Python学习之爬虫基础
目录
- 文章声明⭐⭐⭐
- 让我们开始今天的学习吧!
-
- requests库的基本使用
- BeautifulSoup解析HTML
- 我们还需要学习什么呢?
文章声明⭐⭐⭐
- 该文章为我(有编程语言基础,非编程小白)的 Python爬虫自学笔记
- 知识来源为 B站UP主(GenJi是真想教会你)的Python爬虫课程视频,归纳为自己的语言与理解记录于此并加以实践,爬取的网站为豆瓣电影和一个专门用于联系爬虫的书籍网站,但只用于笔记用途,合法又正规嗷家人们
- 关于爬虫,知识基础、概念我都不会记录于此,更多的是记录实践,即以具体实操代码的形式展现给大家
- 不出意外的话,我大抵会 持续更新
- 想要了解前端开发(技术栈大致有:Vue2/3、微信小程序、uniapp、HarmonyOS、NodeJS、Typescript)与Python的小伙伴,可以关注我!谢谢大家!
让我们开始今天的学习吧!
requests库的基本使用
小尝试
# 导入requests,当然你得确保pip安装了这个库
import requests
# 发送get请求
response = requests.get("http://books.toscrape.com/")
# 输出一下试试
print(response)
# 输出状态码
print(response.status_code)、
-------------------------------------
<Response [200]>
200
加以判断来完善
# 导入requests
import requests
# 发送get请求
response = requests.get("http://books.toscrape.com/")
# 加以判断完善一下
if response.status_code >= 200 and response.status_code < 400:
print("可以获取内容")
print(response)
elif response.status_code >= 400 and response.status_code < 500:
print("请求失败,客户端错误")
elif response.status_code >= 500:
print("请求失败,服务器错误")
else:
print("未知错误")
-------------------------------------
可以获取内容
<Response [200]>
使用response的ok属性来简化上一个例子
# 导入requests,当然你得确保pip安装了这个库
import requests
# 发送get请求
response = requests.get("http://books.toscrape.com/")
# 使用response的ok属性来简化上一个例子
if response.ok:
print("可以获取内容")
print(response)
else:
print("请求失败")
-------------------------------------
可以获取内容
<Response [200]>
使用response的text属性来获取响应体的内容
# 导入requests,当然你得确保pip安装了这个库
import requests
# 发送get请求
response = requests.get("http://books.toscrape.com/")
# 使用response的ok属性来判断
if response.ok:
print("可以获取内容")
print(response.text)
else:
print("请求失败")
-------------------------------------
可以获取内容
<!DOCTYPE html>
<!--[if lt IE 7]> <html lang="en-us" class="no-js lt-ie9 lt-ie8 lt-ie7"> <![endif]-->
<!--[if IE 7]> <html lang="en-us" class="no-js lt-ie9 lt-ie8"> <![endif]-->
<!--[if IE 8]> <html lang="en-us" class="no-js lt-ie9"> <![endif]-->
<!--[if gt IE 8]><!--> <html lang="en-us" class="no-js"> <!--<![endif]-->
<head>
<title>
All products | Books to Scrape - Sandbox
........................(响应体内容太多了,这里就不加以展示了)
requests库的函数帮我们自动生成了请求头的内容,当然我们也可以自己书写请求头,一般自行书写请求头用来把我们的爬虫程序伪装成正常浏览器,pycharm中代码如下:
# 导入requests,当然你得确保pip安装了这个库
import requests
# 自行书写header请求头,对象格式为字典
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
response = requests.get("http://books.toscrape.com/", headers=header)
# 使用response的ok属性来判断
if response.ok:
print("可以获取内容")
print(response.text)
else:
print("请求失败")
BeautifulSoup解析HTML
首先安装bs4这个库,再导入其中的BeautifulSoup这个类,我们先使用它的对象的p属性,来获取第一个p标签以及其子标签的全部内容,pycharm中代码如下:
# 导入requests
import requests
# 从bs4这个库中导入BeautifulSoup这个类
from bs4 import BeautifulSoup
# 自行书写header请求头,对象格式为字典
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
# 获取响应体内容
content = requests.get("https://movie.douban.com/top250", headers=header).text
# BeautifulSoup是个构造函数,我们来创建BeautifulSoup的对象
soup = BeautifulSoup(content,"html.parser")
# 获取第一个p标签以及其子标签的全部内容
print(soup.p)
-------------------------------------
<p class="appintro-title">豆瓣</p>
类似p属性,还有img、h1、div、span等等属性,都是获取HTML中的其第一个标签以及其子标签的全部内容,学过HTML的同学应该大致能明白,这些所谓的属性其实就是HTML中的一个个标签名
使用findAll方法来精准查询,string属性用于只获取标签中的内容,首先我们先尝试着获取一下当前页面每个电影的评分,图片和代码如下:

# 导入requests
import requests
# 从bs4这个库中导入BeautifulSoup这个类
from bs4 import BeautifulSoup
# 自行书写header请求头,对象格式为字典
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
# 获取响应体内容
content = requests.get("https://movie.douban.com/top250", headers=header).text
# BeautifulSoup是个构造函数,我们来创建BeautifulSoup的对象
soup = BeautifulSoup(content,"html.parser")
# 获取所有电影的评分,下面findAll方法是用来精准查询符合条件的标签,第一个参数为需要查询的标签名,第二个参数为拿来匹配的属性,是一个字典对象,findAll方法返回的是一个数组
movie_rating = soup.findAll("span",attrs={"class": "rating_num"})
# 遍历
print(movie_rating)
for rating in movie_rating:
print(rating.string)
-------------------------------------
[<span class="rating_num" property="v:average">9.7</span>, <span class="rating_num" property="v:average">9.6</span>, <span class="rating_num" property="v:average">9.5</span>, <span class="rating_num" property="v:average">9.5</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.5</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.5</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.3</span>, <span class="rating_num" property="v:average">9.2</span>, <span class="rating_num" property="v:average">9.3</span>, <span class="rating_num" property="v:average">9.3</span>, <span class="rating_num" property="v:average">9.2</span>, <span class="rating_num" property="v:average">9.3</span>, <span class="rating_num" property="v:average">9.6</span>, <span class="rating_num" property="v:average">9.2</span>, <span class="rating_num" property="v:average">9.4</span>, <span class="rating_num" property="v:average">9.3</span>, <span class="rating_num" property="v:average">9.3</span>, <span class="rating_num" property="v:average">9.2</span>, <span class="rating_num" property="v:average">9.1</span>]
9.7
9.6
9.5
9.5
9.4
9.4
9.5
9.4
9.4
9.5
9.4
9.4
9.3
9.2
9.3
9.3
9.2
9.3
9.6
9.2
9.4
9.3
9.3
9.2
9.1
其次,find方法可以获取第一个符合条件的标签,我们尝试着获取一下当前页面每个电影的名字,这比评分稍微难一点,图片和代码如下:
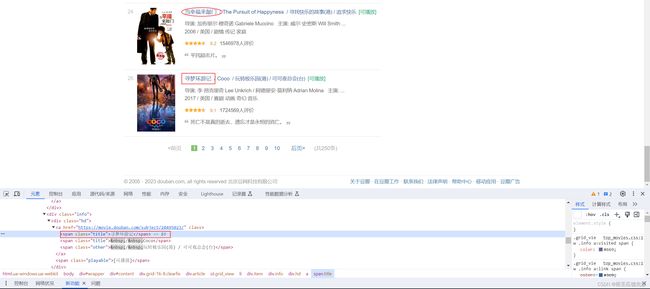
# 导入requests
import requests
# 从bs4这个库中导入BeautifulSoup这个类
from bs4 import BeautifulSoup
# 自行书写header请求头,对象格式为字典
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
# 获取响应体内容
content = requests.get("https://movie.douban.com/top250", headers=header).text
# BeautifulSoup是个构造函数,我们来创建BeautifulSoup的对象
soup = BeautifulSoup(content,"html.parser")
# 获取所有电影的名字
movie_div_list = soup.findAll("div", attrs={"class": "hd"})
for div in movie_div_list:
name = div.find("a").find("span").string
print(name)
-------------------------------------
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
这个杀手不太冷
千与千寻
美丽人生
星际穿越
盗梦空间
辛德勒的名单
楚门的世界
忠犬八公的故事
海上钢琴师
三傻大闹宝莱坞
放牛班的春天
机器人总动员
疯狂动物城
无间道
控方证人
大话西游之大圣娶亲
熔炉
教父
触不可及
当幸福来敲门
寻梦环游记
接下来,我们尝试着获取全部的Top250电影名,pycharm中代码如下:
# 导入requests
import requests
# 从bs4这个库中导入BeautifulSoup这个类
from bs4 import BeautifulSoup
# 自行书写header请求头,对象格式为字典
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
# 了解到豆瓣电影Top250网址的规律为:
# https://movie.douban.com/top250?start=0&filter=
# https://movie.douban.com/top250?start=25&filter=
# https://movie.douban.com/top250?start=50&filter=
# 创建一个装有25倍数的排行数字的数组
num_list = range(0, 250, 25)
# 循环每一个网页做爬虫
for num in num_list:
# 获取响应体内容
content = requests.get(f"https://movie.douban.com/top250?start={num}&filter=", headers=header).text
# BeautifulSoup是个构造函数,我们来创建BeautifulSoup的对象
soup = BeautifulSoup(content, "html.parser")
# 获取所有电影的名字
movie_name_list = soup.findAll("span", attrs={"class": "title"})
for span in movie_name_list:
name = span.string
if "/" not in name:
print(name)
-------------------------------------
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
这个杀手不太冷
千与千寻
美丽人生
星际穿越
盗梦空间
辛德勒的名单
楚门的世界
忠犬八公的故事
海上钢琴师
三傻大闹宝莱坞
放牛班的春天
机器人总动员
疯狂动物城
无间道
......(太多了不展示全部了)
我们还需要学习什么呢?
- 正则表达式:可以根据自己自定义的规则去爬取信息
- 多线程:让不同线程同时爬取多个页面,增加爬虫的效率
- 数据库:爬取的数据存储在数据库中
- 数据分析:爬取的数据拿来分析
- …