【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、maven依赖
- 二、自定义Source介绍及示例
-
- 1、示例-自定义数据源
-
- 1)、java bean
- 2)、自定义数据源实现
- 3)、使用自定义的数据源
- 4)、自定义数据源验证
- 三、自定义数据源-MySQL
-
- 1、maven依赖
- 2、java bean
- 3、mysql自定义数据源实现
- 4、使用mysql自定义的数据源
- 5、验证
-
- 1)、准备mysql环境-建库表
- 2)、启动TestCustomMySQLSourceDemo.java
- 3)、往user表中添加数据,并观察应用程序控制台输出
本文主要介绍Flink 的自定义数据源的2种情况,即自己产生的数据或数据源以及mysql作为自定义的数据源的示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为以下几篇文章:
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(1) - File、Socket、Collection
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(3)- kafka
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(4)- redis -异步读取
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(5)- clickhouse
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版
一、maven依赖
本文依赖见【flink番外篇】3、flink的source介绍及示例(1)- File、Socket、Collection,不再赘述。
如果有新增的maven依赖,则会在示例时加以说明,避免篇幅的过大。
二、自定义Source介绍及示例
Flink提供了数据源接口,实现该接口就可以实现自定义数据源,不同的接口有不同的功能,分类如下:
- SourceFunction,非并行数据源,并行度只能=1
- RichSourceFunction,多功能非并行数据源,并行度只能=1
- ParallelSourceFunction,并行数据源,并行度能够>=1
- RichParallelSourceFunction,多功能并行数据源,并行度能够>=1
1、示例-自定义数据源
本示例展示如何实现自定义数据源,并通过随机数产生数据信息,比较简单。
1)、java bean
如果使用其自定义的数据结构也可以,视情况需要。
package org.datastreamapi.source.custom.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private long clicks;
private long ranks;
private Long createTime;
}
2)、自定义数据源实现
继承RichParallelSourceFunction,并源源不断的产生数据,直到自己手动停止其运行或将启停标志flag设置成false。
package org.datastreamapi.source.custom;
import java.util.Random;
import java.util.UUID;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.datastreamapi.source.custom.bean.User;
/**
* @author alanchan
*
*/
public class CustomUserSource extends RichParallelSourceFunction<User> {
private boolean flag = true;
// 生产数据
@Override
public void run(SourceContext<User> ctx) throws Exception {
Random random = new Random();
while (flag) {
ctx.collect(new User(random.nextInt(100000001), "alanchan" + UUID.randomUUID().toString(), random.nextInt(9000001), random.nextInt(10001), System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
}
3)、使用自定义的数据源
本部分是使用上面定义的数据源。和使用其他数据源就一句代码的不同,即如下
DataStream<User> userDS = env.addSource(new CustomUserSource());
完整的示例如下
package org.datastreamapi.source.custom;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.source.custom.bean.User;
/**
* @author alanchan
*
*/
public class TestCustomSourceDemo {
/**
* @param args
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source,设置并行度是看每次产生多少条数据
DataStream<User> userDS = env.addSource(new CustomUserSource()).setParallelism(2);
// transformation
// sink
userDS.print();
// execute
env.execute();
}
}
4)、自定义数据源验证
运行TestCustomSourceDemo.java查看运行结果,本示例运行结果如下(每次运行结果均不同,供参考)
7> User(id=14317087, name=alanchan4ea184fd-472d-429c-b1b5-8fc16ba8c373, clicks=1815669, ranks=9648, createTime=1701824325507)
9> User(id=35956856, name=alanchanb715dab7-d3cb-40f3-b9e8-e0ba76d8b998, clicks=8888642, ranks=8143, createTime=1701824325507)
10> User(id=46536055, name=alanchan2aa31683-1af3-4d0b-81b6-c89265ba63f4, clicks=3766665, ranks=3282, createTime=1701824326536)
8> User(id=55937607, name=alanchan2ef54410-eaa4-47ed-8531-478957143051, clicks=5684939, ranks=8006, createTime=1701824326536)
9> User(id=92498863, name=alanchan1a324cdf-7ee6-4c6b-8059-7db01648428d, clicks=7199973, ranks=8005, createTime=1701824327552)
11> User(id=67794502, name=alanchanc73d8f15-abeb-4b86-9809-98094439e25c, clicks=654744, ranks=6799, createTime=1701824327552)
以上就完整的介绍了一个自定义数据源的过程,其中使用场景视情况而定。
三、自定义数据源-MySQL
上述示例中展示了自定义数据源的一种方式,就是自己产生数据或者其他的数据源获取,本示例展示的是以mysql数据源作为flink的数据源的实现。flink本身没有实现mysql数据源,需要自己实现。
1、maven依赖
本示例需要新增mysql的依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
2、java bean
package org.datastreamapi.source.custom.mysql.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
3、mysql自定义数据源实现
package org.datastreamapi.source.custom.mysql;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.datastreamapi.source.custom.mysql.bean.User;
/**
* @author alanchan
*
*/
public class CustomMySQLSource extends RichParallelSourceFunction<User> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
String sql = "select id,name,pwd,email,age,balance from user";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<User> ctx) throws Exception {
while (flag) {
rs = ps.executeQuery();
while (rs.next()) {
User user = new User(rs.getInt("id"), rs.getString("name"), rs.getString("pwd"), rs.getString("email"), rs.getInt("age"), rs.getDouble("balance"));
ctx.collect(user);
}
//每5秒查询一次数据库
Thread.sleep(5000);
}
}
@Override
public void cancel() {
flag = false;
}
}
4、使用mysql自定义的数据源
本部分是使用上面定义的数据源。和使用其他数据源就一句代码的不同,即如下
DataStream<User> userDS = env.addSource(new CustomMySQLSource()).setParallelism(1);
完整示例如下:
package org.datastreamapi.source.custom.mysql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.source.custom.mysql.bean.User;
/**
* @author alanchan
*
*/
public class TestCustomMySQLSourceDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<User> userDS = env.addSource(new CustomMySQLSource()).setParallelism(1);
// transformation
// sink
userDS.print();
// execute
env.execute();
}
}
5、验证
1)、准备mysql环境-建库表
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` smallint(6) NULL DEFAULT NULL,
`balance` double(255, 0) NULL DEFAULT NULL,
`email` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pwd` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2)、启动TestCustomMySQLSourceDemo.java
启动TestCustomMySQLSourceDemo.java程序,并观察控制台输出。
3)、往user表中添加数据,并观察应用程序控制台输出
- user 表数据
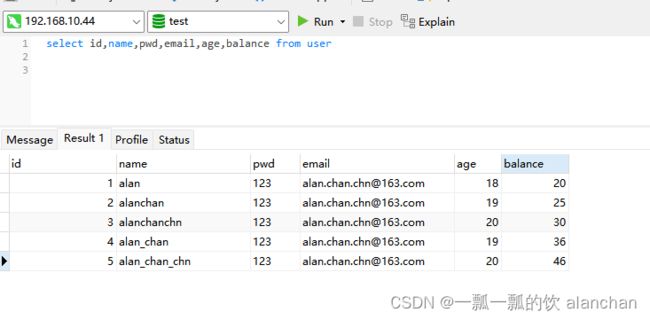
- 程序控制台输出(每5秒输出一次)
2> User(id=1, name=alan, pwd=123, email=[email protected], age=18, balance=20.0)
4> User(id=3, name=alanchanchn, pwd=123, email=[email protected], age=20, balance=30.0)
6> User(id=5, name=alan_chan_chn, pwd=123, email=[email protected], age=20, balance=46.0)
3> User(id=2, name=alanchan, pwd=123, email=[email protected], age=19, balance=25.0)
5> User(id=4, name=alan_chan, pwd=123, email=[email protected], age=19, balance=36.0)
以上,本文主要介绍Flink 的自定义数据源的2种情况,即自己产生的数据或数据源以及mysql作为自定义的数据源的示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章:
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(1) - File、Socket、Collection
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(3)- kafka
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(4)- redis -异步读取
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(5)- clickhouse
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版