5、Grounded Segement Anything
github
sam安装与基本使用
stable diffusion安装与基本使用
安装GroundingDINO
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO
pip install -e .
pip install diffusers transformers accelerate scipy safetensors
安装RAM&Tag2Text
git clone https://github.com/xinyu1205/recognize-anything.git
pip install -r ./recognize-anything/requirements.txt
pip install -e ./recognize-anything/
安装OSX
git submodule update --init --recursive
cd grounded-sam-osx && bash install.sh
导入依赖
import os, sys
import argparse
import copy
from IPython.display import display
from PIL import Image, ImageDraw, ImageFont
from torchvision.ops import box_convert
# Grounding DINO
import groundingdino.datasets.transforms as T
from groundingdino.models import build_model
from groundingdino.util import box_ops
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
from groundingdino.util.inference import annotate, load_image, predict
import supervision as sv
# segment anything
from segment_anything import build_sam, SamPredictor
import cv2
import numpy as np
import matplotlib.pyplot as plt
# diffusers
import PIL
import requests
import torch
from io import BytesIO
from diffusers import StableDiffusionInpaintPipeline
from huggingface_hub import hf_hub_download
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
模型初始化
Load Grounding DINO model
权重
"""
Load Grounding DINO model
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "groundingdino_swinb_cogcoor.pth"
ckpt_config_filename = "GroundingDINO_SwinB.cfg.py"
could download from : https://huggingface.co/ShilongLiu/GroundingDINO/tree/main
"""
def load_grounding(repo_id, filename, ckpt_config_filename, is_path=False, device='cpu'):
if is_path:
cache_file = filename
cache_config_file = ckpt_config_filename
else:
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
cache_config_file = hf_hub_download(repo_id=repo_id, filename=ckpt_config_filename)
args = SLConfig.fromfile(cache_config_file)
model = build_model(args)
args.device = device
checkpoint = torch.load(cache_file, map_location='cpu')
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
print("Model loaded from {} \n => {}".format(cache_file, log))
_ = model.eval()
return model
if __name__ == '__main__':
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "groundingdino_swinb_cogcoor.pth"
ckpt_config_filename = "GroundingDINO_SwinB.cfg.py"
groundingdino_model = load_grounding(ckpt_repo_id, ckpt_filenmae, ckpt_config_filename)
Load SAM model
权重
def load_sam(model_type="vit_h", sam_checkpoint="/devdata/chengan/SAM_checkpoint/sam_vit_h_4b8939.pth", device="cuda"):
# sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
# sam.to(device=device)
sam = build_sam(checkpoint=sam_checkpoint)
sam.to(device=device)
sam_predictor = SamPredictor(sam)
return sam_predictor
Load stable diffusion inpainting models
def load_diffusion_inpaint(device="cuda"):
sd_pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float16,
).to(device)
return sd_pipe
基本使用
grounding samples use
def grounding_sample(text_prompt, image_path, box_treshold=0.3, text_treshold=0.25):
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "/devdata/chengan/GSAM_checkpoint/groundingino/groundingdino_swinb_cogcoor.pth"
ckpt_config_filename = "/devdata/chengan/GSAM_checkpoint/groundingino/GroundingDINO_SwinB.cfg.py"
groundingdino_model = load_grounding(ckpt_repo_id, ckpt_filenmae, ckpt_config_filename, is_path=True)
image_source, image = load_image(image_path)
boxes, logits, phrases = predict(
model=groundingdino_model,
image=image,
caption=text_prompt,
box_threshold=box_treshold,
text_threshold=text_treshold
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
annotated_frame = annotated_frame[..., ::-1] # BGR to RGB
plt.imshow(image_source)
plt.show()
plt.imshow(annotated_frame)
plt.show()
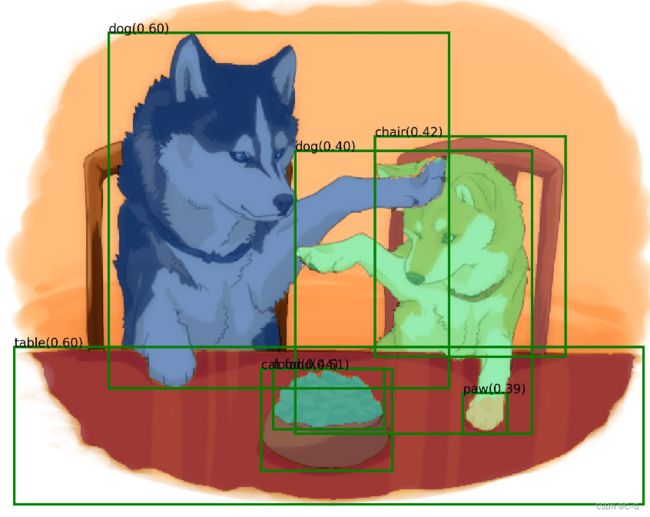
grounding_sample(text_prompt="huskie", image_path="../data/headImage.png")
检测 分割 替换
# Grounding DINO for detection
# detect object using grounding DINO
def detect(image, image_source, text_prompt, model, box_threshold=0.3, text_threshold=0.25):
boxes, logits, phrases = predict(
model=model,
image=image,
caption=text_prompt,
box_threshold=box_threshold,
text_threshold=text_threshold
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
annotated_frame = annotated_frame[..., ::-1] # BGR to RGB
return annotated_frame, boxes
# SAM for segmentation
def segment(image, sam_model, boxes):
sam_model.set_image(image)
H, W, _ = image.shape
boxes_xyxy = box_ops.box_cxcywh_to_xyxy(boxes) * torch.Tensor([W, H, W, H])
transformed_boxes = sam_model.transform.apply_boxes_torch(boxes_xyxy.to(device), image.shape[:2])
masks, _, _ = sam_model.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
return masks.cpu()
def draw_mask(mask, image, random_color=True):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.8])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
annotated_frame_pil = Image.fromarray(image).convert("RGBA")
mask_image_pil = Image.fromarray((mask_image.cpu().numpy() * 255).astype(np.uint8)).convert("RGBA")
return np.array(Image.alpha_composite(annotated_frame_pil, mask_image_pil))
def generate_image(image, mask, prompt, negative_prompt, pipe, seed):
# resize for inpainting
w, h = image.size
in_image = image.resize((512, 512))
in_mask = mask.resize((512, 512))
generator = torch.Generator(device).manual_seed(seed)
result = pipe(image=in_image, mask_image=in_mask, prompt=prompt, negative_prompt=negative_prompt,
generator=generator)
result = result.images[0]
return result.resize((w, h))
if __name__ == '__main__':
# image
image_path = "../data/headImage.png"
image_source, image = load_image(image_path)
plt.imshow(image_source)
plt.show()
# sam
sam_checkpoint = '/devdata/chengan/SAM_checkpoint/sam_vit_h_4b8939.pth'
sam_predictor = load_sam(sam_checkpoint=sam_checkpoint, device=device)
# grounding
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "/devdata/chengan/GSAM_checkpoint/groundingino/groundingdino_swinb_cogcoor.pth"
ckpt_config_filename = "/devdata/chengan/GSAM_checkpoint/groundingino/GroundingDINO_SwinB.cfg.py"
groundingdino_model = load_grounding(ckpt_repo_id, ckpt_filenmae, ckpt_config_filename, is_path=True, device=device)
# diffusion inpaint
sd_pipe = load_diffusion_inpaint(device=device)
# get detect box
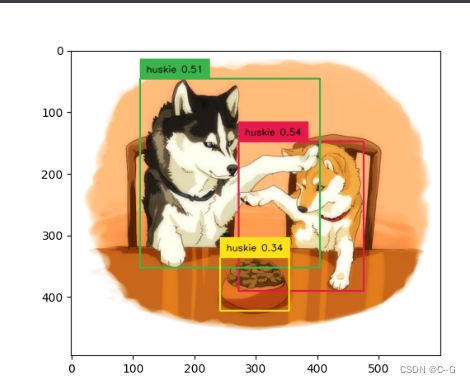
text_prompt = "huskie"
annotated_frame, detected_boxes = detect(image, image_source, text_prompt=text_prompt, model=groundingdino_model)
plt.imshow(annotated_frame)
plt.show()
# sam
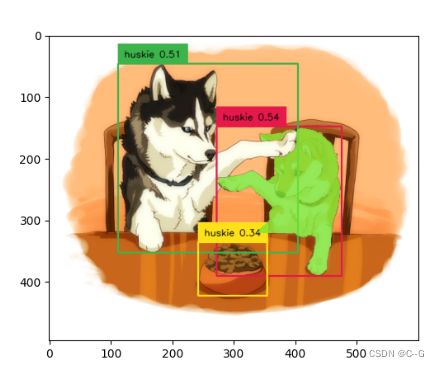
segmented_frame_masks = segment(image_source, sam_predictor, boxes=detected_boxes)
annotated_frame_with_mask = draw_mask(segmented_frame_masks[0][0], annotated_frame)
plt.imshow(annotated_frame_with_mask)
plt.show()
#
mask = segmented_frame_masks[0][0].cpu().numpy()
inverted_mask = ((1 - mask) * 255).astype(np.uint8)
image_source_pil = Image.fromarray(image_source)
image_mask_pil = Image.fromarray(mask)
inverted_image_mask_pil = Image.fromarray(inverted_mask)
plt.imshow(inverted_image_mask_pil)
plt.show()
prompt = "A lovely cat"
negative_prompt = "low resolution, ugly"
seed = 32 # for reproducibility
generated_image = generate_image(image=image_source_pil, mask=image_mask_pil, prompt=prompt,
negative_prompt=negative_prompt, pipe=sd_pipe, seed=seed)
plt.imshow(generated_image)
plt.show()
语义分割
sam_hq_checkpoint
import argparse
import os
import numpy as np
import json
import torch
import torchvision
from PIL import Image
# import litellm
# Grounding DINO
import groundingdino.datasets.transforms as T
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
# segment anything
from segment_anything import (
build_sam,
# build_sam_hq,
SamPredictor
)
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Recognize Anything Model & Tag2Text
from ram.models import ram
from ram import inference_ram
import torchvision.transforms as TS
from huggingface_hub import hf_hub_download
# ChatGPT or nltk is required when using tags_chineses
# import openai
# import nltk
def load_image(image_path):
# load image
image_pil = Image.open(image_path).convert("RGB") # load image
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
image, _ = transform(image_pil, None) # 3, h, w
return image_pil, image
def check_tags_chinese(tags_chinese, pred_phrases, max_tokens=100, model="gpt-3.5-turbo"):
object_list = [obj.split('(')[0] for obj in pred_phrases]
object_num = []
for obj in set(object_list):
object_num.append(f'{object_list.count(obj)} {obj}')
object_num = ', '.join(object_num)
print(f"Correct object number: {object_num}")
if openai_key:
prompt = [
{
'role': 'system',
'content': 'Revise the number in the tags_chinese if it is wrong. ' + \
f'tags_chinese: {tags_chinese}. ' + \
f'True object number: {object_num}. ' + \
'Only give the revised tags_chinese: '
}
]
response = litellm.completion(model=model, messages=prompt, temperature=0.6, max_tokens=max_tokens)
reply = response['choices'][0]['message']['content']
# sometimes return with "tags_chinese: xxx, xxx, xxx"
tags_chinese = reply.split(':')[-1].strip()
return tags_chinese
def load_grounding(filename, ckpt_config_filename, repo_id="ShilongLiu/GroundingDINO", is_path=False, device='cpu'):
if is_path:
cache_file = filename
cache_config_file = ckpt_config_filename
else:
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
cache_config_file = hf_hub_download(repo_id=repo_id, filename=ckpt_config_filename)
args = SLConfig.fromfile(cache_config_file)
model = build_model(args)
args.device = device
checkpoint = torch.load(cache_file, map_location='cpu')
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
print("Model loaded from {} \n => {}".format(cache_file, log))
_ = model.eval()
return model
def get_grounding_output(model, image, caption, box_threshold, text_threshold, device="cpu"):
caption = caption.lower()
caption = caption.strip()
if not caption.endswith("."):
caption = caption + "."
model = model.to(device)
image = image.to(device)
with torch.no_grad():
outputs = model(image[None], captions=[caption])
logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
logits.shape[0]
# filter output
logits_filt = logits.clone()
boxes_filt = boxes.clone()
filt_mask = logits_filt.max(dim=1)[0] > box_threshold
logits_filt = logits_filt[filt_mask] # num_filt, 256
boxes_filt = boxes_filt[filt_mask] # num_filt, 4
# get phrase
tokenlizer = model.tokenizer
tokenized = tokenlizer(caption)
# build pred
pred_phrases = []
scores = []
for logit, box in zip(logits_filt, boxes_filt):
pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)
pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
scores.append(logit.max().item())
return boxes_filt, torch.Tensor(scores), pred_phrases
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_box(box, ax, label):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
ax.text(x0, y0, label)
def save_mask_data(output_dir, tags_chinese, mask_list, box_list, label_list):
value = 0 # 0 for background
mask_img = torch.zeros(mask_list.shape[-2:])
for idx, mask in enumerate(mask_list):
mask_img[mask.cpu().numpy()[0] == True] = value + idx + 1
plt.figure(figsize=(10, 10))
plt.imshow(mask_img.numpy())
plt.axis('off')
plt.savefig(os.path.join(output_dir, 'mask.jpg'), bbox_inches="tight", dpi=300, pad_inches=0.0)
json_data = {
'tags_chinese': tags_chinese,
'mask': [{
'value': value,
'label': 'background'
}]
}
for label, box in zip(label_list, box_list):
value += 1
name, logit = label.split('(')
logit = logit[:-1] # the last is ')'
json_data['mask'].append({
'value': value,
'label': name,
'logit': float(logit),
'box': box.numpy().tolist(),
})
with open(os.path.join(output_dir, 'label.json'), 'w') as f:
json.dump(json_data, f)
if __name__ == "__main__":
parser = argparse.ArgumentParser("Grounded-Segment-Anything Demo", add_help=True)
parser.add_argument("--config", type=str, required=True, help="path to config file")
parser.add_argument(
"--ram_checkpoint", type=str, required=True, help="path to checkpoint file"
)
parser.add_argument(
"--grounded_checkpoint", type=str, required=True, help="path to checkpoint file"
)
parser.add_argument(
"--sam_checkpoint", type=str, required=True, help="path to checkpoint file"
)
parser.add_argument(
"--sam_hq_checkpoint", type=str, default=None, help="path to sam-hq checkpoint file"
)
parser.add_argument(
"--use_sam_hq", action="store_true", help="using sam-hq for prediction"
)
parser.add_argument("--input_image", type=str, required=True, help="path to image file")
parser.add_argument("--split", default=",", type=str, help="split for text prompt")
parser.add_argument("--openai_key", type=str, help="key for chatgpt")
parser.add_argument("--openai_proxy", default=None, type=str, help="proxy for chatgpt")
parser.add_argument(
"--output_dir", "-o", type=str, default="outputs", required=True, help="output directory"
)
parser.add_argument("--box_threshold", type=float, default=0.25, help="box threshold")
parser.add_argument("--text_threshold", type=float, default=0.2, help="text threshold")
parser.add_argument("--iou_threshold", type=float, default=0.5, help="iou threshold")
parser.add_argument("--device", type=str, default="cpu", help="running on cpu only!, default=False")
args = parser.parse_args()
# cfg
config_file = args.config # change the path of the model config file
ram_checkpoint = args.ram_checkpoint # change the path of the model
grounded_checkpoint = args.grounded_checkpoint # change the path of the model
sam_checkpoint = args.sam_checkpoint
sam_hq_checkpoint = args.sam_hq_checkpoint
use_sam_hq = args.use_sam_hq
image_path = args.input_image
split = args.split
openai_key = args.openai_key
openai_proxy = args.openai_proxy
output_dir = args.output_dir
box_threshold = args.box_threshold
text_threshold = args.text_threshold
iou_threshold = args.iou_threshold
device = args.device
# ChatGPT or nltk is required when using tags_chineses
# openai.api_key = openai_key
# if openai_proxy:
# openai.proxy = {"http": openai_proxy, "https": openai_proxy}
# make dir
os.makedirs(output_dir, exist_ok=True)
# load image
image_pil, image = load_image(image_path)
plt.imshow(image_pil)
plt.show()
# load grounding model
groundingding_model = load_grounding(grounded_checkpoint, config_file, is_path=True)
# visualize raw image
image_pil.save(os.path.join(output_dir, "raw_image.jpg"))
# initialize Recognize Anything Model
normalize = TS.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform = TS.Compose([
TS.Resize((384, 384)),
TS.ToTensor(), normalize
])
# load model
# https://recognize-anything.github.io
ram_model = ram(pretrained=ram_checkpoint,
image_size=384,
vit='swin_l')
# threshold for tagging
# we reduce the threshold to obtain more tags
ram_model.eval()
ram_model = ram_model.to(device)
raw_image = image_pil.resize(
(384, 384))
raw_image = transform(raw_image).unsqueeze(0).to(device)
res = inference_ram(raw_image, ram_model)
# Currently ", " is better for detecting single tags
# while ". " is a little worse in some case
tags = res[0].replace(' |', ',')
tags_chinese = res[1].replace(' |', ',')
print("Image Tags: ", res[0])
print("图像标签: ", res[1])
# run grounding dino model
boxes_filt, scores, pred_phrases = get_grounding_output(
groundingding_model, image, tags, box_threshold, text_threshold, device=device
)
# initialize SAM
if use_sam_hq:
print("Initialize SAM-HQ Predictor")
# predictor = SamPredictor(build_sam_hq(checkpoint=sam_hq_checkpoint).to(device))
else:
predictor = SamPredictor(build_sam(checkpoint=sam_checkpoint).to(device))
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image)
size = image_pil.size
H, W = size[1], size[0]
for i in range(boxes_filt.size(0)):
boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])
boxes_filt[i][:2] -= boxes_filt[i][2:] / 2
boxes_filt[i][2:] += boxes_filt[i][:2]
boxes_filt = boxes_filt.cpu()
# use NMS to handle overlapped boxes
print(f"Before NMS: {boxes_filt.shape[0]} boxes")
nms_idx = torchvision.ops.nms(boxes_filt, scores, iou_threshold).numpy().tolist()
boxes_filt = boxes_filt[nms_idx]
pred_phrases = [pred_phrases[idx] for idx in nms_idx]
print(f"After NMS: {boxes_filt.shape[0]} boxes")
tags_chinese = check_tags_chinese(tags_chinese, pred_phrases)
print(f"Revise tags_chinese with number: {tags_chinese}")
transformed_boxes = predictor.transform.apply_boxes_torch(boxes_filt, image.shape[:2]).to(device)
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes.to(device),
multimask_output=False,
)
# draw output image
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box, label in zip(boxes_filt, pred_phrases):
show_box(box.numpy(), plt.gca(), label)
# plt.title('RAM-tags' + tags + '\n' + 'RAM-tags_chineseing: ' + tags_chinese + '\n')
plt.axis('off')
plt.show()
plt.savefig(
os.path.join(output_dir, "automatic_label_output.jpg"),
bbox_inches="tight", dpi=300, pad_inches=0.0
)
save_mask_data(output_dir, tags_chinese, masks, boxes_filt, pred_phrases)
--config
/devdata/chengan/GSAM_checkpoint/groundingino/GroundingDINO_SwinB.cfg.py
--grounded_checkpoint
/devdata/chengan/GSAM_checkpoint/groundingino/groundingdino_swinb_cogcoor.pth
--sam_checkpoint
/devdata/chengan/SAM_checkpoint/sam_vit_h_4b8939.pth
--ram_checkpoint
/devdata/chengan/GSAM_checkpoint/ram/ram_swin_large_14m.pth
--input_image
../data/headImage.png
--output_dir
"outputs"
--box_threshold
0.3
--text_threshold
0.25
--device
"cuda"