Python中文分析:《射雕英雄传》统计人物出场次数、生成词云图片文件、根据人物关系做社交关系网络和其他文本分析
前言
python中文分析作业,将对《射雕英雄传》进行中文分析,统计人物出场次数、生成词云图片文件、根据人物关系做社交关系网络和其他文本分析等。
对应内容
1.中文分词,统计人物出场次数,保存到词频文件中,文件内容为出场次数最多的前 300 人(可大于 300)的姓名和次数
# -*- coding: utf-8 -*-
import jieba
def getText(filepath): # 传入待读取文件的文件名
f = open(filepath, "r", encoding='utf-8')
text = f.read()
f.close()
return text # 返回读出的文本数据
# 定义停用词库
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
def wordFreq(filepath, text, topn):
words = jieba.lcut(text.strip())
counts = {}
stopwords = stopwordslist('stop_words.txt')
for word in words:
if len(word) == 1:
continue
elif word not in stopwords:
if word == "黄蓉道" or word == "黄蓉笑" or word == "黄蓉见" or word == "黄蓉心":
word = "黄蓉"
elif word == "郭靖道" or word == "靖哥哥" or word == "郭靖心" or word == "郭靖见" or word == "郭靖听" or word == "郭靖大":
word = "郭靖"
elif word == "老顽童":
word = "周伯通"
elif word == "老毒物":
word = "欧阳锋"
elif word == "成吉思汗":
word = "铁木真"
elif word == "黄老邪":
word = "黄药师"
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 排序
f = open(filepath[:-4] + '_词频.txt', "w")
for i in range(topn):
word, count = items[i]
f.writelines("{}\t{}\n".format(word, count))
f.close()
text = getText('射雕英雄传.txt')
wordFreq('射雕英雄传.txt', text, 300)
print('统计结束')
2.利用分析结果生成词云图片文性,要求:使用黑体字、背景色为白色、宽度 1000 像素、高度 860 像素
import matplotlib.pyplot as plt
import wordcloud
f = open("射雕英雄传_词频.txt", 'r')
text = f.read()
f.close()
# 黑体字、白色背景、宽1000、高860
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf',
background_color="white", width=1000,
max_words=500,
height=860, margin=2).generate(text)
wcloud.to_file("射雕英雄传cloud—1.png") # 保存图片
# 显示词云图片
plt.imshow(wcloud)
plt.axis('off')
plt.show()
输出词云图片:

3.利用分析结果生成另一种字体词云图片文性
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import wordcloud
f = open("射雕英雄传_词频.txt", 'r')
text = f.read()
f.close()
# 改字体为华文行楷
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\STXINGKA.ttf',
background_color="white", width=1000,
max_words=500,
# mask=bg_pic, # mask参数设置词云形状
height=860, margin=2).generate(text)
wcloud.to_file("射雕英雄传cloud—2.png") # 保存图片
# 显示词云图片
plt.imshow(wcloud)
plt.axis('off')
plt.show()
输出:

4.利用形状,生成特定形状词云图片文性
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import wordcloud
from imageio import imread
bg_pic = imread('star.jpg') # 读入形状图片
f = open("射雕英雄传_词频.txt", 'r')
text = f.read()
f.close()
# 更改词云形状
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf',
background_color="white", width=1000,
max_words=500,
mask=bg_pic, # mask参数设置词云形状
height=860, margin=2).generate(text)
wcloud.to_file("射雕英雄传cloud—3.png") # 保存图片
# 显示词云图片
plt.imshow(wcloud)
plt.axis('off')
plt.show()
输出:

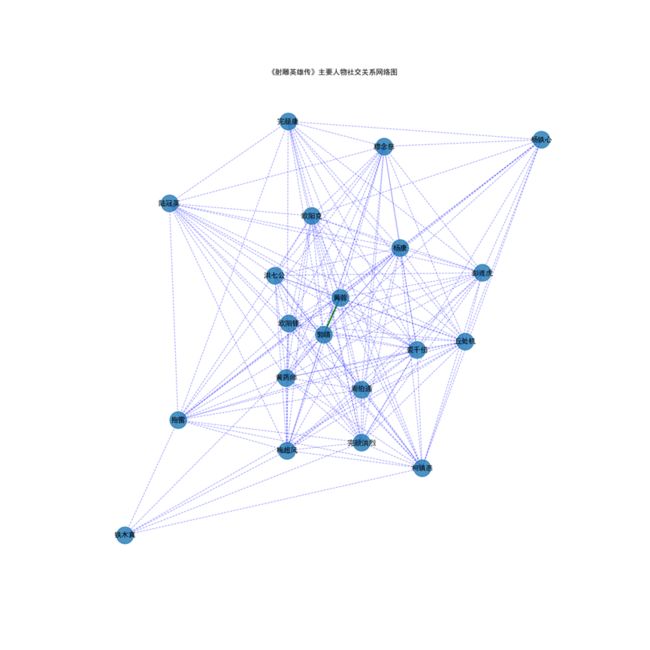
5.根据文中人物关系,做社交关系网络并截图保存
# -*- coding: utf-8 -*-
import networkx as nx
import matplotlib.pyplot as plt
import matplotlib
f = open('射雕英雄传.txt', 'r', encoding='utf-8')
s = f.read()
# 生成人物关系权重
Names = ['郭靖', '黄蓉', '洪七公', '欧阳锋', '黄药师', '周伯通', '丘处机', '欧阳克', '梅超风', '柯镇恶', '裘千仞', '铁木真',
'完颜洪烈', '穆念慈', '杨康', '完颜康', '彭连虎', '陆冠英', '拖雷', '杨铁心']
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
relations = {}
lst_para = s.split('\n') # 按段落划分,假设在同一段落中出现的人物具有共现关系
for text in lst_para:
for name1 in Names:
if name1 in text:
for name2 in Names:
if name2 in text and name1 != name2 and (name2, name1) not in relations:
relations[(name1, name2)] = relations.get((name1, name2), 0) + 1
print(relations.items())
maxRela = max([v for k, v in relations.items()])
relations = {k: v / maxRela for k, v in relations.items()}
print(relations.items(), maxRela)
plt.figure(figsize=(15, 15))
G = nx.Graph()
for k, v in relations.items():
G.add_edge(k[0], k[1], weight=v)
elarge = [(u, v) for (u, v, d) in G.edges(data=True)
if d['weight'] > 0.6]
emidle = [(u, v) for (u, v, d) in G.edges(data=True)
if (d['weight'] > 0.3) & (d['weight'] <= 0.6)]
esmall = [(u, v) for (u, v, d) in G.edges(data=True)
if d['weight'] <= 0.3]
pos = nx.spring_layout(G)
nx.draw_networkx_nodes(G, pos, alpha=0.8, node_size=800)
nx.draw_networkx_edges(G, pos, edgelist=elarge, width=2.5,
alpha=0.9, edge_color='g')
nx.draw_networkx_edges(G, pos, edgelist=emidle, width=1.5,
alpha=0.6, edge_color='y')
nx.draw_networkx_edges(G, pos, edgelist=esmall, width=1,
alpha=0.4, edge_color='b', style='dashed')
nx.draw_networkx_labels(G, pos, font_size=12)
plt.axis('off')
plt.title("《射雕英雄传》主要人物社交关系网络图")
plt.show()
输出:
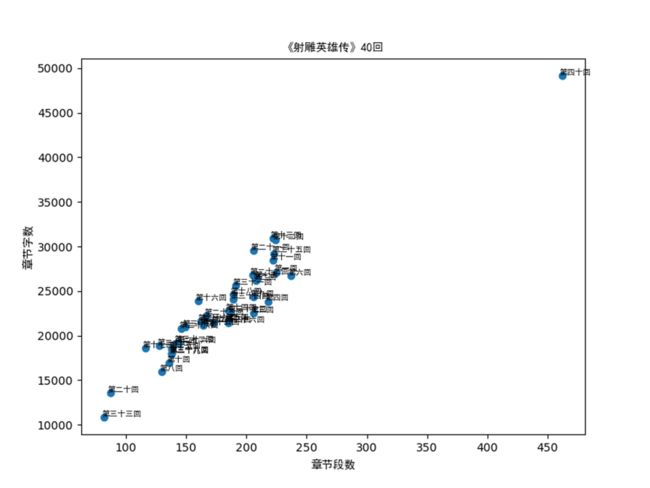
6.进一步中文分析,自选一种即可,结果截图保存
平均段落和字数
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import matplotlib
import re
# 分割章回
f = open('射雕英雄传.txt', 'r', encoding='utf-8')
s = f.read()
lst_chapter = []
chapter = re.findall("第[\u4E00-\u9FA5]+回", s) # "第([\u4E00-\u9FA5]+)回"返回第和回中间的内容
for x in chapter:
if x not in lst_chapter and len(x) <= 5:
lst_chapter.append(x)
print(lst_chapter)
lst_start_chapterindex = []
for x in lst_chapter:
lst_start_chapterindex.append(s.index(x))
print(lst_start_chapterindex)
lst_end_chapterindex = lst_start_chapterindex[1:] + [len(s)]
lst_chapterindex = list(zip(lst_start_chapterindex, lst_end_chapterindex))
print(lst_chapterindex)
# 计算每一回含有多少段、多少字
cnt_chap = []
cnt_word = []
for ii in range(40):
start = lst_chapterindex[ii][0]
end = lst_chapterindex[ii][1]
cnt_chap.append(s[start:end].count("\n"))
cnt_word.append(len(s[start:end]))
print(cnt_chap)
print(cnt_word)
# 字长和段落数的散点图
plt.figure(figsize=(8, 6))
plt.scatter(cnt_chap, cnt_word)
for ii in range(40):
plt.text(cnt_chap[ii] - 2, cnt_word[ii] + 100, lst_chapter[ii], fontproperties='SimHei', size=7)
plt.xlabel("章节段数", fontproperties='SimHei')
plt.ylabel("章节字数", fontproperties='SimHei')
plt.title("《射雕英雄传》40回", fontproperties='SimHei')
plt.show()