【中间件学习篇_Kafka】搞定kafka术语 No.4
目录
一、kafka架构图
二、Kafka相关概念及术语
三、参考资料
在 Kafka 的世界中有很多概念和术语需要熟练掌握,有助于深入理解Kafka原理。
kafka的相关术语有:生产者(Producer),消费者(Consumer),消费者组(Consumer Group),代理(Broker),集群(Cluster),消息(message),主题(Topic),分区(Partition),副本(Replica),消息位移(Offset),消费者位移(Consumer Offset),重平衡(Rebalance)。
一、kafka架构图
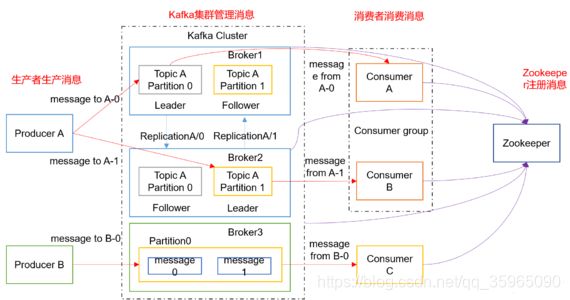
简单介绍下上图内容及工作流程,对相关术语在kafka中的用途有整体认识:
如上图:两个生产者(Producer)A和B;三个消费者A,B,C,并且A和B存在于同一个消费者组;kafka集群中三个broker,两个topic,分别是TopicA,TopicB;TopicA有两个分区(Partition),每个分区有两个副本,分别存在于Broker1和Broker2上,TopicB有一个分区,一个副本,存在于Broker3上,整个集群信息在Zookeeper上注册。
1、生产者向主题生产消息,发布到kafka集群,写入到Leader Replica,Follower Replica 向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步,进行消息冗余。
2、消费者(组)从kafka集群订阅消息,读取Leader Replica中的消息进行消费。
二、Kafka相关概念及术语
1、生产者(Producer):向主题发布新消息的客户端应用程序。
2、消费者(Consumer):从主题订阅新消息的客户端应用程序。与生产者类似,消费者也能够同时订阅多个主题的消息。
3、消费者组(Consumer Group):多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
我们把生产者和消费者统称为客户端(Clients)。你可以同时运行多个生产者和消费者实例,这些实例会不断地向 Kafka 集群中的多个主题生产和消费消息。
4、代理(Broker):Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一。
5、消息(message):Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
6、主题(Topic):主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
7、分区(Partition):一个有序不变的消息序列。每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。如你所见,Kafka 的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到 99。
8、副本(Replica):Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica),前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。副本的工作机制也很简单:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
9、消息位移(Offset):表示分区中每条消息的位置信息,是一个单调递增且不变的值。
10、消费者位移(Consumer Offset):表征消费者消费进度,每个消费者都有自己的消费者位移。
11、重平衡(Rebalance):消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
三、参考资料
kafka中文文档:https://kafka.apachecn.org/documentation.html#gettingStarted
极客时间-Kafka核心技术与实战:https://time.geekbang.org/column/article/99318