【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、maven依赖
- 二、File、Socket、Collection介绍及示例
-
- 1、基于文件
- 2、基于套接字
- 3、基于集合
- 三、自定义、mysql介绍及示例
-
- 1、自定义Source介绍及示例
-
- 1)、示例-自定义数据源
-
- 1、java bean
- 2、自定义数据源实现
- 3、使用自定义的数据源
- 4、自定义数据源验证
- 2、自定义数据源-MySQL
-
- 1)、maven依赖
- 2)、java bean
- 3)、mysql自定义数据源实现
- 4)、使用mysql自定义的数据源
- 5)、验证
-
- 1、准备mysql环境-建库表
- 2、启动TestCustomMySQLSourceDemo.java
- 3、往user表中添加数据,并观察应用程序控制台输出
- 四、redis -异步读取介绍及示例
-
- 1、redis环境及相关内容说明
- 2、redis作为Flink的source异步数据交互示例
-
- 1)、maven依赖
- 2)、redis异步交互数据实现
-
- 1、读取redis数据时以string进行输出
- 2、读取redis数据时以pojo进行输出
- 3)、使用示例
- 4)、验证
-
- 1、准备redis环境数据
- 2、启动应用程序,并观察控制台输出
- 五、clickhouse介绍及示例
-
- 1、关于clickhouse的介绍
- 2、clickhouse作为Flink的source示例
-
- 1)、maven依赖
- 2)、实现
-
- 1、user bean
- 2、source实现
- 3)、验证
-
- 1、clickhouse数据源准备
- 2、启动应用程序并观察控制台输出
- 六、kafka介绍及示例
-
- 1、环境或版本说明
- 2、自定义数据源kafka(Flink 1.13.6 版本)
-
- 1)、maven依赖
- 2)、实现
- 3)、验证
- 3、自定义数据源kafka(Flink 1.17.0 版本)
-
- 1)、maven依赖
- 2)、实现
- 3)、验证
本文主要介绍Flink 的source内置(基于文件、集合和socket)、自定义、mysql、kafka、redis和clickhouse的实现,每种source的实现均给出具体的实现例子以及验证结果。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,分别依赖相应的环境,比如mysql数据库、kafka、redis和clickhouse。
本专题分为以下几篇文章:
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(1) - File、Socket、Collection
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(3)- kafka
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(4)- redis -异步读取
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(5)- clickhouse
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版
一、maven依赖
<properties>
<encoding>UTF-8encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<java.version>1.8java.version>
<scala.version>2.12scala.version>
<flink.version>1.17.0flink.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clientsartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-jsonartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
dependencies>
二、File、Socket、Collection介绍及示例
1、基于文件
- readTextFile(path) - 读取文本文件,例如遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。
- readFile(fileInputFormat, path) - 按照指定的文件输入格式读取(一次)文件。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是前两个方法内部调用的方法。它基于给定的 fileInputFormat 读取路径 path 上的文件。根据提供的 watchType 的不同,source 可能定期(每 interval 毫秒)监控路径上的新数据(watchType 为 FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次当前路径中的数据然后退出(watchType 为 FileProcessingMode.PROCESS_ONCE)。使用 pathFilter,用户可以进一步排除正在处理的文件。
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,当一个文件被修改时,它的内容会被完全重新处理。这可能会打破 “精确一次” 的语义,因为在文件末尾追加数据将导致重新处理文件的所有内容。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,source 扫描一次路径然后退出,无需等待 reader 读完文件内容。当然,reader 会继续读取数据,直到所有文件内容都读完。关闭 source 会导致在那之后不再有检查点。这可能会导致节点故障后恢复速度变慢,因为作业将从最后一个检查点恢复读取。
要运行本示例,需要准备好测试的数据文件,包括验证hdfs文件(需要有hadoop的环境)。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.io.FilePathFilter;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ContinuousFileMonitoringFunction;
import org.apache.flink.streaming.api.functions.source.ContinuousFileReaderOperatorFactory;
import org.apache.flink.streaming.api.functions.source.FileProcessingMode;
import org.apache.flink.streaming.api.functions.source.TimestampedFileInputSplit;
/**
* @author alanchan
*/
public class TestFileSourceDemo {
static String fileDir = "D:\\workspace\\flink1.17-java\\testdatadir\\";
public static void readTextFile() throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// 读取单个文件
DataStream<String> ds1 = env.readTextFile(fileDir + "file/words.txt");
// 读取文件夹
DataStream<String> ds2 = env.readTextFile(fileDir + "files");
// 读取压缩文件
DataStream<String> ds3 = env.readTextFile(fileDir + "zipfile/words.tar.gz");
// 读取hdfs文件
DataStream<String> ds4 = env.readTextFile("hdfs://server1:8020flinktest/words/1");
// transformation
// sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
// execute
env.execute();
}
public static void readFormatTextFile() throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// env.readTextFile(filePath)
// env.readFile(inputFormat, filePath)
// env.readTextFile(filePath, charsetName)
// env.readFileStream(filePath, intervalMillis, watchType)
// env.readFile(inputFormat, filePath, watchType, interval);
// env.readFile(inputFormat, filePath, watchType, interval, filter)
// env.readFile(inputFormat, filePath, watchType, interval, typeInformation)
Path path = new Path(fileDir + "file/words.txt");
TextInputFormat inputFormat = new TextInputFormat(path);
inputFormat.setFilesFilter(FilePathFilter.createDefaultFilter());
inputFormat.setCharsetName("UTF-8");
inputFormat.setFilePath(path);
ContinuousFileMonitoringFunction<String> continuousFileMonitoringFunction = new ContinuousFileMonitoringFunction<>(inputFormat, FileProcessingMode.PROCESS_ONCE,
env.getParallelism(), -1);
ContinuousFileReaderOperatorFactory<String, TimestampedFileInputSplit> continuousFileReaderOperatorFactory = new ContinuousFileReaderOperatorFactory<>(inputFormat);
String sourceName = "FileMonitoring";
SingleOutputStreamOperator<String> ds = env.addSource(continuousFileMonitoringFunction, sourceName).transform("Split Reader: " + sourceName, BasicTypeInfo.STRING_TYPE_INFO,
continuousFileReaderOperatorFactory);
// transformation
// sink
ds.print();
// execute
env.execute();
}
public static void main(String[] args) throws Exception {
// readTextFile();
readFormatTextFile();
}
}
2、基于套接字
socketTextStream - 从套接字读取。元素可以由分隔符分隔。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
* 在192.168.10.42上使用nc -lk 9999 向指定端口发送数据
* nc是netcat的简称,原本是用来设置路由器,我们可以利用它向某个端口发送数据
* 如果没有该命令可以下安装 yum install -y nc
*/
public class TestSocketSourceDemo {
public static void main(String[] args) throws Exception {
//env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//source
DataStream<String> lines = env.socketTextStream("192.168.10.42", 9999);
//transformation
/*SingleOutputStreamOperator words = lines.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out) throws Exception {
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});
words.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
return Tuple2.of(value,1);
}
});*/
//注意:下面的操作将上面的2步合成了1步,直接切割单词并记为1返回
// SingleOutputStreamOperator> wordAndOne = lines.flatMap(new FlatMapFunction>() {
// @Override
// public void flatMap(String value, Collector> out) throws Exception {
// String[] arr = value.split(" ");
// for (String word : arr) {
// out.collect(Tuple2.of(word, 1));
// }
// }
// });
//
// SingleOutputStreamOperator> result = wordAndOne.keyBy(t -> t.f0).sum(1);
//sink
lines.print();
//execute
env.execute();
}
}
3、基于集合
- fromCollection(Collection) - 从 Java Java.util.Collection 创建数据流。集合中的所有元素必须属于同一类型。
- fromCollection(Iterator, Class) - 从迭代器创建数据流。class 参数指定迭代器返回元素的数据类型。
- fromElements(T …) - 从给定的对象序列中创建数据流。所有的对象必须属于同一类型。
- fromParallelCollection(SplittableIterator, Class) - 从迭代器并行创建数据流。class 参数指定迭代器返回元素的数据类型。
- generateSequence(from, to) - 基于给定间隔内的数字序列并行生成数据流。
import java.util.Arrays;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestCollectionSourceDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// env.fromElements(可变参数);
DataStream<String> ds1 = env.fromElements("i am alanchan", "i like flink");
// env.fromColletion(各种集合)
DataStream<String> ds2 = env.fromCollection(Arrays.asList("i am alanchan", "i like flink"));
// env.generateSequence(开始,结束);
DataStream<Long> ds3 = env.generateSequence(1, 10);// 已过期,使用fromSequence方法
// env.fromSequence(开始,结束)
DataStream<Long> ds4 = env.fromSequence(1, 100);
// transformation
// sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
// execute
env.execute();
}
}
三、自定义、mysql介绍及示例
1、自定义Source介绍及示例
Flink提供了数据源接口,实现该接口就可以实现自定义数据源,不同的接口有不同的功能,分类如下:
- SourceFunction,非并行数据源,并行度只能=1
- RichSourceFunction,多功能非并行数据源,并行度只能=1
- ParallelSourceFunction,并行数据源,并行度能够>=1
- RichParallelSourceFunction,多功能并行数据源,并行度能够>=1
1)、示例-自定义数据源
本示例展示如何实现自定义数据源,并通过随机数产生数据信息,比较简单。
1、java bean
如果使用其自定义的数据结构也可以,视情况需要。
package org.datastreamapi.source.custom.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private long clicks;
private long ranks;
private Long createTime;
}
2、自定义数据源实现
继承RichParallelSourceFunction,并源源不断的产生数据,直到自己手动停止其运行或将启停标志flag设置成false。
package org.datastreamapi.source.custom;
import java.util.Random;
import java.util.UUID;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.datastreamapi.source.custom.bean.User;
/**
* @author alanchan
*
*/
public class CustomUserSource extends RichParallelSourceFunction<User> {
private boolean flag = true;
// 生产数据
@Override
public void run(SourceContext<User> ctx) throws Exception {
Random random = new Random();
while (flag) {
ctx.collect(new User(random.nextInt(100000001), "alanchan" + UUID.randomUUID().toString(), random.nextInt(9000001), random.nextInt(10001), System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
}
3、使用自定义的数据源
本部分是使用上面定义的数据源。和使用其他数据源就一句代码的不同,即如下
DataStream<User> userDS = env.addSource(new CustomUserSource());
完整的示例如下
package org.datastreamapi.source.custom;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.source.custom.bean.User;
/**
* @author alanchan
*
*/
public class TestCustomSourceDemo {
/**
* @param args
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source,设置并行度是看每次产生多少条数据
DataStream<User> userDS = env.addSource(new CustomUserSource()).setParallelism(2);
// transformation
// sink
userDS.print();
// execute
env.execute();
}
}
4、自定义数据源验证
运行TestCustomSourceDemo.java查看运行结果,本示例运行结果如下(每次运行结果均不同,供参考)
7> User(id=14317087, name=alanchan4ea184fd-472d-429c-b1b5-8fc16ba8c373, clicks=1815669, ranks=9648, createTime=1701824325507)
9> User(id=35956856, name=alanchanb715dab7-d3cb-40f3-b9e8-e0ba76d8b998, clicks=8888642, ranks=8143, createTime=1701824325507)
10> User(id=46536055, name=alanchan2aa31683-1af3-4d0b-81b6-c89265ba63f4, clicks=3766665, ranks=3282, createTime=1701824326536)
8> User(id=55937607, name=alanchan2ef54410-eaa4-47ed-8531-478957143051, clicks=5684939, ranks=8006, createTime=1701824326536)
9> User(id=92498863, name=alanchan1a324cdf-7ee6-4c6b-8059-7db01648428d, clicks=7199973, ranks=8005, createTime=1701824327552)
11> User(id=67794502, name=alanchanc73d8f15-abeb-4b86-9809-98094439e25c, clicks=654744, ranks=6799, createTime=1701824327552)
以上就完整的介绍了一个自定义数据源的过程,其中使用场景视情况而定。
2、自定义数据源-MySQL
上述示例中展示了自定义数据源的一种方式,就是自己产生数据或者其他的数据源获取,本示例展示的是以mysql数据源作为flink的数据源的实现。flink本身没有实现mysql数据源,需要自己实现。
1)、maven依赖
本示例需要新增mysql的依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
2)、java bean
package org.datastreamapi.source.custom.mysql.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
3)、mysql自定义数据源实现
package org.datastreamapi.source.custom.mysql;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.datastreamapi.source.custom.mysql.bean.User;
/**
* @author alanchan
*
*/
public class CustomMySQLSource extends RichParallelSourceFunction<User> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
String sql = "select id,name,pwd,email,age,balance from user";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<User> ctx) throws Exception {
while (flag) {
rs = ps.executeQuery();
while (rs.next()) {
User user = new User(rs.getInt("id"), rs.getString("name"), rs.getString("pwd"), rs.getString("email"), rs.getInt("age"), rs.getDouble("balance"));
ctx.collect(user);
}
//每5秒查询一次数据库
Thread.sleep(5000);
}
}
@Override
public void cancel() {
flag = false;
}
}
4)、使用mysql自定义的数据源
本部分是使用上面定义的数据源。和使用其他数据源就一句代码的不同,即如下
DataStream<User> userDS = env.addSource(new CustomMySQLSource()).setParallelism(1);
完整示例如下:
package org.datastreamapi.source.custom.mysql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.source.custom.mysql.bean.User;
/**
* @author alanchan
*
*/
public class TestCustomMySQLSourceDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<User> userDS = env.addSource(new CustomMySQLSource()).setParallelism(1);
// transformation
// sink
userDS.print();
// execute
env.execute();
}
}
5)、验证
1、准备mysql环境-建库表
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` smallint(6) NULL DEFAULT NULL,
`balance` double(255, 0) NULL DEFAULT NULL,
`email` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pwd` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2、启动TestCustomMySQLSourceDemo.java
启动TestCustomMySQLSourceDemo.java程序,并观察控制台输出。
3、往user表中添加数据,并观察应用程序控制台输出
- user 表数据
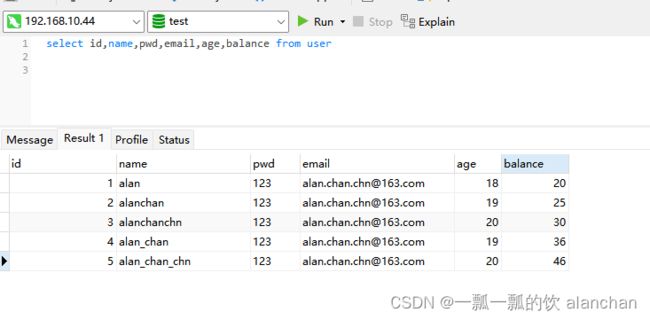
- 程序控制台输出(每5秒输出一次)
2> User(id=1, name=alan, pwd=123, email=[email protected], age=18, balance=20.0)
4> User(id=3, name=alanchanchn, pwd=123, email=[email protected], age=20, balance=30.0)
6> User(id=5, name=alan_chan_chn, pwd=123, email=[email protected], age=20, balance=46.0)
3> User(id=2, name=alanchan, pwd=123, email=[email protected], age=19, balance=25.0)
5> User(id=4, name=alan_chan, pwd=123, email=[email protected], age=19, balance=36.0)
四、redis -异步读取介绍及示例
1、redis环境及相关内容说明
1、本示例是需要redis环境的,至于redis是集群或单击和本示例关系不大。
关于redis的更多信息请参考其官网。
2、本示例是以redis作为外部数据进行异步交互的例子,也是实际中应用中常见的例子。关于异步数据交互参考文章:55、Flink之用于外部数据访问的异步 I/O
2、redis作为Flink的source异步数据交互示例
本示例是模拟根据外部数据用户姓名查询redis中用户的个人信息。
本示例外部数据就以flink的集合作为示例,redis数据中存储的为hash表,下面验证中会有具体展示。
1)、maven依赖
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.12artifactId>
<version>1.1.0version>
<exclusions>
<exclusion>
<artifactId>flink-streaming-java_2.12artifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
<exclusion>
<artifactId>flink-runtime_2.12artifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
<exclusion>
<artifactId>flink-coreartifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
<exclusion>
<artifactId>flink-javaartifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
exclusions>
dependency>
2)、redis异步交互数据实现
1、读取redis数据时以string进行输出
package org.datastreamapi.source.custom.redis;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Supplier;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import com.sun.jdi.IntegerValue;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @author alanchan
*
*/
public class CustomRedisSource extends RichAsyncFunction<String, String> {
private JedisPoolConfig config = null;
private static String ADDR = "192.168.10.41";
private static int PORT = 6379;
// 等待可用连接的最大时间,单位是毫秒,默认是-1,表示永不超时
private static int TIMEOUT = 10000;
private JedisPool jedisPool = null;
private Jedis jedis = null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
config = new JedisPoolConfig();
jedisPool = new JedisPool(config, ADDR, PORT, TIMEOUT);
jedis = jedisPool.getResource();
}
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception {
// 文件中读取的内容
System.out.println("输入参数input----:" + input);
// 发起一个异步请求,返回结果
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
String[] arrayData = input.split(",");
String name = arrayData[1];
String value = jedis.hget("AsyncReadUser_Redis", name);
System.out.println("查询结果output----:" + value);
return value;
}
}).thenAccept((String dbResult) -> {
// 设置请求完成时的回调,将结果返回
resultFuture.complete(Collections.singleton(dbResult));
});
}
// 连接超时的时候调用的方法
@Override
public void timeout(String input, ResultFuture<String> resultFuture) throws Exception {
System.out.println("redis connect timeout!");
}
@Override
public void close() throws Exception {
super.close();
if (jedis.isConnected()) {
jedis.close();
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class User {
private int id;
private String name;
private int age;
private double balance;
User(String value) {
String[] str = value.split(",");
this.setId(Integer.valueOf(str[0]));
this.setName(str[1]);
this.setAge(Integer.valueOf(str[2]));
this.setBalance(Double.valueOf(str[0]));
}
}
}
2、读取redis数据时以pojo进行输出
package org.datastreamapi.source.custom.redis;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Supplier;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.datastreamapi.source.custom.redis.CustomRedisSource.User;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @author alanchan
*
*/
public class CustomRedisSource2 extends RichAsyncFunction<String, User> {
private JedisPoolConfig config = null;
private static String ADDR = "192.168.10.41";
private static int PORT = 6379;
// 等待可用连接的最大时间,单位是毫秒,默认是-1,表示永不超时
private static int TIMEOUT = 10000;
private JedisPool jedisPool = null;
private Jedis jedis = null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
config = new JedisPoolConfig();
jedisPool = new JedisPool(config, ADDR, PORT, TIMEOUT);
jedis = jedisPool.getResource();
}
@Override
public void asyncInvoke(String input, ResultFuture<User> resultFuture) throws Exception {
System.out.println("输入查询条件:" + input);
CompletableFuture.supplyAsync(new Supplier<User>() {
@Override
public User get() {
String[] arrayData = input.split(",");
String name = arrayData[1];
String value = jedis.hget("AsyncReadUser_Redis", name);
System.out.println("查询redis结果:" + value);
return new User(value);
}
}).thenAccept((User dbResult) -> {
// 设置请求完成时的回调,将结果返回
resultFuture.complete(Collections.singleton(dbResult));
});
}
// 连接超时的时候调用的方法
@Override
public void timeout(String input, ResultFuture<User> resultFuture) throws Exception {
System.out.println("redis connect timeout!");
}
@Override
public void close() throws Exception {
super.close();
if (jedis.isConnected()) {
jedis.close();
}
}
}
3)、使用示例
package org.datastreamapi.source.custom.redis;
import java.util.concurrent.TimeUnit;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.source.custom.redis.CustomRedisSource.User;
/**
* @author alanchan
*
*/
public class TestCustomRedisSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// id,name
DataStreamSource<String> lines = env.fromElements("1,alan", "2,alanchan", "3,alanchanchn", "4,alan_chan", "5,alan_chan_chn");
SingleOutputStreamOperator<String> result = AsyncDataStream.orderedWait(lines, new CustomRedisSource(), 10, TimeUnit.SECONDS, 1);
SingleOutputStreamOperator<User> result2 = AsyncDataStream.orderedWait(lines, new CustomRedisSource2(), 10, TimeUnit.SECONDS, 1);
result.print("result-->").setParallelism(1);
result2.print("result2-->").setParallelism(1);
env.execute();
}
}
4)、验证
1、准备redis环境数据
hset AsyncReadUser_Redis alan '1,alan,18,20,[email protected]'
hset AsyncReadUser_Redis alanchan '2,alanchan,19,25,[email protected]'
hset AsyncReadUser_Redis alanchanchn '3,alanchanchn,20,30,[email protected]'
hset AsyncReadUser_Redis alan_chan '4,alan_chan,27,20,[email protected]'
hset AsyncReadUser_Redis alan_chan_chn '5,alan_chan_chn,36,10,[email protected]'
127.0.0.1:6379> hset AsyncReadUser_Redis alan '1,alan,18,20,[email protected]'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alanchan '2,alanchan,19,25,[email protected]'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alanchanchn '3,alanchanchn,20,30,[email protected]'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alan_chan '4,alan_chan,27,20,[email protected]'
(integer) 1
127.0.0.1:6379> hset AsyncReadUser_Redis alan_chan_chn '5,alan_chan_chn,36,10,[email protected]'
(integer) 1
127.0.0.1:6379> hgetall AsyncReadUser_Redis
1) "alan"
2) "1,alan,18,20,[email protected]"
3) "alanchan"
4) "2,alanchan,19,25,[email protected]"
5) "alanchanchn"
6) "3,alanchanchn,20,30,[email protected]"
7) "alan_chan"
8) "4,alan_chan,27,20,[email protected]"
9) "alan_chan_chn"
10) "5,alan_chan_chn,36,10,[email protected]"
2、启动应用程序,并观察控制台输出
输入查询条件:5,alan_chan_chn
输入参数input----:2,alanchan
输入参数input----:5,alan_chan_chn
输入查询条件:3,alanchanchn
输入查询条件:1,alan
输入参数input----:1,alan
输入查询条件:2,alanchan
输入查询条件:4,alan_chan
输入参数input----:4,alan_chan
输入参数input----:3,alanchanchn
查询结果output----:3,alanchanchn,20,30,[email protected]
查询redis结果:1,alan,18,20,[email protected]
查询结果output----:1,alan,18,20,[email protected]
查询redis结果:4,alan_chan,27,20,[email protected]
查询redis结果:2,alanchan,19,25,[email protected]
查询结果output----:2,alanchan,19,25,[email protected]
查询redis结果:3,alanchanchn,20,30,[email protected]
查询结果output----:4,alan_chan,27,20,[email protected]
查询结果output----:5,alan_chan_chn,36,10,[email protected]
查询redis结果:5,alan_chan_chn,36,10,[email protected]
result-->> 4,alan_chan,27,20,[email protected]
result-->> 5,alan_chan_chn,36,10,[email protected]
result-->> 3,alanchanchn,20,30,[email protected]
result-->> 2,alanchan,19,25,[email protected]
result-->> 1,alan,18,20,[email protected]
result2-->> CustomRedisSource.User(id=4, name=alan_chan, age=27, balance=4.0)
result2-->> CustomRedisSource.User(id=1, name=alan, age=18, balance=1.0)
result2-->> CustomRedisSource.User(id=3, name=alanchanchn, age=20, balance=3.0)
result2-->> CustomRedisSource.User(id=5, name=alan_chan_chn, age=36, balance=5.0)
result2-->> CustomRedisSource.User(id=2, name=alanchan, age=19, balance=2.0)
五、clickhouse介绍及示例
1、关于clickhouse的介绍
关于clickhouse的基本知识详见该系列文章,关于该部分不再赘述。
ClickHouse系列文章
1、ClickHouse介绍
2、clickhouse安装与简单验证(centos)
3、ClickHouse表引擎-MergeTree引擎
4、clickhouse的Log系列表引擎、外部集成表引擎和其他特殊的表引擎介绍及使用
5、ClickHouse查看数据库容量、表的指标、表分区、数据大小等
2、clickhouse作为Flink的source示例
1)、maven依赖
<dependency>
<groupId>ru.yandex.clickhousegroupId>
<artifactId>clickhouse-jdbcartifactId>
<version>0.1.40version>
dependency>
2)、实现
1、user bean
import lombok.Data;
/**
* @author alanchan
*
*/
@Data
public class UserSource {
private int id;
private String name;
private int age;
public UserSource(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public UserSource() {
}
}
2、source实现
import java.sql.ResultSet;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import ru.yandex.clickhouse.ClickHouseConnection;
import ru.yandex.clickhouse.ClickHouseDataSource;
import ru.yandex.clickhouse.ClickHouseStatement;
import ru.yandex.clickhouse.settings.ClickHouseProperties;
import ru.yandex.clickhouse.settings.ClickHouseQueryParam;
/**
* @author alanchan
*
*/
public class Source_Clickhouse {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<UserSource> users = env.addSource(new ClickhouseSource());
// transformation
// sink
users.print();
// execute
env.execute();
}
private static class ClickhouseSource extends RichParallelSourceFunction<UserSource> {
private boolean flag = true;
private ClickHouseConnection conn = null;
private ClickHouseStatement stmt = null;
private ResultSet rs = null;
private Map<ClickHouseQueryParam, String> additionalDBParams = new HashMap<>();
UserSource user = null;
private String sql = "select id,name,age from t_flink_sink_clickhouse";
// open只执行一次,适合开启资源
@Override
public void open(Configuration parameters) throws Exception {
ClickHouseProperties properties = new ClickHouseProperties();
String url = "jdbc:clickhouse://192.168.10.42:8123/tutorial";
properties.setSessionId(UUID.randomUUID().toString());
// properties.setDatabase("tutorial");
// properties.setHost("192.168.10.42");
ClickHouseDataSource dataSource = new ClickHouseDataSource(url, properties);
// ClickHouseProperties
additionalDBParams.put(ClickHouseQueryParam.SESSION_ID, UUID.randomUUID().toString());
conn = dataSource.getConnection();
stmt = conn.createStatement();
}
@Override
public void run(SourceContext<UserSource> ctx) throws Exception {
while (flag) {
rs = stmt.executeQuery(sql, additionalDBParams);
while (rs.next()) {
user = new UserSource(rs.getInt(1), rs.getString(2), rs.getInt(3));
ctx.collect(user);
}
}
}
// 接收到cancel命令时取消数据生成
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
if (conn != null)
conn.close();
if (stmt != null)
stmt.close();
if (rs != null)
rs.close();
}
}
}
3)、验证
启动应用程序,查看应用程序控制台输出是不是与期望的一致即可。
1、clickhouse数据源准备
1、启动clickhouse服务
2、创建数据库 tutorial
3、创建表 t_flink_sink_clickhouse
4、插入数据并查询
server2 :) select * from t_flink_sink_clickhouse limit 10;
SELECT *
FROM t_flink_sink_clickhouse
LIMIT 10
Query id: cd8bbe95-e8b0-448d-a7e2-dae3b5b2602d
┌─id─┬─name─────┬─age─┐
│ 1 │ alanchan │ 19 │
│ 2 │ alan │ 20 │
│ 3 │ chan │ 21 │
└────┴──────────┴─────┘
3 rows in set. Elapsed: 0.052 sec.
2、启动应用程序并观察控制台输出
由于本应用程序未设置查询频率,所以会一直输出,可以设置以一定的频率来查询。
4> UserSource(id=1, name=alanchan, age=19)
4> UserSource(id=2, name=alan, age=20)
4> UserSource(id=3, name=chan, age=21)
六、kafka介绍及示例
1、环境或版本说明
1、该示例需要有kafka的运行环境,kafka的部署与使用参考文章:
1、kafka(2.12-3.0.0)介绍、部署及验证、基准测试
2、Flink关于kafka的使用在不同的版本中有不同的实现,最直观的的变化是由FlinkKafkaConsumer换成了KafkaSource,同理sink也有相应的由FlinkKafkaProducer换成了KafkaSink。
3、由于使用kafka涉及的内容较多,请参考文章:
40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
4、本文会提供关于kafka 作为source的2个版本,即1.13.6和1.17的版本。
5、以下属性在构建 KafkaSource 时是必须指定的:
- Bootstrap server,通过 setBootstrapServers(String) 方法配置
- 消费者组 ID,通过 setGroupId(String) 配置
- 要订阅的 Topic / Partition
- 用于解析 Kafka 消息的反序列化器(Deserializer)
2、自定义数据源kafka(Flink 1.13.6 版本)
Kafka Source 提供了构建类来创建 FlinkKafkaConsumer 的实例。
以下代码片段展示了如何构建 FlinkKafkaConsumer 来消费 “alan_kafkasource” 最早位点的数据, 使用消费组 “flink_kafka”,并且将 Kafka 消息体反序列化为字符串
1)、maven依赖
<properties>
<encoding>UTF-8encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<java.version>1.8java.version>
<scala.version>2.12scala.version>
<flink.version>1.13.6flink.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.11artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_2.11artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.11artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.11artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-sql-connector-kafka_2.12artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-jsonartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.7version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
<scope>runtimescope>
dependency>
dependencies>
2)、实现
package org.datastreamapi.source.custom.kafka;
import java.util.Properties;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class TestCustomKafkaSourceDemo {
public static void main(String[] args) throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
// 准备kafka连接参数
Properties props = new Properties();
// 集群地址
props.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");
// 消费者组id
props.setProperty("group.id", "flink_kafka");
// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("auto.offset.reset", "latest");
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
// 自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
props.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
props.setProperty("auto.commit.interval.ms", "2000");
// 使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("alan_kafkasource", new SimpleStringSchema(), props);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
}
3)、验证
1、创建kafka主题alan_kafkasource,kafka命令发送数据
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic alan_kafkasource --partitions 1 --replication-factor 1
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,20
2、启动应用程序,并观察控制台输出

3、自定义数据源kafka(Flink 1.17.0 版本)
Kafka Source 提供了构建类来创建 KafkaSource 的实例。
以下代码片段展示了如何构建 KafkaSource 来消费 “alan_kafkasource” 最早位点的数据, 使用消费组 “flink_kafka”,并且将 Kafka 消息体反序列化为字符串
1)、maven依赖
<properties>
<encoding>UTF-8encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<java.version>1.8java.version>
<scala.version>2.12scala.version>
<flink.version>1.17.0flink.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clientsartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-jsonartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafkaartifactId>
<version>${flink.version}version>
dependency>
dependencies>
2)、实现
为了避免误解,1.13.6版本与1.17.0版本实现不同的地方KafkaSource和FlinkKafkaConsumer的不同,相关属性值是一样的,只是本例中没有将1.13.5的中的所有属性都列出来。
package org.datastreamapi.source.custom.kafka;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class TestCustomKafkaSourceDemo {
public static void main(String[] args) throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_kafkasource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
}
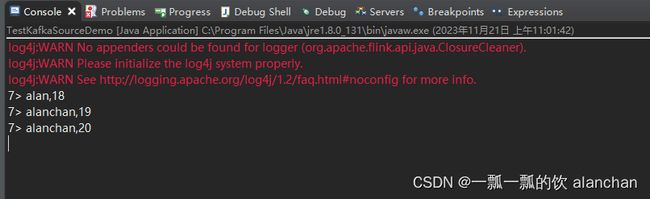
3)、验证
1、创建kafka主题alan_kafkasource,kafka命令发送数据
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic alan_kafkasource --partitions 1 --replication-factor 1
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,20
2、启动应用程序,并观察控制台输出
以上,本文主要介绍Flink 的source内置(基于文件、集合和socket)、自定义、mysql、kafka、redis和clickhouse的实现,每种source的实现均给出具体的实现例子以及验证结果。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章:
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(1) - File、Socket、Collection
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(3)- kafka
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(4)- redis -异步读取
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(5)- clickhouse
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版