深入探索 Amazon DynamoDB
关键字: [Amazon Web Services re:Invent 2023, DynamoDB, Dynamodb Scaling, Dynamodb On-Demand, Dynamodb Rate Limiting, Dynamodb Transactions, Dynamodb Isolation Levels, Dynamodb Streams, Dynamodb Sharding, Dynamodb Global Tables]
本文字数: 1200, 阅读完需: 6 分钟
视频
如视频不能正常播放,请前往bilibili观看本视频。>> https://www.bilibili.com/video/BV1hG411q7LQ
导读
本次讲座将深入探讨 Amazon DynamoDB,并分享有关于如何构建 DynamoDB 架构,以实现客户期望的可扩展性和响应时间的见解。了解热门功能,如按需容量、全局表、DynamoDB Streams 和事务等流行功能的工作原理,以及如何在您的工作负载中更好地利用它们。
演讲精华
以下是小编为您整理的本次演讲的精华,共900字,阅读时间大约是4分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
高级首席工程师阿姆里,拥有超过30年的数据库经验,登上了讲台,深入探讨亚马逊的DynamoDB。阿姆里在4年前加入了DynamoDB团队,他投入大量时间与客户直接接触,了解他们在数据方面所面临的挑战以及他们对服务的期望。
在会议开始时,阿姆里向观众们询问了他们的工作背景。许多与会者表示他们来自SQL领域,这让阿姆里感到非常亲切。当他首次加入DynamoDB团队时,缺乏类似SQL的界面曾是一个初始难题。为了解决这个问题,阿姆里为DynamoDB设计了自家的查询界面,并公开了源代码,用户可通过QR码获取,以便任何感兴趣的人都能够参与其中并提出建议。
进入正题前,阿姆里先解决了一个常见问题:在迁移到DynamoDB的过程中,他经常听到一个问题——我们的流量需求能应对得了吗?为了消除疑虑,他分享了一些关于DynamoDB的惊人数据。这个完全托管的无服务器服务在所有客户之间共享资源,这意味着新应用程序可以立即享受到经过实战测试的基础设施的好处。具体的数据展示了DynamoDB所能承受的惊人峰值——单个客户最高可承受每秒50万次请求,总体每小时可承受数十亿次请求。
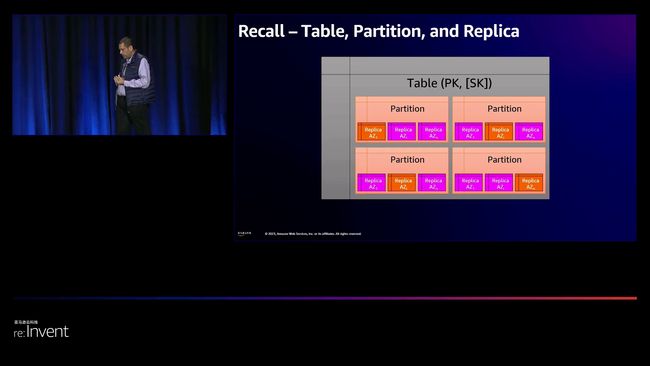
在确认DynamoDB能够应对庞大的工作负载之后,阿姆里转向了第一个关键话题——解释DynamoDB是如何进行扩展的。他简要介绍了简单的表结构——只需指定名称、主键和计费模式。主键的分区键元素决定了数据的分布,每个分区大约包含10GB的数据。DynamoDB的水平扩展源于这种分区设计,将每个分区的多个副本存储在不同的可用区域中,以确保高持久性。
为了应对高请求量,DynamoDB采用了分区策略来分散负载。例如,一个表可能拥有500个分区,每个分区每秒处理1000个请求,而非一个分区每秒处理500000个请求。这种分区策略是基于表的配置和实际的流量模式自动处理的,无需客户进行任何手动操作。
话题转换到DynamoDB的两种容量模式:按需和预配置。按需模式是根据客户需求而产生的,使得DynamoDB能够完全托管。然而,预配置容量则需要客户指定读取和写入级别,这可能难以准确估计和管理。按需计费模型通过根据实际工作负载自动调整容量大小来解决这个问题。
为了展示按需模式的优点,阿姆里通过示例流量模式进行了解释。对于具有重大尖峰工作负载的应用程序,按需模式可以透明地处理高达之前峰值两倍的请求。在超过两倍的情况下,可能会出现一些节流现象,但由于客户只需为其使用的部分付费,因此无需过度分配以避免任何节流现象。阿姆里还介绍了全局准入控制如何提供对实时流量级别的细粒度可见性,从而允许预先采取分区分割等措施。
关于事务功能,阿姆里强调,尽管DynamoDB是一个NoSQL数据库,但许多应用程序仍然需要跨多个项目执行原子更新。DynamoDB的ACID事务正是提供了这种支持,并通过严格的串行化隔离确保了可预测且可扩展的性能。
在内部,两个阶段提交协议协调跨分区的事务。与传统RDBMS不同,DynamoDB在执行此操作时无需分布式锁定以及相关的性能问题。阿姆里还澄清说,事务使用单个请求模型,而不是开始/结束模式。这保留了所有事务保证,同时确保可扩展性。对于担心崩溃恢复情况的客户,幂等性令牌提供了一次执行的事务保证。
阿姆里在讨论DynamoDB的流技术时,详细阐述了如何利用这些技术构建响应数据更改的事件驱动应用程序。流具有两个关键特性:严格顺序和每个项目仅处理一次。为了支持高吞吐量应用,流采用了分片技术。随着流量的增长,分片会在实例间动态地进行分割和重新平衡。阿姆里强调,应用程序不能假设固定的分片数量或模式。
在总结全局表部分时,阿姆里解释了客户如何通过本地DynamoDB资源为跨地区的用户提供服务的需求。全局表通过自动化的多区域复制和同步来满足这一要求,从而降低了复杂应用管理数据分布的负担。
对于冲突解决,全局表采用“最后写入者获胜”的策略。尽管复制延迟意味着在技术上可能存在最终一致性,但更改在一秒内跨地区传播。阿姆里提到的一个特殊情况是,各地区之间连续进行的项更新可能导致在达到一致性之前,流事件出现轻微的分歧。
总的来说,阿姆里总结了在整个深入探讨中提到的DynamoDB的关键设计原则。这个完全管理的无服务器服务可以轻松扩展到任何工作负载,同时提供可预测的毫秒级性能。DynamoDB通过内部处理巨大的规模挑战,使客户能够专注于他们的核心应用程序和业务逻辑。阿姆里鼓励与会者提供反馈,以围绕感兴趣的主题塑造未来的深入探讨。
下面是一些演讲现场的精彩瞬间:
亚马逊云科技推出了一项名为单请求事务的功能,该功能可以在无需分布式锁管理器的情况下实现可预测的响应时间。

行业领导者们强调了DynamoDB如何不断优化自身,通过利用副本实现读取、写入、恢复和快照等功能,同时始终致力于提供可预测的响应时间。
领导者们解释称,Amazon Kinesis数据流如何通过分片和分片分割来应对不断增长的数据摄入速率,并在实例之间实现负载均衡,从而在高可扩展性和吞吐量的前提下不影响客户体验。

DynamoDB采用了最终一致性原则,即最新的写入操作将被优先处理,且时间总是呈现出前进的趋势。

此外,还介绍了两篇关于构建可扩展数据库以及在其中实施事务的已发表的研究论文。

总结
亚马逊DynamoDB是一款完全托管的无服务器NoSQL数据库,能在任何规模上提供可预测的性能。近期,DynamoDB的高级工程师阿姆里进行了一场深入的演讲,揭示了DynamoDB的内部运作原理。
他首先向观众保证,DynamoDB可以轻松处理巨大的流量——其最大客户的一些需求甚至可以达到每秒500,000次请求。DynamoDB通过将数据分成分区来水平扩展,目标是使每个分区的大小保持在约10GB。为了实现高可用性和耐用性,数据在可用性区域之间进行复制。一个名为全局准入控制的分布式速率限制系统有助于确保无论流量如何波动,都能保持一致的低延迟性能。
按需容量模式被创建来处理最近的峰值2倍以上的不可预测的工作负载和流量突发。在幕后,DynamoDB使用预占数据分区和自适应负载平衡来维护性能。一旦了解了流量模式,预分配容量可能对于可预测的工作负载更具成本效益。
DynamoDB支持用于原子地更新多个项目的ACID事务。它提供了可串行的隔离性,尽管单个读取/写入操作不是事务性的。事务使用两阶段提交,并使用像单请求事务这样的优化来避免分布式锁定和不稳定的延迟。流支持用于构建事件驱动的应用程序,提供强大的排序和确切一次交付保证。
全局表通过跨地区解决复制和冲突来解决简化全局分布应用程序的构建。写操作在地区之间最终是一致的,大部分复制延迟低于一秒。
总的来说,通过创新如自适应扩展、事务、流和全局表,DynamoDB提供了诸如性能、可扩展性、一致性和高可用性等重要数据库特性,这些特性完全由DynamoDB管理,使得开发人员可以专注于他们的应用程序。
演讲原文
https://blog.csdn.net/littlechenlin/article/details/134800635
想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
2023亚马逊云科技re:Invent全球大会 - 官方网站
点击此处,一键获取亚马逊云科技全球最新产品/服务资讯!
点击此处,一键获取亚马逊云科技中国区最新产品/服务资讯!
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技“100 余种核心云服务产品免费试用”
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。
