一次elasticsearch 查询瞬间超时案例分析
大家好,我是蓝胖子,有段时间没有做性能分析案例讲解了,正好前两天碰到一个性能问题,今天就来对它探讨探讨。
问题背景
在晚上9点左右,刚从外面逛街回到家,就接到了电话报警(幸好前不久刚好把电话报警机制加上,不然可能我就要去洗澡了),电话告警告知线上业务存在大量请求失败的情况。于是赶紧打开电脑,排查了起来。
错误日志我们都是直接打到了钉钉上,发现大量的报警都是elasticsearch 访问超时发生的。紧接着看了下线上业务网站是否正常,各项接口也是正常返回的,查看错误日志发现,错误仅仅是在那一瞬间出现。之后便正常了。下面是在kibana上的错误日志图表。
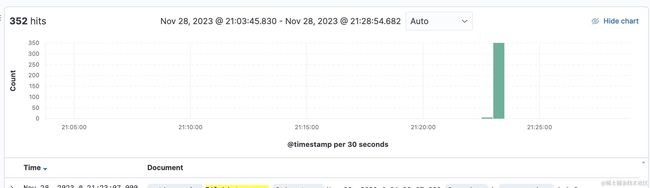
好在系统现在是正常的,我可以慢慢的排查为啥会出现大量超时的情况,下面是我的排查思路。
排查思路
在 服务监控实践那个专题里 我有提到 ,监控是分层的,分层的好处也容易定位问题出现的根本原因。一般把整个监控范围划分为机器监控,组件监控,应用监控,业务监控。由于目前线上主要是elasticsearch访问超时了,所以我首先查看了elasticsearch的组件的相关情况。
排查elasticsearch 组件
想到访问超时,会不会是由于elasticsearch集群在那段时间承载了过多的访问流量,如下图所示,是当时elasticsearch的访问情况。
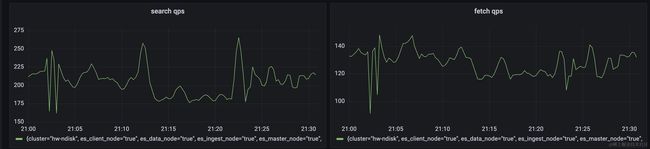
我们生产上是3台机器组成的集群,其余两台机器流量情况也和这个类似,可以看到整个集群的qps并不高,也就几百的样子。
既然不是流量问题,那会不会是es在执行一些耗时的操作,因为es中执行请求是在线程池中排队请求的,如果其中某些请求比较耗时会造成请求排队的情况。所以紧接着又看了es的线程池的情况。
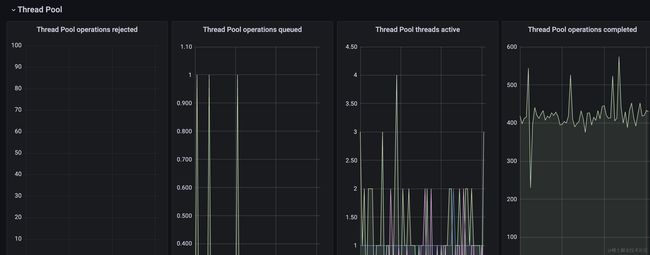
机器1
机器2
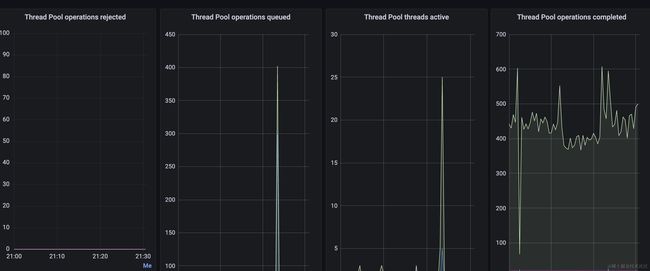
还有一台机器3的线程池线程池情况,不过它和机器1类似,我这里就不粘贴出来了,可以看到很明显的是机器2中有较多的排队请求,不过没有出现拒绝请求的情况,那应用服务的es客户端为啥会触发超时呢?这是因为我们部门使用es客户端的时候都会加上超时时间(出现超时的请求设置的3s超时),虽然es服务端没有拒绝请求,但是在3s内客户端把请求取消了。
不过看到这里,能够想到,机器2这台机器很大可能是在执行什么比较耗时的查询,导致发往它的请求都在排队了。
耗时的查询原因又可以分为以下两种情况,
1,es执行的查询语句的确足够慢,性能不佳。
2,是由于机器的原因导致es的查询慢,比如同一台机器上有其他磁盘吞吐比较大的服务在运行。
进程服务与机器监控
基于上述分析,我先看了出现问题的机器2上的进程服务读写磁盘的情况,发现对磁盘读写最频繁的仍然是es服务,所以应该是es的dsl语句导致的。
这里再插入一个当时观察到的异常监控指标,机器2上的tcp连接个数在异常时出现激增,并且出现了tcp over flow的错误。如下是机器2当时的tcp连接状态的监控。
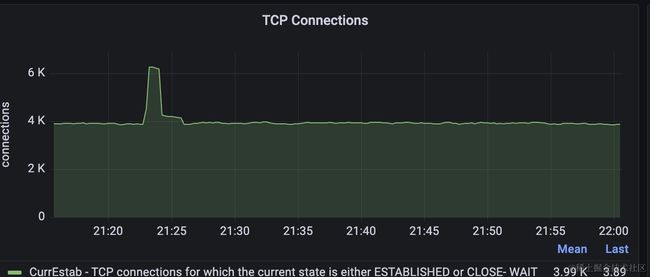
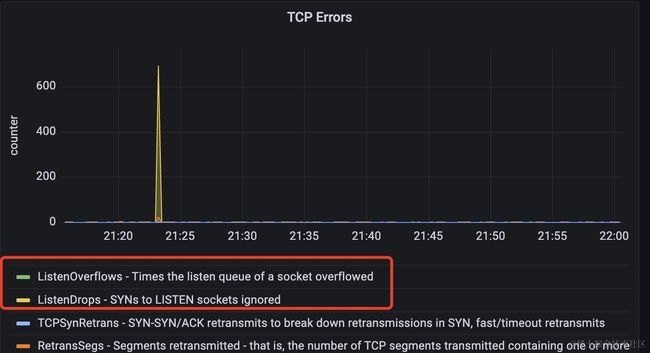
如果单看这两个指标,可能会认为是tcp的等待队列设置小了,但经过排查,等待队列的长度已经设置的足够大。结合前面对elasticsearch的监控,可以很好的解释这两个指标为啥出现。
原因在于elasticsearch此时执行语句比较慢,导致大量的连接没有被释放,而后续仍然会有新的请求过来,最终导致tcp连接异常了。
好了,基于上述分析,最后定位到了elasticsearch的慢查询导致的问题。
elasticsearch 慢查询日志排查
通过查看慢查询日志,发现当时的确有这样一个耗时16s的查询。是个数量达到上千的terms查询。该查询刚好是最近上线的一个定时任务在执行的语句。
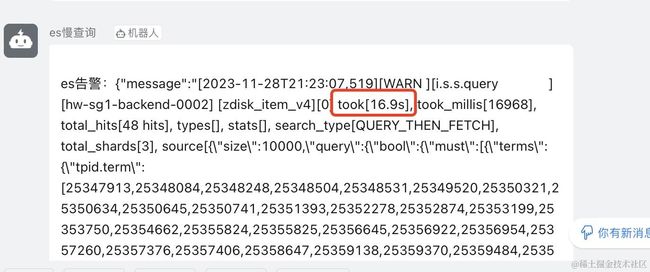
elasticsearch 对于单term的精准查询是很迅速的,但是对terms的查询性能会出现性能急剧下降的情况,multi terms查询会将每个term的倒排列表读取出来进行合并,这个合并过程是非常耗时的(可以通过profile dsl语句验证这一点),特别是查询的term值对应很多文档的时候,开销会更大。并且这条查询直接读取了10000条数据。分析下来,这个查询对cpu,磁盘,还是内存都具有很大压力。
解决办法
针对上述慢查询,由于是后台定时任务,对查询时间没有要求,最直接的优化方法 可以采用分批的方法,将上千terms的查询分成小批量的terms查询,比如100个terms,一批批的查询。同时采用scroll滚动查询的方式,每次只查询1000条数据出来,减小对内存的压力。
总结
其实,你可以看到,整个排查过程是比较顺畅的,但是要完成这一系列比较顺畅的排查动作前提是要有比较完善的监控机制。无论是对组件还是机器乃至应用服务的监控,我们都设有比较完善的监控图表用于保留问题现场。对于慢查询日志则是直接发往了钉钉群,这也有利于快速对慢查询进行发现和修改以及对慢查询进行检索。
有了这些监控机制,当问题发生时,只需要分层的去观察不同层的监控情况,问题便能迎刃而解了。对于如何落地一个能用于生产环境的监控机制,欢迎收看我直接的服务监控实践系列结合对公司监控系统的建设,我完整的介绍了如何构建一套比较完备的监控系统。