, Test_acc:78.6%,Test_loss:0.475
Epoch:14, duration:5343ms, Train_acc:90.3%, Train_loss:0.295, Test_acc:80.0%,Test_loss:0.443
Epoch:15, duration:5363ms, Train_acc:90.5%, Train_loss:0.295, Test_acc:78.1%,Test_loss:0.442
Epoch:16, duration:5305ms, Train_acc:91.2%, Train_loss:0.284, Test_acc:79.5%,Test_loss:0.427
Epoch:17, duration:5279ms, Train_acc:91.5%, Train_loss:0.270, Test_acc:79.5%,Test_loss:0.421
Epoch:18, duration:5356ms, Train_acc:92.8%, Train_loss:0.259, Test_acc:80.7%,Test_loss:0.426
Epoch:19, duration:5284ms, Train_acc:91.9%, Train_loss:0.251, Test_acc:80.2%,Test_loss:0.427
Epoch:20, duration:5274ms, Train_acc:92.6%, Train_loss:0.255, Test_acc:80.4%,Test_loss:0.440
Done
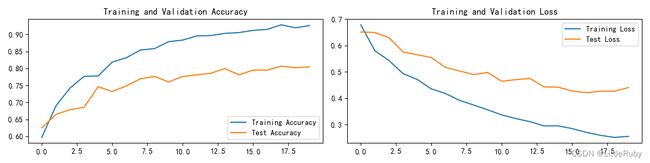
2.4 结果可视化
"""训练模型--结果可视化"""
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2.4 指定图片进行预测
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
plt.show()
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
classes = l
ist(total_data.class_to_idx)
# 预测训练集中的某张照片
predict_one_image(image_path=str(Path(data_dir)/"Monkeypox"/"M01_01_00.jpg"),
model=model,
transform=train_transforms,
classes=classes)
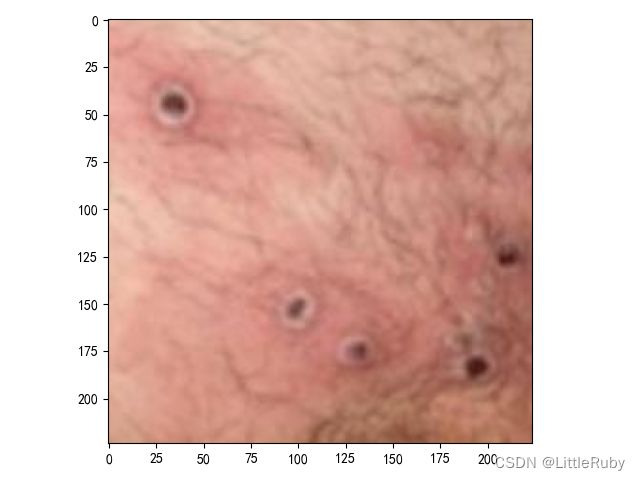
输出
预测结果是:Monkeypox
2.6 保存并加载模型
"""保存并加载模型"""
# 模型保存
PATH = './model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
3 知识点详解
3.1 torch.utils.data.DataLoader()参数详解
torch.utils.data.DataLoader 是 PyTorch 中用于加载和管理数据的一个实用工具类。它允许你以小批次的方式迭代你的数据集,这对于训练神经网络和其他机器学习任务非常有用。DataLoader 构造函数接受多个参数,下面是一些常用的参数及其解释:
dataset(必需参数):这是你的数据集对象,通常是 torch.utils.data.Dataset 的子类,它包含了你的数据样本。batch_size(可选参数):指定每个小批次中包含的样本数。默认值为 1。shuffle(可选参数):如果设置为 True,则在每个 epoch 开始时对数据进行洗牌,以随机打乱样本的顺序。这对于训练数据的随机性很重要,以避免模型学习到数据的顺序性。默认值为 False。num_workers(可选参数):用于数据加载的子进程数量。通常,将其设置为大于 0 的值可以加快数据加载速度,特别是当数据集很大时。默认值为 0,表示在主进程中加载数据。pin_memory(可选参数):如果设置为 True,则数据加载到 GPU 时会将数据存储在 CUDA 的锁页内存中,这可以加速数据传输到 GPU。默认值为 False。drop_last(可选参数):如果设置为 True,则在最后一个小批次可能包含样本数小于 batch_size 时,丢弃该小批次。这在某些情况下很有用,以确保所有小批次具有相同的大小。默认值为 False。timeout(可选参数):如果设置为正整数,它定义了每个子进程在等待数据加载器传递数据时的超时时间(以秒为单位)。这可以用于避免子进程卡住的情况。默认值为 0,表示没有超时限制。worker_init_fn(可选参数):一个可选的函数,用于初始化每个子进程的状态。这对于设置每个子进程的随机种子或其他初始化操作很有用。
3.2 torch.squeeze()与torch.unsqueeze()详解
torch.squeeze()
对数据的维度进行压缩,去掉维数为1的的维度
函数原型
torch.squeeze(input, dim=None, *, out=None)
关键参数
● input (Tensor):输入Tensor
● dim (int, optional):如果给定,输入将只在这个维度上被压缩
实战案例
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0)
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])
torch.unsqueeze()
对数据维度进行扩充。给指定位置加上维数为一的维度
函数原型
torch.unsqueeze(input, dim)
关键参数说明:
●input (Tensor):输入Tensor
●dim (int):插入单例维度的索引
实战案例:
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
3.3 拔高尝试–更改优化器为Adam
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
训练过程如下
Epoch: 1, duration:8545ms, Train_acc:62.6%, Train_loss:0.822, Test_acc:61.3%,Test_loss:0.622
Epoch: 2, duration:5357ms, Train_acc:77.5%, Train_loss:0.462, Test_acc:80.0%,Test_loss:0.448
Epoch: 3, duration:5594ms, Train_acc:85.0%, Train_loss:0.340, Test_acc:79.3%,Test_loss:0.417
Epoch: 4, duration:5536ms, Train_acc:89.3%, Train_loss:0.263, Test_acc:80.4%,Test_loss:0.485
Epoch: 5, duration:5387ms, Train_acc:91.8%, Train_loss:0.226, Test_acc:77.2%,Test_loss:0.524
Epoch: 6, duration:5337ms, Train_acc:95.1%, Train_loss:0.175, Test_acc:84.6%,Test_loss:0.388
Epoch: 7, duration:5445ms, Train_acc:96.0%, Train_loss:0.136, Test_acc:86.9%,Test_loss:0.384
Epoch: 8, duration:5413ms, Train_acc:97.1%, Train_loss:0.108, Test_acc:86.7%,Test_loss:0.368
Epoch: 9, duration:5402ms, Train_acc:97.8%, Train_loss:0.094, Test_acc:85.5%,Test_loss:0.374
Epoch:10, duration:5360ms, Train_acc:98.6%, Train_loss:0.077, Test_acc:87.4%,Test_loss:0.370
Epoch:11, duration:5327ms, Train_acc:99.1%, Train_loss:0.057, Test_acc:86.2%,Test_loss:0.389
Epoch:12, duration:5432ms, Train_acc:99.5%, Train_loss:0.044, Test_acc:84.1%,Test_loss:0.500
Epoch:13, duration:5385ms, Train_acc:99.5%, Train_loss:0.043, Test_acc:86.2%,Test_loss:0.399
Epoch:14, duration:5419ms, Train_acc:99.8%, Train_loss:0.031, Test_acc:86.9%,Test_loss:0.400
Epoch:15, duration:5375ms, Train_acc:99.8%, Train_loss:0.025, Test_acc:86.9%,Test_loss:0.380
Epoch:16, duration:5373ms, Train_acc:99.9%, Train_loss:0.023, Test_acc:87.6%,Test_loss:0.374
Epoch:17, duration:5383ms, Train_acc:99.8%, Train_loss:0.023, Test_acc:88.8%,Test_loss:0.390
Epoch:18, duration:5398ms, Train_acc:99.9%, Train_loss:0.021, Test_acc:88.1%,Test_loss:0.425
Epoch:19, duration:5491ms, Train_acc:99.9%, Train_loss:0.020, Test_acc:87.6%,Test_loss:0.393
Epoch:20, duration:5405ms, Train_acc:99.9%, Train_loss:0.015, Test_acc:87.2%,Test_loss:0.400
acc与loss图如下,测试精度最高达到88.8%

3.4 拔高尝试–更改优化器为Adam+增加dropout层
在更改优化器为Adam代码的基础上,修改网络模型结构,提升测试精度
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2, 2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.dropout = nn.Dropout(p=0.5)
self.fc1 = nn.Linear(24 * 50 * 50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = self.dropout(x)
x = x.view(-1, 24 * 50 * 50)
x = self.fc1(x)
return x
训练过程如下
Epoch: 1, duration:7376ms, Train_acc:62.3%, Train_loss:0.812, Test_acc:69.7%,Test_loss:0.576
Epoch: 2, duration:5362ms, Train_acc:75.0%, Train_loss:0.522, Test_acc:77.4%,Test_loss:0.470
Epoch: 3, duration:5439ms, Train_acc:84.5%, Train_loss:0.369, Test_acc:78.3%,Test_loss:0.418
Epoch: 4, duration:5418ms, Train_acc:87.6%, Train_loss:0.305, Test_acc:84.4%,Test_loss:0.369
Epoch: 5, duration:5422ms, Train_acc:90.6%, Train_loss:0.253, Test_acc:83.0%,Test_loss:0.377
Epoch: 6, duration:5418ms, Train_acc:92.1%, Train_loss:0.215, Test_acc:87.6%,Test_loss:0.334
Epoch: 7, duration:5414ms, Train_acc:92.4%, Train_loss:0.196, Test_acc:86.5%,Test_loss:0.343
Epoch: 8, duration:5373ms, Train_acc:95.6%, Train_loss:0.140, Test_acc:84.4%,Test_loss:0.454
Epoch: 9, duration:5403ms, Train_acc:96.4%, Train_loss:0.125, Test_acc:87.2%,Test_loss:0.331
Epoch:10, duration:5402ms, Train_acc:96.8%, Train_loss:0.111, Test_acc:87.9%,Test_loss:0.300
Epoch:11, duration:5448ms, Train_acc:98.0%, Train_loss:0.081, Test_acc:89.5%,Test_loss:0.293
Epoch:12, duration:5394ms, Train_acc:98.4%, Train_loss:0.073, Test_acc:89.0%,Test_loss:0.314
Epoch:13, duration:5444ms, Train_acc:98.5%, Train_loss:0.064, Test_acc:88.6%,Test_loss:0.352
Epoch:14, duration:5400ms, Train_acc:98.0%, Train_loss:0.074, Test_acc:89.7%,Test_loss:0.322
Epoch:15, duration:5396ms, Train_acc:98.9%, Train_loss:0.052, Test_acc:89.7%,Test_loss:0.329
Epoch:16, duration:5519ms, Train_acc:99.0%, Train_loss:0.045, Test_acc:86.2%,Test_loss:0.397
Epoch:17, duration:5374ms, Train_acc:99.2%, Train_loss:0.038, Test_acc:90.2%,Test_loss:0.302
Epoch:18, duration:5464ms, Train_acc:99.3%, Train_loss:0.037, Test_acc:91.1%,Test_loss:0.314
Epoch:19, duration:5668ms, Train_acc:98.6%, Train_loss:0.054, Test_acc:88.3%,Test_loss:0.341
Epoch:20, duration:5540ms, Train_acc:99.6%, Train_loss:0.029, Test_acc:90.2%,Test_loss:0.308
acc与loss图如下,测试精度最高达到91.1%
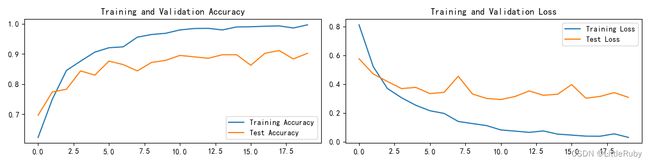
3.5 拔高尝试–更改优化器为Adam+增加dropout层+保存最好的模型
在更改优化器为Adam+增加dropout层代码的基础上在训练模型阶段增加部分代码,保存最好的模型,预测前加载模型
"""训练模型--正式训练"""
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_test_acc=0
PATH = './model.pth' # 保存的参数文件名
for epoch in range(epochs):
milliseconds_t1 = int(time.time() * 1000)
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
milliseconds_t2 = int(time.time() * 1000)
template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
if best_test_acc < epoch_test_acc:
best_test_acc = epoch_test_acc
# 模型保存
torch.save(model.state_dict(), PATH)
template = (
'Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f},save model.pth')
print(
template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
训练记录如下
Epoch: 1, duration:7342ms, Train_acc:61.6%, Train_loss:0.837, Test_acc:68.3%,Test_loss:0.796,save model.pth
Epoch: 2, duration:5390ms, Train_acc:75.4%, Train_loss:0.524, Test_acc:77.6%,Test_loss:0.472,save model.pth
Epoch: 3, duration:5348ms, Train_acc:82.4%, Train_loss:0.417, Test_acc:84.6%,Test_loss:0.411,save model.pth
Epoch: 4, duration:5377ms, Train_acc:85.1%, Train_loss:0.351, Test_acc:82.3%,Test_loss:0.424
Epoch: 5, duration:5362ms, Train_acc:85.7%, Train_loss:0.326, Test_acc:83.7%,Test_loss:0.426
Epoch: 6, duration:5371ms, Train_acc:88.3%, Train_loss:0.270, Test_acc:84.6%,Test_loss:0.353
Epoch: 7, duration:5426ms, Train_acc:92.6%, Train_loss:0.199, Test_acc:89.0%,Test_loss:0.320,save model.pth
Epoch: 8, duration:5432ms, Train_acc:89.7%, Train_loss:0.256, Test_acc:83.0%,Test_loss:0.478
Epoch: 9, duration:5447ms, Train_acc:93.1%, Train_loss:0.189, Test_acc:85.5%,Test_loss:0.395
Epoch:10, duration:5630ms, Train_acc:95.2%, Train_loss:0.133, Test_acc:87.4%,Test_loss:0.316
Epoch:11, duration:5469ms, Train_acc:95.2%, Train_loss:0.127, Test_acc:87.2%,Test_loss:0.352
Epoch:12, duration:5366ms, Train_acc:96.3%, Train_loss:0.106, Test_acc:90.0%,Test_loss:0.328,save model.pth
Epoch:13, duration:5543ms, Train_acc:97.3%, Train_loss:0.085, Test_acc:88.6%,Test_loss:0.284
Epoch:14, duration:5500ms, Train_acc:97.4%, Train_loss:0.084, Test_acc:89.3%,Test_loss:0.299
Epoch:15, duration:5398ms, Train_acc:97.9%, Train_loss:0.068, Test_acc:90.2%,Test_loss:0.269,save model.pth
Epoch:16, duration:5436ms, Train_acc:98.4%, Train_loss:0.056, Test_acc:88.8%,Test_loss:0.282
Epoch:17, duration:5447ms, Train_acc:99.1%, Train_loss:0.050, Test_acc:87.6%,Test_loss:0.325
Epoch:18, duration:5483ms, Train_acc:97.7%, Train_loss:0.067, Test_acc:89.5%,Test_loss:0.294
Epoch:19, duration:5431ms, Train_acc:98.7%, Train_loss:0.046, Test_acc:90.2%,Test_loss:0.298
Epoch:20, duration:5553ms, Train_acc:99.4%, Train_loss:0.032, Test_acc:90.7%,Test_loss:0.278,save model.pth
总结
通过本文的学习,pytorch实现猴痘病识别,并通过改变优化器的方式,以及增加dropout层,提升了原有模型的测试精度,并保存训练过程中最好的模型。