python设计实验报告
这篇文章主要介绍了一个有趣的事情,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

| 实验1 |
安装Python开发环境熟悉基本绘图库turtle库使用 |
| 实验目的 |
理解Python语言的特点及其重要性,掌握Python语言开发环境及配置方法,掌握Python 3、第三方IDE(PyCharm)、VCCode安装方法、安装第三方库包的方法。了解Python版本更迭过程和新旧版本的主要区别高一信息技术python编程题。掌握Python语言的语法元素,程序的格式和框架,熟记保留字,掌握turtle两种绘图体系,熟练使用turtle库函数绘制简单图形。 |
| 实验题目 |
安装并熟悉Python语言开发环境及绘制基本图形 |
一、实验内容
下载并安装Python3.x版本,在IDLE中运行下面给定程序,熟练掌握Python语言开发和运行环境。
- 字符串拼接,接收用户输入的两个字符串,将他们组合后输出。
- 整数序列求和。用户输入一个正整数N,计算从1到N(包括1和N)相加之后的结果。
- 九九乘法表。工整打印输出常用的九九乘法表,格式不限。
- 汇率转换程序,按照温度转换程序的设计思路,按照1美元=6人民币的汇率编写一个美元和人民币互换的程序。
- 利用turtle库绘制基本图形。如五角星、太阳花、等边三角形、正方形螺旋线、六角形等图形。如下图所示




二、问题分析、算法设计
1、字符串拼接,接收用户输入的两个字符串,将他们组合后输出。
将分别输入的字符串赋值给str1和str2,利用print将str1与str2打印出来
- 整数序列求和。用户输入一个正整数N,计算从1到N(包括1和N)相加之后的结果。
将输入的一个数字赋值给n,利用for循环累加给sum,最终输出。
- 九九乘法表。工整打印输出常用的九九乘法表,格式不限。
利用双循环,外循环9次,内循环9次,进行打印输出。
- 汇率转换程序,按照温度转换程序的设计思路,按照1美元=6人民币的汇率编写一个美元和人民币互换的程序。
首先将输入的字符串赋值给t,检测最后一个符号是c、C或者f、F,如果是前者则利用 f=1.8*float(t[0:-1])+32打印输出,后者c=(float(t[0:-1])-32)/1.8打印输出。
5、利用turtle库绘制基本图形。如五角星、太阳花、等边三角形、正方形螺旋线、六角形等图形。
三、实验代码
1. 字符串拼接,接收用户输入的两个字符串,将他们组合后输出。
str1=input("请输入第一个字符串")
str2=input("请输入第二个字符串")
str3=str1+str2
print("经过组合后为:"+str3)
2. 整数序列求和。用户输入一个正整数N,计算从1到N(包括1和N)相加之后的结果。
N=input("请输入一个正整数")
n=int(N)
result=int(n+(n*(n-1))/2)
print("计算的结果为:{}".format(result))
3. 九九乘法表。工整打印输出常用的九九乘法表,格式不限
i=1
j=1
for i in range(1,10):
for j in range(1,i+1):
print('%s*%s=%s' %(j,i,i*j),end = ' ')
print()
5.五角星和太阳花的绘制。
1)绘制一个红色五角星
from turtle import *
fillcolor("red")
begin_fill()
while True:
forward(200)
right(144)
if abs(pos())<1:
break
end_fill()
2)绘制一个黄色太阳花.
from turtle import *
color('red','yellow')
begin_fill()
while True:
forward(200)
left(170)
if abs(pos())<1:
break
end_fill()
done()
四、实验的预期或测试用例
1、 输入123
abc
输出:123abc
2、 输入 10
输出:55
3、 输入:无
输出:乘法表
4、 1)输入:100¥
输出:16.67$
2)输入:15$
输出:90¥
5、 输入:无
输出:五角星、太阳花、等边三角形、正方形螺旋线、六角形
五、实验中出现的问题及解决的方法
在1.3中出现换行控制的问题,最后通过一个在外层循环一个空白print()解决问题
六、实验最终代码及结果分析


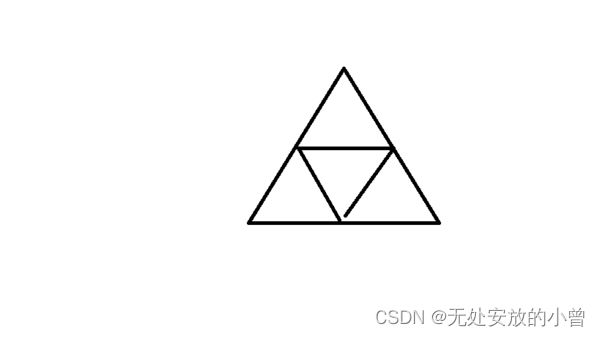


实验总结
通过本次实验可以初步熟悉Python的语法结构,python的缩进体系,变量命名等基础内容以及turtle绘图体系的使用。
| 实验2 |
Python语言基本数据类型综合应用 |
| 实验目的 |
掌握Python语言的基本数据类型在计算机中的表示,运用Python的标准数学库math进行数值计算,掌握字符串类型的使用方法 |
| 实验题目 |
Python语言基本数据类型综合应用 |
一、实验内容
参考教学中的天天向上的力量实例完成下面程序设计:
1.天天向上的能力增长模型如下:以7天为周期,连续学习3天能力值不变,从第4天开始至第7天每天能力增长为前一天的1%,如果7天中个1天间断学习,则周期从头开始计算。编写程序回答,如果初始能力值为1,连续学习365天后能力值是多少?
2.回文数判断。设n是一任意自然数,如果n的各位数字反向排列所得自然数与n相等,则n被称为回文数,从键盘输入一个5位数字,请编写程序判断这个数是不是回文数。
3.文本进度条,仿照实例4,打印如下形式的进度条。
Staring ... Done!
二、问题分析、算法设计
1、天天向上需要使用循环控制365天每天的能力值,前三天和后四天需要分开处理,使用if else区分,流程图如图2.1。
2、将输入的字符串进行倒置处理s[::-1],然后进行比较两个字符串是否相等,相等则为回文数,流程图如图2.2
3、需要使用计时器控制每行的打印,流程图如图2.3。

三、实验代码
#1
ability=1
for i in range(365):
if i % 7 <=2:
ability=ability*1
else :
ability=ability*(1+0.01)
print ('能力为:\n%.2f'%ability)
#2
s=input("请输入一个字符串:\n")
l=s[::-1]
while s==l:
print("是回文数")
break;
else:print("不是回文数")
#3
import time
scale = 50
print("Staring ... ".center(scale//2,"-"))
start = time.perf_counter()
for i in range(scale+1):
a = '*' * i
b = '.' * (scale-i)
c = (i/scale)*100
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s\n".format(c,a,b,dur),end=' ')
time.sleep(0.1)
print("\n"+"Done!".center(scale//2,'-'))
四、实验的预期或测试用例
1、输出:能力为:7.92
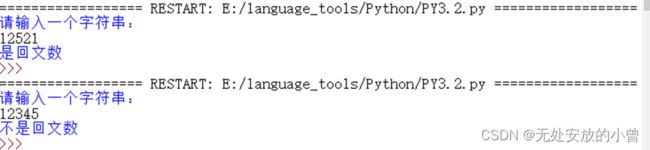
2、输入:12521
输出:是回文数
输入:12345
输出:不是回文数
3、 Staring done形式进度显示
五、实验中出现的问题及解决的方法
如何应用string的相关知识省力判断回文,在经过一系列波折之后发现s[::-1]可以直接获取倒置后的字符串
六、实验最终代码及结果分析
程序运行结果如下图,均已实现题目所提要求:


七、实验总结
本次实验可以熟悉字符串的相关操作,其中包含python特有的省力获得倒置字符串的s[::-1],循环结构的使用,以及time库的使用。
| 实验3 |
Python语言分支循环结构应用 |
| 实验目的 |
掌握Python语言的基本结构并绘制流程图,掌握分支结构,利用if语句实现单分子,双分支和多分支,掌握循环结构,运用for语句和while语句实现循环结构和循环嵌套,掌握随机库的使用方法,掌握程序的异常处理。 |
| 实验题目 |
Python语言分支循环结构应用 |
一、实验内容
参考教学内容完成如下程序设计:
1.猜数字游戏,程序随机产生一个0--100的整数,让用户通过键盘输入所猜的数,如果大于预设的数,显示,“遗憾,太大了!”,小于预设的数,显示“遗憾,太小了!”,如此循环,指导猜中该数,显示“预测N次,你猜中了!”,其中N是用户输入数字的次数。如果用户输入不是整数时,提示“输入内容必须是整数!”的提示,并让用户重新输入。
2.统计不同字符个数。用户从键盘输入一行字符,编写一个程序 ,统计并输出其中英文字符,数字字符,空格字符和其他字符的个数。
3.羊车门问题。有三扇关闭的门,一扇门后面停着汽车,其余门后是山羊,只有主持人知道每扇门后面是什么,参赛者可以选择一扇门,在开启它之前,主持人会开启另外一扇门,露出门后面的山羊,然后允许参赛者更改选择。请问:参赛者更改选择后能否增加猜中汽车的概率?请使用random库对这个随机事件进行预测,分别输出参赛者改变选择和坚持选择的获胜概率。
二、问题分析、算法设计
1、利用randint()函数快速获取一个随机数 然后与用户输入的数据进行匹配,根据与随机数的大小比较结果进行提示,每次猜测都会导致猜测次数+1,最后输出猜测次数,流程图如图3.1。
2、从头依次扫描输入的每个字符,利用isalpha等函数判断是否为所需类型的数据,再进行统计,最后输出统计结果,流程图如图3.2。
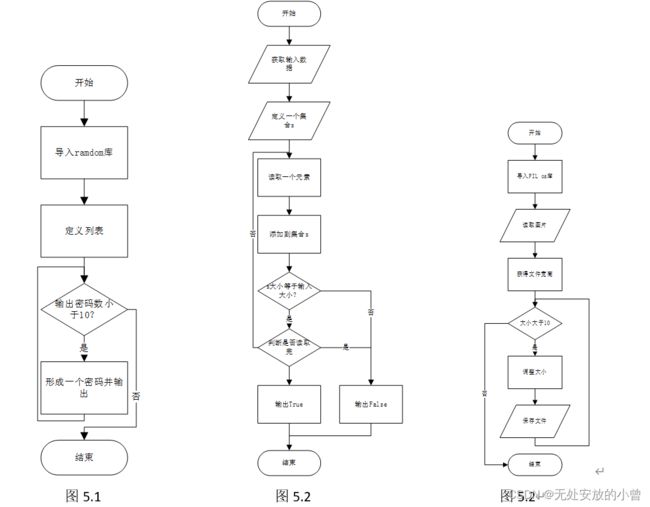
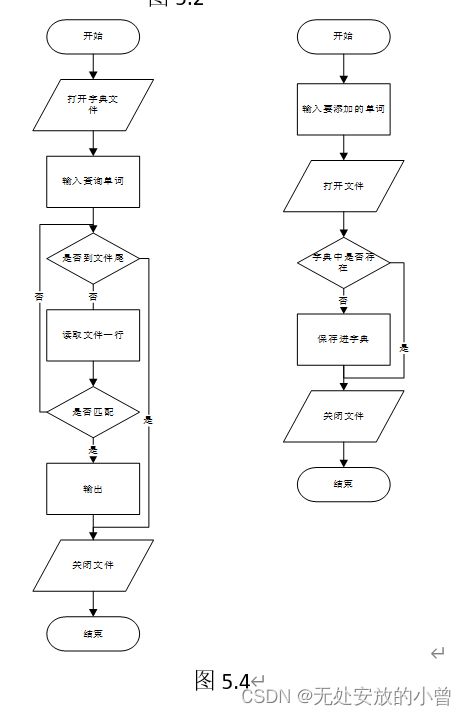
3、使用random库产生随机数,以此代表人猜测的结果,模拟200次猜测,分别统计换选择和不换选择的猜中概率,最后得证换选择猜中概率更高,流程图如图3.3。

三、实验代码
#1
from random import *
x=randint(0,100)
num=0
while True:
y=eval(input("请输入一个0到100的数:"))
if x print("遗憾,太大了") num=num+1 elif x>y: print("遗憾,太小了") num=num+1 else: print("预测"+str(num+1)+"次,你猜中了!") break #2 s=input("请输入一行字符:\n") alpha,num,space,other=0,0,0,0 for i in s: if i. isalpha (): alpha+=1 elif i.isdigit(): num+=1 elif i.isspace(): space+=1 else: other+=1 print('英文字符数{},数字字符数{},空格字符数{},其他字符数{}'.format(alpha,num,space,other)) #3 import random data={1:'car',2:'goat1',3:'goat2'} i=0 probability1=0 while i<200: num1=random.randint(1,3) chosen1=data[num1] if chosen1!='car': probability1=probability1+1 i=i+1 print('更换选择猜中概率-> ',probability1/2,'%') j=0 probability2=0 while j<200: num2=random.randint(1,3) chosen2=data[num2] if chosen2=='car': probability2=probability2+1 j=j+1 print('不更换选择猜中概率-> ',probability2/2,'%') 四、实验的预期或测试用例 1、根据提示能够猜中此随机数 2、输入 qwer1234,,, @ 输出4 4 3 4 3、输出:66.5% 32.5% 五、实验中出现的问题及解决的方法 在对4.1进行验证时,可以采用二分法缩减猜测的次数,提高验证效率 六、实验最终代码及结果分析 程序运行结果如下图,均已实现题目所提要求: 七、实验总结 本次实验掌握分支结构,循环结构,运用for语句和while语句实现循环结构和循环嵌套,掌握随机库的使用方法,掌握程序的异常处理。 实验4 Python语言函数及递归综合应用 实验目的 掌握函数的定义和调用方法,理解函数的参数传递过程以及变量的作用范围,了解lambda函数,掌握时间日期标准库的使用,理解函数递归的定义及使用。 实验题目 Python语言函数及递归综合运用 一、实验内容 1.实现isPrime()函数,参数为整数,要有异常处理,如果参数为素数,则输出True,否则输出False。 2.使用datatime库,对自己的生日输出不少于10种的日期格式。 3.编写递归函数实现汉诺塔问题。 二、问题分析、算法设计 1、编写一个函数判断输入数据是否为整数,进而再判断是否是素数。若一个数能够被自身和1之外的数整除,则其不是素数,流程图如图4.1。 2、strftime()函数进行格式控制,流程图如图4.2。 3、先将其他圆盘移动到辅助柱子上,并将最底下的圆盘移到c柱子上,然后再把原先的柱子作为辅助柱子,并重复此过程,流程图如图4.3。 三、实验代码 #1 def check(str): if(str.isdigit()): return True else: return False def isPrime(): str = input("请输入整数:") checkStr=bool(check(str)) if checkStr==True: numStr=int(str) count=0 for i in range(1,numStr+1): if numStr%i!=0: continue else: count+=1#判断素数的关键,超过2证明不是素数 if count==2 : print("素数") return True else: print("非素数") return False else: print("你输入的不是整数,请再次输入") isPrime() isPrime() #2 import datetime import time birthday=datetime.datetime(1998,10,12,18,11,57,9) print(birthday) print(birthday.strftime('%Y-%m-%d')) print(birthday.strftime('%Y-%d-%m')) print(birthday.strftime('%m-%d-%Y')) print(birthday.strftime('%m-%y-%d')) print(birthday.strftime('%d-%m-%Y')) print(birthday.strftime('%d-%y-%m')) print(birthday.strftime('%Y\%d\%m')) print(birthday.strftime('%m\%d\%Y')) print(birthday.strftime('%m\%y\%d')) print(birthday.strftime('%d\%m\%Y')) #3 def move(n,a,b,c): if n==1: print (a+'-->'+c) else: move(n-1,a,c,b) print(a+'-->'+c) move(n-1,b,a,c) move(3,'A','B','C') 四、实验的预期或测试用例 1、输入 1.2 输出:不是整数 输入:12 输出:非素数 2、输出多种格式的日期 3 、输出移动汉诺塔的过程 五、实验中出现的问题及解决的方法 汉诺塔在递归时需要注意递归终止条件 六、实验最终代码及结果分析 程序运行结果如下图,均已实现题目所提要求: 七、实验总结 本次实验掌握函数的定义和调用方法,理解函数的参数传递过程以及变量的作用范围,了解lambda函数,掌握时间日期标准库的使用,理解函数递归的定义及使用。 实验5 Python语言文件及多维数据编程 实验目的 了解3类基本组合数据类型,理解列表概念及使用方法,理解字典概念及使用方法,掌握列表管理采集信息构建数据结构的方法,掌握运用字典处理复杂数据信息的方法,熟练运用组合数据类型进行文本词频统计。 实验题目 python语言 组合数据类型综合运用 一、实验内容 参考教学内容完成如下程序设计: 3.图像文件压缩。使用PIL库对图片进行等比例压缩,无论压缩前图片文件如何,压缩后文件小于10kb。 4.编写程序制作英文学习词典,词典有三个功能,添加、查询、退出。程序读取源文件路径下的txt格式的词典文件,若没有就创建一个,词典文件存储方式为“英文单词 中文单词 ”,每行仅一对中英解义。程序会根据用户的选择进入相应的功能模块,并显示相应的提示信息。当添加的单词已经存在时提示“该单词已添加到字典库”;当查询的单词不存在时,提示“字典库中未找到该单词”;用户输入其他选项时提示“输入错误”。 二、问题分析、算法设计(流程图) 1、 random.sample(seq, k)实现从序列或集合seq中随机选取k个独立的的元素,以列表形式输出,在给定的列表中使用random.sample(seq, k)输出10个密码,流程图如图5.1。 2、采用列表存储,若所指向的元素不存在于列表之中,则添加,列表中不会存在相同的元素,判断列表和输入数据的长度是否相等即可判断是否有重复值,流程图如图5.2。 3、 使用PIL进行图片操作,读取图片后,每次都进行一小部分压缩输出保存,判断压缩过后的大小是否小于10k,若不小于则继续进行操作,最后输出压缩之后的大小。流程图如图5.3。 4、字典文件中每一行作为一个单词,首先进行查询操作,读取文件,若在文件中能够找到输入的单词,则进行输出。之后进行添加操作,若输入的单词不在字典中,则进行写入操作。流程图如图5.4。 三、实验代码 #1 import random key = ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z","A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z","0","1","2","3","4","5","6","7","8","9"] for i in range(10): k = random.sample(key,8) for i in k: print(i,end="") print("\n") #2 def fn(list): s = set() lenth = len(list) for i in range(lenth): s.add(list[i]) if len(s) != (i + 1): return True else: return False #3 from PIL import Image import os picture=input("请输入图片的名称以及格式:") image=Image.open(picture) size=os.path.getsize(picture)/1024 width,height=image.size ima=input("请输入修改后的图片名称和格式:") while True: if size>10: width,height=round(width*0.9),round(height*0.9) image=image.resize((width,height),Image.ANTIALIAS) image.save(ima) size=os.path.getsize(ima)/1024 else: break print(size) #4 def search(): w=input("请输入要查询的单词:") fr=open("E:\\language_tools\\Python\\词典.txt",'r') dic={} for line in fr.readlines(): line=line.replace("\n","") line = list(line.split(",")) print(line) key=line[0] coment=line[1:] dic[key]=coment if w in dic.keys(): print(dic[w]) fr.close() search() def add(): ww=input("请输入你要添加的单词:") flag=0 dic = {} f=open("E:\\language_tools\\Python\\词典.txt",'r') for line in f.readlines(): line = line.replace("\n", "") line = list(line.split(",")) key=line[0] coment = line[1:] dic[key]=coment if ww in dic.keys(): f.close() flag=1 print("输入的单词已经存在!") break else: f.close() if flag!=1: fw = open("E:\\language_tools\\Python\\词典.txt", 'a') mean=input("若有多个意思,用英文逗号隔开:") fw.write(ww+','+mean+'\n') fw.close() add() 四、实验的预期或测试用例 1、生成10个8位密码 每个密码占一行 2、输入:print(fn([1,2,3,4,2])) 输出True 3、将制定的文件进行压缩,并且输出压缩后的大小 4、输入:a 输出:[‘a’,’一个’,’一位’] 五、实验中出现的问题及解决的方法 在1中 需要用print(i,end="")控制密码的不同位保持在同一行,不换行;在3、4中在打开文件时,遇到文件的路径书写问题后已经注意 六、实验最终代码及结果分析 七、实验总结 本次实验理解列表概念及使用方法,理解字典概念及使用方法,掌握列表管理采集信息构建数据结构的方法,掌握运用字典处理复杂数据信息的方法。还掌握了文件的读写方法以及打开关闭等基本操作,理解了数据组织的维度及其特点。