Python爬取苏宁易购商品数据并作可视化
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
环境介绍:
-
python 3.8
-
pycharm 专业版
-
selenium
-
谷歌浏览器
-
浏览器驱动
数据获取代码
导入模块
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import csv
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
with open('苏宁.csv', mode='w', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['title', 'price', 'comment_count', 'store_stock', 'img_url', 'href'])
- 打开谷歌浏览器
driver = webdriver.Chrome()
- 打开一个网页
driver.get('https://search.suning.com/iPhone/')
for page in range(33):
time.sleep(1)
- 下拉页面
driver.execute_script('document.querySelector("body > div.ng-footer > div.ng-s-footer").scrollIntoView()')
time.sleep(1)
driver.execute_script('document.querySelector("body > div.ng-footer > div.ng-s-footer").scrollIntoView()')
time.sleep(1)
- 提取数据
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
divs = driver.find_elements(By.CSS_SELECTOR, '.product-box')
for div in divs:
title = div.find_element(By.CSS_SELECTOR, '.title-selling-point').text
price = div.find_element(By.CSS_SELECTOR, '.price-box').text
comment_count = div.find_element(By.CSS_SELECTOR, '.evaluate-old.clearfix').text
store_stock = div.find_element(By.CSS_SELECTOR, '.store-stock').text
img_url = div.find_element(By.CSS_SELECTOR, '.img-block img').get_attribute('src')
href = div.find_element(By.CSS_SELECTOR, '.title-selling-point a').get_attribute("href")
print(title, price, comment_count, store_stock, img_url, href)
- 保存数据
with open('苏宁.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([title, price, comment_count, store_stock, img_url, href])
driver.execute_script('document.querySelector("#nextPage").click()')
数据可视化
import pandas as pd
import jieba
from pyecharts.charts import Bar,Pie
from pyecharts import options as opts
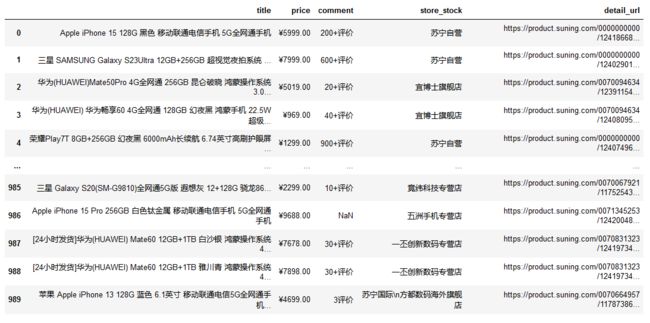
df_tb = pd.read_csv('suning.csv')
df_tb
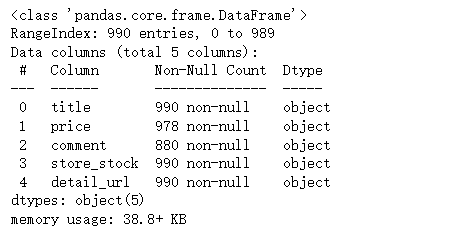
df_tb.info()
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
df_tb['price'] = df_tb['price'].str.replace('¥', '')
df_tb['price'] = df_tb['price'].str.replace('到手价', '')
df_tb['price'] = df_tb['price'].str.replace('\n26.90', '')
df_tb['price'] = df_tb['price'].str.replace('\n1399.00', '')
df_tb['comment'] = df_tb['comment'].str.replace('+', '')
df_tb['comment'] = df_tb['comment'].str.replace('评价', '')
df_tb['comment'] = df_tb['comment'].str.replace('万', '')
df_tb['price'] = df_tb['price'].astype('float64')
df_tb['comment'] = df_tb['comment'].astype('float64')
df_tb.head()
f_tb.groupby('store_stock')['comment'].sum()
shop_top10 = df_tb.groupby('store_stock')['comment'].sum().sort_values(ascending=False).head(10)
shop_top10
#条形图
#bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1 = Bar()
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis('', shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='iphone13排名Top10苏宁店铺'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=28669)
)
bar1.render('1.html')
cut_bins = [0,50,100,200,300,500,1000,8888]
cut_labels = ['0~50元', '50~100元', '100~200元', '200~300元', '300~500元', '500~1000元', '1000元以上']
price_cut = pd.cut(df_tb['price'],bins=cut_bins,labels=cut_labels)
price_num = price_cut.value_counts()
price_num
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
bar3 = Bar()
bar3.add_xaxis(['0~50元', '50~100元', '100~200元', '200~300元', '300~500元', '500~1000元', '1000元以上'])
bar3.add_yaxis('', [895, 486, 701, 288, 370, 411, 260])
bar3.set_global_opts(title_opts=opts.TitleOpts(title='不同价格区间的商品数量'),
visualmap_opts=opts.VisualMapOpts(max_=900))
bar3.render('2.html')
df_tb['price_cut'] = price_cut
cut_purchase = df_tb.groupby('price_cut')['comment'].sum()
cut_purchase
data_pair = [list(z) for z in zip(cut_purchase.index.tolist(), cut_purchase.values.tolist())]
# 绘制饼图
pie1 = Pie()
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='不同价格区间的销售额整体表现'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
pie1.render("3.html")
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
# with open(r"E:\py练习\数据分析\stop_words.txt", 'r', encoding='utf-8') as f:
# lines = f.readlines()
# for line in lines:
# stop_words.append(line.strip())
# 添加关键词
my_words = ['丝袜', '夏天', '女薄款', '一体']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
# my_stop_words = []
# stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
text = get_cut_words(content_series=df_tb['title'])
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,宣传一下呀~更多源码、资料、素材、解答、交流皆点击下方名片获取呀