SpringBoot整合Freemarker导出word文档表格
目录
- 1、pom.xml
- 2、制作.ftl模板
-
- 2.1 创建word模板
- 2.2 另存为xml格式,进行简单处理
- 2.3 创建实体类
- 2.4处理xml文件
- 2.5修改后缀为ftl
- 3、导出word方法
-
- 3.1将demo.ftl放入resources/template
- 3.2通用的word导出方法
- 3.3执行导出方法
- 3.4测试效果
- 4、遇到的坑
1、pom.xml
在pom.xml文件中添加freemarker的依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
2、制作.ftl模板
2.1 创建word模板
创建word文档,制定表格。其中需要根据实际替换的元素用${...}书写。
主要包含几种情况:
1)正常需要替换的元素
2)“判断a”、“判断b”演示需要判断是否显示整行
3)“循环合并行”演示没有内容右边为空,有多条数据右边分行显示,左边自动合并。

2.2 另存为xml格式,进行简单处理
将word文档另存为xml格式。
1)首先找到之前写的替换元素,确保${…}和单词是连在一起的,如果不在一起,就把中间的删掉,处理到一起。

2)我习惯把xml文件按行给他格式化好

2.3 创建实体类
public class DemoWordDetail {
private String title;
private String type;
private String time;
private String aaa;
private int isShowA=1;//控制行显示
private String bbb;
private int isShowB=1;//控制行显示
private List<CyclicModel> cyclics;//合并数据
}
public class CyclicModel {
private String cyclic;
/**
* 合并标志;第一行"2.4处理xml文件
1)对于正常需要替换的元素可以不用做任何操作
2)“判断a”、“判断b”演示需要判断是否显示整行,定义字段isShowA、isShowB来控制
在行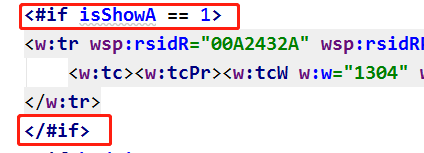
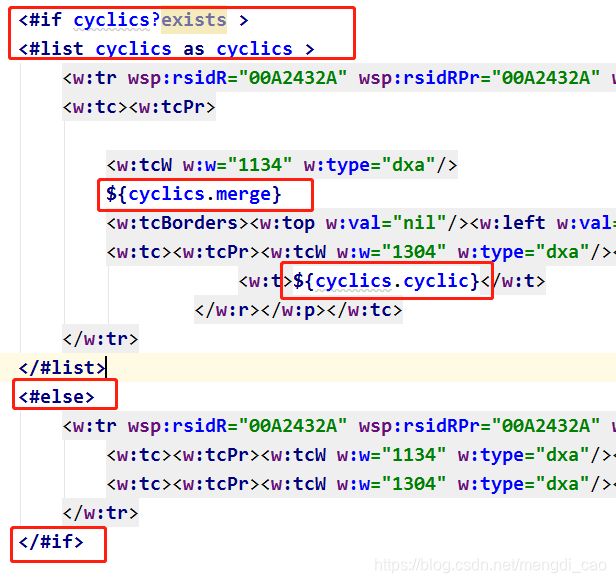
3)“循环合并行”处理
采用<#if>显示处理数据<#else>显示空白,把${...}删掉
加 ${cyclics.merge}处理第一列合并问题;
将之前的${cyclic}替换成${cyclics.cyclic}
2.5修改后缀为ftl
3、导出word方法
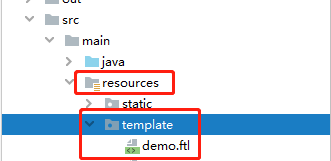
3.1将demo.ftl放入resources/template
3.2通用的word导出方法
@Service
public class WordService {
public void exportWord(HttpServletRequest request, HttpServletResponse response, String fileName , String templeteName, Object dataModel){
Configuration configuration=new Configuration();
configuration.setDefaultEncoding("utf-8");
configuration.setEncoding(Locale.getDefault(),"utf-8");
try {
configuration.setClassicCompatible(true);//处理dataModel中如果为null的情况
//既能保证本地运行找得到模板文件,又能保证jar包运行能找到得到模板文件
configuration.setClassForTemplateLoading(this.getClass(),"/template");
configuration.setTemplateLoader(new ClassTemplateLoader(this.getClass(),"/template"));
// configuration.setDirectoryForTemplateLoading(new File(CommonUtil.getTempletePath()+"/template/"));
Template t=configuration.getTemplate(templeteName,"utf-8");
response.setContentType("application/msword; charset=UTF-8");// application/x-download
response.setHeader("Content-Disposition", "attachment; "
+ encodeFileName(request, fileName+".doc"));
OutputStream outputStream = response.getOutputStream();
Writer out=new OutputStreamWriter(outputStream);
t.process(dataModel, out);
outputStream.close();
out.close();
} catch (IOException | TemplateException e) {
e.printStackTrace();
}
}
public static String encodeFileName(HttpServletRequest request, String fileName)
throws UnsupportedEncodingException
{
String new_filename = URLEncoder.encode(fileName, "UTF8").replaceAll("\\+", "%20");
String agent = request.getHeader("USER-AGENT").toLowerCase();
if (null != agent && -1 != agent.indexOf("msie"))
{
/**
* IE浏览器,只能采用URLEncoder编码
*/
return "filename=\"" + new_filename +"\"";
}else if (null != agent && -1 != agent.indexOf("applewebkit")){
/**
* Chrome浏览器,只能采用ISO编码的中文输出
*/
return "filename=\"" + new String(fileName.getBytes("UTF-8"),"ISO8859-1") +"\"";
} else if (null != agent && -1 != agent.indexOf("opera")){
/**
* Opera浏览器只可以使用filename*的中文输出
* RFC2231规定的标准
*/
return "filename*=" + new_filename ;
}else if (null != agent && -1 != agent.indexOf("safari")){
/**
* Safani浏览器,只能采用iso编码的中文输出
*/
return "filename=\"" + new String(fileName.getBytes("UTF-8"),"ISO8859-1") +"\"";
}else if (null != agent && -1 != agent.indexOf("firefox"))
{
/**
* Firfox浏览器,可以使用filename*的中文输出
* RFC2231规定的标准
*/
return "filename*=" + new_filename ;
} else
{
return "filename=\"" + new_filename +"\"";
}
}
}
3.3执行导出方法
DemoWordDetail demoWordDetail=new DemoWordDetail();
//一系列处理
wordService.exportWord(request, response, "title", "demo.ftl", demoWordDetail);
3.4测试效果
判断a、判断b均显示,循环合并行多条数据

判断a这行不显示,循环合并行无数据

4、遇到的坑
1)导出对象字段有为null时,报错,加上“configuration.setClassicCompatible(true);”
2)idea运行能正常导出,jar运行不能找到模板,代码中给出了解决
3)cmd运行jar,能正常导出word,但是打开错误。
经过测试发现导出word文档乱码,发现是是cmd默认编码问题,在cmd执行时加上:
start javaw -Dfile.encoding=utf-8 -jar xxx.jar