58、正则表达式
目录
一、快速入门
二、正则表达式基本语法
1、基本介绍:
2、正则表达式底层实现
3、元字符(Metacharacter)- 转义号\\
(1)限定符
(2)选择匹配符
(5)字符匹配符
(6)定位符
三、三个常用类
1、Pattern类
2、Matcher类
3、PatternSyntaxException类
四、分组、捕获、反向引用
1、分组
2、捕获
3、反向引用
五、应用实例
一、快速入门
1、体验正则表达式的威力
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 体验正则表达式的威力
*/
public class Regexp_ {
public static void main(String[] args) {
//假定,编写了爬虫,从百度页面得到如下文本
String content = "正则表达式的“鼻祖”或许可一直追溯到科学家对人类神经系统工作原理的早期研究。" +
"美国新泽西州的Warren McCulloch和出生在美国底特律的Walter Pitts这两位神经生理方面的科学家," +
"研究出了一种用数学方式来描述神经网络的新方法,他们创造性地将神经系统中的神经元描述成了小" +
"而简单的自动控制元,从而作出了一项伟大的工作革新。" +
"在1951 年,一位名叫Stephen Kleene的数学科学家,他在Warren McCulloch和Walter Pitts" +
"早期工作的基础之上,发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来" +
"描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式," +
"因而采用了“正则表达式”这个术语。之后一段时间,人们发现可以将这一工作成果应用于其他方面。" +
"1968年,Unix之父Ken Thompson就把这一成果应用于计算搜索算法的一些早期研究。Ken Thompson将此符号系统" +
"引入编辑器QED,然后是Unix上的编辑器ed,并最终引入grep。Jeffrey Friedl 在其著作《Mastering Regular " +
"Expressions (2nd edition)》(中文版译作:精通正则表达式,已出到第三版)中对此作了进一步阐述讲解,如果你希望" +
"更多了解正则表达式理论和历史,推荐你看看这本书。自此以后,正则表达式被广泛地应用到各种UNIX或类似于UNIX的工具中," +
"如大家熟知的Perl。Perl的正则表达式源自于Henry Spencer编写的regex,之后已演化成了pcre(Perl兼容正则表达式Perl " +
"Compatible Regular Expressions),pcre是一个由Philip Hazel开发的、为很多现代工具所使用的库。正则表达式的第一个实用" +
"应用程序即为Unix中的 qed 编辑器。";
//提取文章中所有的英文单词:
//(1)传统方法,使用遍历方式,代码量大,效率不高
//(2)正则表达式技术
//1、先创建一个Pattern对象,模式对象,可以理解成就是一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");
//提取文章中所有的数字
Pattern pattern1 = Pattern.compile("[0-9]+");
//提取文章中所有的英文单词和数字
Pattern pattern2 = Pattern.compile("([0-9]+)|([a-zA-Z]+)");
//提取文章的标题
Pattern pattern3=Pattern.compile("结论:正则表达式是处理文本的利器
2、为什么要学习正则表达式

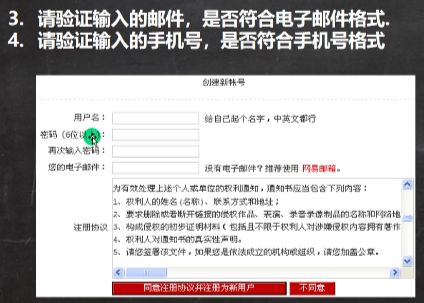
结论:正则表达式是对字符串执行模式匹配的技术
二、正则表达式基本语法
1、基本介绍:
一个正则表达式,就是用某种模式去匹配字符串的一个公式。很多人因为它们看上去比较古怪而且复杂所以不敢去使用,不过,经过练习后,就觉得这些复杂的表达式写起来还是相当简单的,而且,一旦你弄懂它们,你就能把数小时辛苦而且易错的文本处理工作缩短在几分钟(甚至几秒钟)内完成。
注意:正则表达式并非只有java才有。
2、正则表达式底层实现
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分析java的正则表达式的底层实现
*/
public class RegTheory {
public static void main(String[] args) {
String content="Java programming language具有大部1990分编程语言所共有的一些特征,被特意设计用于互联网的分布式环境。Java具有类似于C++语言的\"形式和感觉\",但它要比C++语言更易于使用,而且在编程时彻底采用了一种\"以对象为导向\"的方式。使用Java编写的应用程序,既可以在一台单独的电脑上运行,也可以被分布在一个网络的服务器端和客户端运行。另外,Java还可以被用来编写容量很小的应用程序模块或者applet,做为网页的一部分使用。applet可使网页使用者和网页之间进行交互式操作。\n" +
"Java是Sun微系统公司在1995年推出的,推出之后马上8889给互联网的交互式应用带来了新面貌。最常用的两种互联网浏览器软件中都包括一个Java虚拟机。几乎所有的操作系统中都增添了Java编译程序。";
//目标:匹配所有连着的四个数字
//说明:
//1、\\d表示一个任意的数字
String regStr="\\d\\d\\d\\d";
//2、创建模式对象[即正则表达式对象]
Pattern pattern=Pattern.compile(regStr);
//3、创建匹配器matcher(按照正则表达式的规则去匹配content字符串)
Matcher matcher = pattern.matcher(content);
//4、开始匹配
/**
* 分析matcher.find()的底层机制
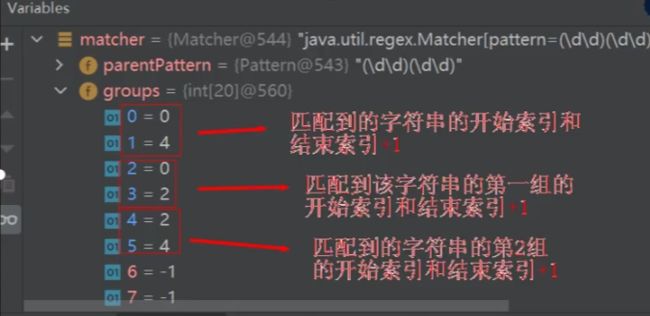
* 1、根据指定的规则,定位满足规则的子字符串(比如1995)
* 2、找到后,将子字符串的开始的索引 记录到matcher对象的属性int[] groups;
* groups[0]=0,把该子字符串的结束的索引+1的值 记录到groups[1]=4
* 3、同时记录oldLast的值为子字符串的结束的索引+1的值 即4,即下次执行find时,就从4开始匹配
* 4、什么是分组,比如(\d\d)(\d\d),正则表达式中有()表示分组,第1个()表示第1组,第2个()表示第2组
* groups[0]=0:记录子字符串的开始的索引
* groups[1]=4:记录子字符串的结束的索引+1的值
* groups[2]=0:记录第一组匹配到的字符串开始的索引
* groups[3]=2:记录第一组匹配到的字符串结束的索引+1 ——》19
* groups[4]=0:记录第二组匹配到的字符串开始的索引
* groups[5]=2:记录第二组匹配到的字符串结束的索引+1 ——》95
*
*
* 分析matcher.group(0)的底层源码:
* public String group(int group) {
* if (first < 0)
* throw new IllegalStateException("No match found");
* if (group < 0 || group > groupCount())
* throw new IndexOutOfBoundsException("No group " + group);
* if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
* return null;
* return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
* }
* 1、根据groups[0]=0和groups[1]=4的记录的位置,从content开始截取子字符串返回
* 就是[0,4)包含0,但是不包含索引为4的位置
*
*/
while(matcher.find()){
//小结:
//1、如果正则表达式有()分组
//2、取出匹配的字符串规则如下:
//(1)group(0)表示匹配到子字符串
//(2)group(1)表示匹配到子字符串的第一组字串
//(3)group(2)表示匹配到子字符串的第二组字串
//注意:分组的数不能越界
System.out.println("找到:"+matcher.group(0));
System.out.println("第1组()匹配到的值:"+matcher.group(1));
System.out.println("第2组()匹配到的值:"+matcher.group(2));
//输出:找到:1995
}
}
}
3、元字符(Metacharacter)- 转义号\\
“\\”:在我们使用正则表达式去检索某些特殊字符的时候,需要用到转义符号,否则检索不到结果,甚至会报错的。需要用到的转义符号的字符有:* + ( ) $ / \ ? [ ] ^ { }
注意:在Java的正则表达式中,两个 \ 代表其他语言中的一个 \
如果要想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致
分为:
(1)限定符
用于指定其前面的字符和组合项连续出现多少次


- +: 表示出现1次到任意多次
- *:表示出现0次到任意多次
- ?:表示出现0次到1次
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 演示限定符的使用
*/
public class RegExp05 {
public static void main(String[] args) {
String content="a1111111aaaa";
String regStr="a{3}";//表示匹配aaa
String regStr2="1{4}";//表示匹配1111
String regStr3="\\d{2}";//表示匹配两位的任意数字字符
//找到:11
//找到:11
//找到:11
String regStr4="a{3,4}";//表示匹配aaa或者aaaa
//找到:aaaa
String regStr5="1{4,5}";//表示匹配111或者1111
//找到:11111
String regStr6="\\d{2,5}";//表示匹配任意两位或三位或四位或五位数
//找到:11111
//找到:11
String regStr7="1+";//匹配一个1或者多个1
//找到:1111111
String regStr8="\\d+";//匹配一个数字或者多个数字
//找到:1111111
String regStr9="1*";//匹配0个1或者多个1
//找到:
//找到:1111111
//找到:
//找到:
//找到:
//找到:
//找到:
String regStr10="a1?";//匹配a或者a1
//找到:a1
//找到:a
//找到:a
//找到:a
//找到:a
Pattern pattern = Pattern.compile(regStr2);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println("找到:"+matcher.group(0));
}
}
}
java匹配默认贪婪匹配,即尽可能匹配多的
(2)选择匹配符
在匹配某个字符串时是选择性的,即:既可以匹配这个,又可以匹配那个

package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 应用实例
*/
public class RegExp04 {
public static void main(String[] args) {
String content="hanshunping 韩 寒冷";
String regStr="han|韩|寒";
Pattern pattern=Pattern.compile(regStr);
Matcher matcher=pattern.matcher(content);
while(matcher.find()){
System.out.println("找到:"+matcher.group(0));
}
//找到:han
//找到:韩
//找到:寒
}
}
(3)分组组合和反向引用符
(4)特殊字符
(5)字符匹配符
1)

2)应用实例:
- [a—z] 表示可以匹配a—z中任意一个字符
- [A—Z]表示可以匹配A—Z中任意一个字符。
- [0—9]表示可以匹配0—9中任意一个字符。
[^a—z]表示可以匹配不是a—z中的任意一个字符,
[^A—Z]表示可以匹配不是A—Z中的任意一个字符。
[^0—9]表示可以匹配不是0—9中的任意一个字符。
[abcd]表示可以匹配abcd中的任意一个字符
[abcd]表示可以匹配不是abcd中的任意一个字符(当然上面的abcd你可以根据实际情况修改,以适应你的需求
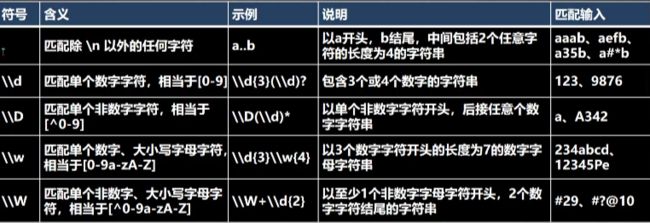
\\d 表示可以匹配0-9的任意一个数字,相当于[0-9]
\\D表示可以匹配非数字字符的所有字符,相当于[^0-9]
\\w匹配任意英文字符、数字和下划线,相当于[a-zA-Z0-9_]
\\W相当于[^a-zA-Z0-9_],与\w刚好相反
\\s匹配任何空白字符(空格,制表符等)
\\S匹配任何非空白字符,和\s刚好相反
匹配出\n之外的所有字符,如果要匹配 . 本身则需要使用\\.
*应用:
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 演示字符匹配符的使用
*/
public class RegExp03 {
public static void main(String[] args) {
String content="A11c8";
String regStr="[a-z]";//匹配a-z之间任意一个字符
//String regStr="abc";//匹配abc字符串[默认区分大小写]
//String regStr="(?i)abc";//匹配abc字符串[不区分大小写]
Pattern pattern = Pattern.compile(regStr);
//当创建Pattern对象时,指定Pattern.CASE_INSENSITIVE,表示匹配是不区分字母大小写
//Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:"+matcher.group(0));
}
}
}
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 正则表达式的应用实例
*/
public class RegExp10 {
public static void main(String[] args) {
String content="韩顺平教育";
//汉字
String regStr="^[\u0391-\uffe5]$";
//邮政编码:是1-9开头的一个六位数
String regStr2="^[1-9]\\d{5}$";
//QQ号码:是1-9开头的一个(5位数-10位数)
String regStr3="^[1-9]\\d{4,9)$";
//手机号码:必须以13、14、15、18开头的11位数
String regStr4="^[1-9]\\d{4,9}$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
System.out.println("满足格式");
}else{
System.out.println("不满足格式");
}
}
}
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp11 {
public static void main(String[] args) {
String content = "http://www.bilibili.com/video/BV1fh411y7R8?from=search&seid=1831060912083761326";
/**
* 思路:
* 1、先确定url的开始部分https://http://
* 2、然后通过([\w-]+\.)+[\w-]+ 匹配 www.bilibili.com
*
*/
String regStr = "^((http|https)://)([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.]*)?$";
//+表示后面可以有多个小括号等
//[.]表示匹配的就是.本身
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
}
}
*java正则表达式默认是区分字母大小写的,如何实现不区分大小写
- (?i)abc 表示abc都不区分大小写
- a(?i)bc表示bc不区分大小写
- a((?i)b)c表示只有b不区分大小写
- Pattern pat =Pattern.compile(regEx, Pattern.CASE_INSENSITIVE); //insensitive不敏感
(6)定位符
规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置,这个也是相当有用的,必须掌握

package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp06 {
public static void main(String[] args) {
String content="123abc hanshunping sphan nnhan";
String regStr="^[0-9]+[a-z]*";//以至少1个数字开头,后接任意个小写字母的字符串
//找到:123abc
String regStr2="^[0-9]+[a-z]+$";//以至少1个数字开头,必须以至少一个小写字母结束
//找到:123abc
String regStr3="han\\b";//表示匹配边界的han
//找到:han
//找到:han
String regStr4="han\\B";//恰好与\\b相反
//找到:han
Pattern pattern=Pattern.compile(regStr4);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:"+matcher.group(0));
}
}
}
三、三个常用类
java.util.regex包主要包括以下三个类Pattern类、、Matcher类和PatternSyntaxExeption
1、Pattern类
Pattern对象是一个正则表达式对象。Pattern类没有公共构造方法。要创建一个Pattern对象,调用其公共静态方法,它返回一个Pattern对象。该方法接受一个正则表达式作为它的第一个参数,比比如:Pattern r=Pattern.compile(pattern);
2、Matcher类
Matcher对象是对输入字符串进行解释和匹配的引擎。与Pattern类一样,Matcher也没有公共构造方法。你需要调用Pattern对象的matcher方法来获得一个Matcher对象

package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Matcher常用的方法
*/
public class MatcherMethod {
public static void main(String[] args) {
String content="hello edu jack hspedutom hello smith hello hspedu hspedu";
String regStr="hello";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("===================");
System.out.println(matcher.start());
System.out.println(matcher.end());
System.out.println("找到:"+content.substring(matcher.start(),matcher.end()));
}
//整体匹配方法:常用于,去校验某个字符串是否满足某个规则
System.out.println("整体匹配:"+matcher.matches());
//完成如果content 有 hspedu替换成 韩顺平教育
System.out.println("===================");
regStr="hspedu";
pattern=Pattern.compile(regStr);
matcher=pattern.matcher(content);
//注意:返回的字符串才是替换后的字符串,原来的content不变化,换标不换本
String newContent=matcher.replaceAll("韩顺平教育");
System.out.println("newContent:"+newContent);
System.out.println("content:"+content);
}
}
//===================
//0
//5
//找到:hello
//===================
//25
//30
//找到:hello
//===================
//37
//42
//找到:hello
//整体匹配:false
//newContent:hello edu jack 韩顺平教育tom hello smith hello 韩顺平教育 韩顺平教育
//content:hello edu jack hspedutom hello smith hello hspedu hspedu
3、PatternSyntaxException类
PatternSyntaxException是一个非强制异常类 它表示一个正则表达式模式中的语法错误
四、分组、捕获、反向引用
1、分组
我们可以用圆括号组成一个比较复杂的匹配模式,那么一个圆括号的部分我们可以看作是一个子表达式 / 一个分组。
2、捕获
把正则表达式中子表达式 / 分组匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。组0代表的是整个正则式
(1)捕获匹配:

package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 捕获匹配
*/
public class RegExp07 {
public static void main(String[] args) {
String content="hanshunping s7789 nn1189han";
String regStr="(\\d\\d)(\\d\\d)";//匹配4个数组的字符串
String regStr2="(?\\d\\d)(?\\d\\d)";//可以给分组取名
Pattern pattern = Pattern.compile(regStr2);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println("找到:"+matcher.group(0));
System.out.println("第1个分组内容:"+matcher.group(1));
System.out.println("第2个分组内容:"+matcher.group(2));
System.out.println("通过组名取组内的内容:"+matcher.group("g1"));
System.out.println("通过组名取组内的内容:"+matcher.group("g2"));
}
}
}
//找到:7789
//第1个分组内容:77
//第2个分组内容:89
//通过组名取组内的内容:77
//通过组名取组内的内容:89
//找到:1189
//第1个分组内容:11
//第2个分组内容:89
//通过组名取组内的内容:11
//通过组名取组内的内容:89
(2)非捕获匹配:

package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 非捕获匹配
*/
public class RegExp08 {
public static void main(String[] args) {
String content="hello韩顺平教育 jack韩顺平老师 韩顺平同学hello";
String regStr="韩顺平教育|韩顺平老师|韩顺平同学";
//上面的写法可以等价于非捕获分组,注意不能再写matcher.group(1)
String regStr1="韩顺平(?:教育|老师|同学)";
//找到:韩顺平教育
//找到:韩顺平老师
//找到:韩顺平同学
//只查找韩顺平教育和韩顺平老师中包含的韩顺平,注意不能再写matcher.group(1)
String regStr2="韩顺平(?=教育|老师)";
//找到:韩顺平
//找到:韩顺平
//只查找韩顺平教育和韩顺平老师之外的韩顺平,注意不能再写matcher.group(1)
String regStr3="韩顺平(?!教育|老师)";
//找到:韩顺平
Pattern pattern = Pattern.compile(regStr3);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println("找到:"+matcher.group(0));
}
}
}
3、反向引用
圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用 \\ 分组号,外部反向引用 $ 分组号
4、案例:
(1)


package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp12 {
public static void main(String[] args) {
String content="hello jack1551 tom11 jack22 yyy12321-333999111 xxx";
//要匹配两个连续的相对数字:(\\d)\\1
//String regStr="(\\d)\\1";
//要匹配五个连续的相同数字:(\\d)\\1{4}
//String regStr="(\\d)1{4}";
//要匹配个位与千位相同,千位与百位相同的数5225,1551
//String regStr="(\\d)(\\d)\\2\\1";
//找到:1551
//请在字符串中检索商品编号,形式如:12321-333999111这的号码,
// 要求满足前面是一个五位数,
// 然后一个-号,然后是一个九位数,连续的每三位要相同
String regStr="\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
//找到:12321-333999111
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:"+matcher.group(0));
}
}
}
(2)
package com.hspedu.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp13 {
public static void main(String[] args) {
String content="我......我要......学学学......编程java";
//1、去掉所有的.
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
content=matcher.replaceAll("");
System.out.println("content:"+content);
//2、去掉重复的字
System.out.println("================\n普通方法:");
pattern=Pattern.compile("(.)\\1+");
//因为正则表达式变化,所以需要重置matcher
matcher=pattern.matcher(content);
while(matcher.find()){
System.out.println("找到:"+matcher.group(0));
}
//使用反向引用$1 来替换匹配到的内容
content=matcher.replaceAll("$1");
System.out.println("content:"+content);
System.out.println("================\n简化后:");
content=Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");
System.out.println("content:"+content);
}
}
//content:我我要学学学编程java
//================
//普通方法:
//找到:我我
//找到:学学学
//content:我要学编程java
//================
//简化后:
//content:我要学编程java
五、应用实例
1、String 类中使用正则表达式
(1)替换功能:
String 类 public String replaceAll(String regex,String replacement)
package com.hspedu.regexp;
public class StringReg {
public static void main(String[] args) {
String content="1997 年Servlet技术的产生以及紧接着JSP的产生,为Java对抗PHP,ASP等等" +
"服务器端语言带来了筹码。1998年,Sun发布了JDK1.3标准," +
"至此JDK1.4平台的三个核心技术都已经出现。于是,1999年,Sun正式发布了JDK1.3的第一个版本。" +
"并于1999年底发布了JDK1.3,在 2001年发布了JDK1.3," +
"2003年发布了JDK1.4。";
//使用正则表达式,将JDK1.3 和JDK1.4 替换成JDK
content=content.replaceAll("JDK1\\.3|JDK1\\.4","JDK");
System.out.println(content);
}
}
(2)判断功能
String 类 public boolean matches(String regex){ }
package com.hspedu.regexp;
public class StringReg {
public static void main(String[] args) {
//要求验证一个手机号,要求必须是以138 139开头的
String content="13888999999";
if(content.matches("1(38|39)\\d{8}")){
System.out.println("验证成功");
}else{
System.out.println("验证失败");
}
}
}
(3)分割功能
String 类 public String[ ] split(String regex)
package com.hspedu.regexp;
public class StringReg {
public static void main(String[] args) {
//要求按照 # 或者 - 或者 ~ 或者 数字 来分割
String content="hello#abc-jack12smith~北京";
String[] split=content.split("#|-|~\\d+");
for(String s:split){
System.out.println(s);
}
}
}
//hello
//abc
//jack12smith~北京