【词向量】从Word2Vec到Bert,聊聊词向量的前世今生(一)

机器学习算法与自然语言处理推荐
来源:https://zhuanlan.zhihu.com/p/58425003
作者:小川Ryan
【机器学习算法与自然语言处理导读】BERT并不是凭空而来,如何从word2vec给出一些思考,本文进行了介绍!
由于近日所做的工作与预训练模型联系比较紧密,却发现自己对几个词向量内部的细节有所遗忘了,因此打算写篇文章来拾起一些记忆,同时也方便以后供自己和他人查阅。
1. 语言模型
n-gram model
谈到词向量则必须要从语言模型讲起,传统的统计语言模型是对于给定长度为m的句子,计算其概率分布P(w1, w2, ..., wm),以表示该句子存在的可能性。该概率可由下列公式计算得到:
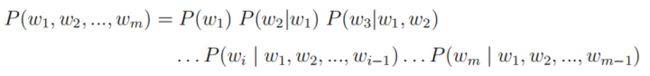
但实际过程中句子的长度稍长便会为估计带来很大难度,因此n-gram 模型对上述计算进行简化:假定第i个词的出现仅与其前n-1个词有关,即:

实际计算中,通常采用n元短语在语料中出现的频率来估计其概率:
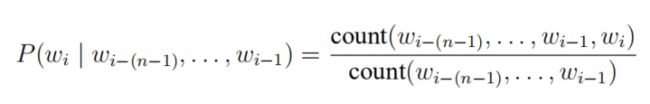
为保留句子原有的顺序信息,我们当然希望n越大越好,但实际上当n略大时,该n元短语在语料中出现的频率就会越低,用上式估计得到的概率就容易出现数据稀疏的问题。而神经网络语言模型的出现,有效地解决了这个问题。
Neural Network Language Model
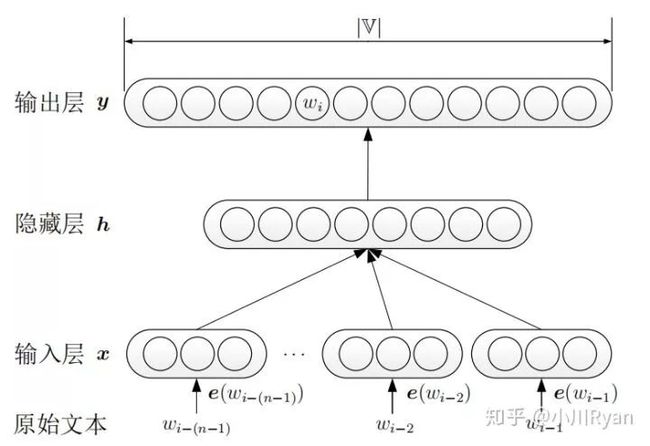
神经网络语言模型不使用频率来估计n元短语出现的概率,而是通过神经网络训练得到一个语言模型。
首先将原始文本进行one-hot编码,在分别乘以词嵌入矩阵,得到每个词的词向量表示,拼接起来作为输入层。输出层后加上softmax,将y转换为对应的概率值。模型采用随机梯度下降对
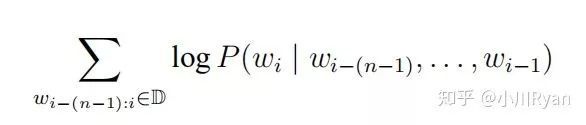
进行最大化。
循环神经网络语言模型(RNNLM)
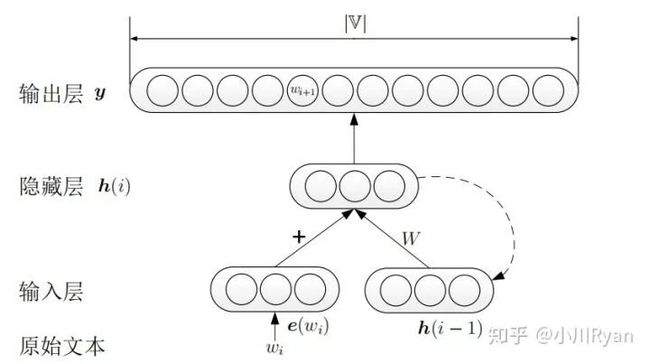
尽管NNLM采用神经网络对句子的可能性进行预测,但其依然是采用了n-gram对运算进行了简化,而RNNLM则直接对整个句子进行建模,即直接计算
RNNLM与NNLM的差别在于隐藏层的计算:
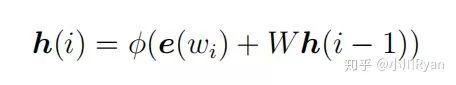
其每个隐藏层的结点同时依赖于当前词的词向量输入和上一个词的隐藏态输出,这样一来,模型便能用更完整的上文信息进行学习和预测。
上述的NNLM和RNNLM的目的都是为了建立语言模型,词向量(即输入层之前的词嵌入矩阵)只是整个过程的副产物,而从C&W开始,就直接以生成词向量为目标构建模型了。由于CBOW是在C&W基础上进行的升级和简化,所以我们直接从CBOW看起。
2. Word2Vec
CBOW
CBOW的主要思想是将一句话中的某个词挖去,用其上下文对其进行预测。我们先来看上下文(context)中只有一个词的简单情况(即用一个词来预测一个中心词):
输入层是上下文单词的one-hot编码,词典大小为V,第一个权重矩阵W为V行N列的词向量矩阵,N是词向量的维度,如常用的300维、400维等,暂且称W为"输入词向量",它的作用是把上下文单词的词向量表示出来,如
此处的隐藏层并不经过非线性激活,只是将上下文单词用W表示出来的词向量的各维线性地传到下一层;矩阵W' 是W转置后的结果,暂且称为"输出词向量",其作用是表示要预测的中心词的词向量;现在要做的就是计算词典中所有词的“得分”,选出最大概率的中心词作为预测结果。
论文中采用的方法是将上下文单词的词向量与中心词的词向量做点积来表示得分,即
而我们知道两个向量的做点积的结果是可以反映它们的相似度的,我认为这也是为什么将词向量用来做相似词检测效果很好的原因。将隐藏层 与 相乘,便能得到词典中所有的词与上下文的词的得分了,最后再在输出层计算softmax函数将分数归一化成概率:
使得概率最大的中心词就作为预测的结果。训练过程则采用反向传播和随机梯度下降,不断更新词向量矩阵,最后通常选用"输入词向量" 作为最后的结果。
我们再来看看上下文是多个词的CBOW
用上下文的C个词来预测中心词,与上下文只有一个词的不同之处在于隐藏层不再是取一个词的词向量的各维,而是上下文C个词的词向量各维的平均值,即:
其他的方面均没有太大差别,最小化损失函数
得到最优的词向量。
详细的训练步骤推导,可以参见论文 word2vec Parameter Learning Explained ,文中的推导十分详尽,甚至还在附录中带初学者回顾了一遍反向传播。毕竟走马观花的所学终究都只是空中楼阁,所以强烈建议认真阅读和体会一下论文中的推导过程。
Skip-gram
与CBOW恰好相反,Skip-gram的主要思想是选取一个句子中的某个单词(也称中心词),用其来预测上下文的其他单词。
输入层是中心词的one-hot编码,经过"输入词向量"得到其词向量表示,隐藏层为中心词词向量的各维:
Skip-gram的不同在于:输出层需要计算出C个分布(C为需要预测的上下文的词数),通过分别计算每一个分布中最大概率的词确定最有可能的C个词。C个分布共用同一个“输出词向量”,同样地计算每个分布中所有词的得分:
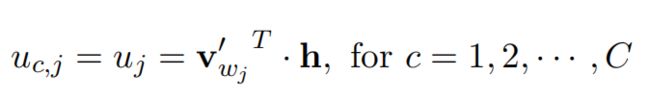
然后最小化损失函数
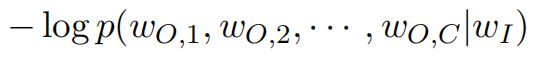
得到最优词向量。
3. 优化方法
上述未优化的CBOW和Skip-gram中,输出层后采用一般的softmax层,在预测每个词的概率时都要累加一次分母的归一化项,而指数计算的复杂度又比较高,因此一旦词典的规模比较大,预测的效率将会极其低下。在CBOW和Skip-gram中都有相应的优化方法以减小计算复杂度,我们来介绍其中的两种。
Hierarchical Softmax
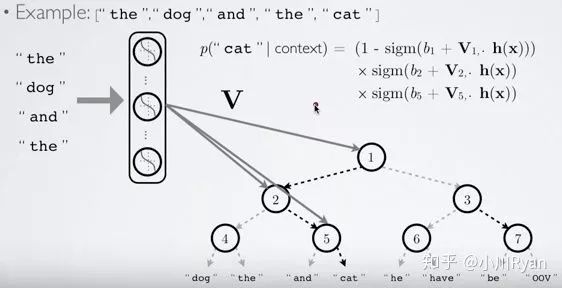
首先以词典中的每个词在语料中出现的次数(或频率)为权重,构建一棵哈夫曼树,叶子节点为词典中的每个词的one-hot表示,每个非叶子结点也表示为一个向量。此时,从根节点到每一个叶子节点的路径都可以由一串哈夫曼编码来表示,如假设向左结点为0,向右结点为1,上图中的“cat”就可以表示为01.
在预测过程中,每一个非叶子结点都用自身的向量表示来做一次二分类(如使用逻辑回归),分类的结果便导向其是去到左结点还是右结点,这样一来,预测为"cat"的概率就可表示为P(结点1==0)*P(结点5==1)了,更复杂的树结构也以此类推。此法在预测某一个特定的词的概率时就只需考虑从根节点到该叶子结点这几步了,使预测的效率大大提升。
再来看论文中的正式解释:



函数[[x]]定义为:
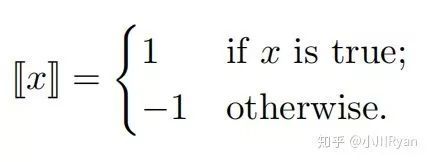
ch(n)表示结点n的左孩子结点,h为隐藏层的输出。定义内部节点向左的概率为
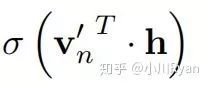
则向右的概率为
 那么图中预测为w2的概率为
那么图中预测为w2的概率为 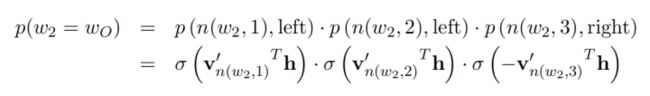
最小化损失函数
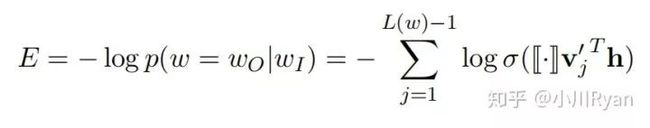
详细的公式推导可以参见博客:
https://blog.csdn.net/itplus/article/details/37969979
Negative Sampling(负采样)
负采样的目的依然是为改善在预测每一个词的概率时,普通softmax需要累加一次归一化项带来的高计算成本问题,其核心思想是将对每一个词概率的预测都转化为小规模的监督学习问题。具体地,对于语料中的某个句子,如“I want a glass of orange juice to go along with my cereal.”选取"orange"为上文,然后把预测为"juice"标记为1(即正样本),再选取句子中的k个其他词为负样本,假如k=4,就像这样:

再将采样到的这些样本用来训练一个逻辑回归模型。这样一来,在预测"orange"一词下文出现的词的概率时,尽管还是需要迭代比较多次来看哪个词的概率最大,但在每次迭代时,计算softmax时:
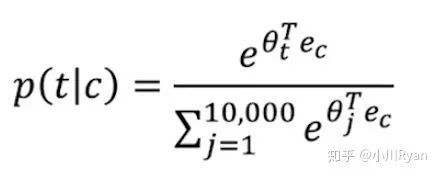
分母的归一化项就不用再像上式这样累加词典中所有的词,仅需要累加采样到的5个词就好了,同样大大地提高了训练效率。至于k的选取,Mikolov的论文中提及对于规模比较小的语料,k一般选在5到20之间,规模较大则控制在5以内。
关键是如何采样?
如果按照词频的观测分布采样的话,那每次都很可能采样到"a","the","of"等这种不具备太大实际意义的词,因此论文中提出subsample的思想:如果词w的频率高于某个阈值t,则以P(w)的概率在采样时跳过这个词:
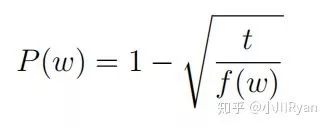
实际训练中还有一个小trick, 设f(wi)为词wi在词典中的观测概率,则以P(wi)的概率对wi进行采样:
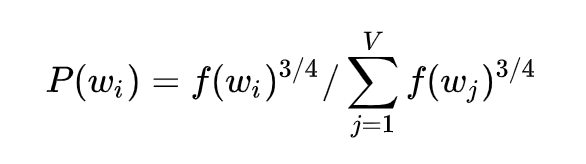
至于为何取这个值效果比较并没有相应的理论证明
关于负采样训练过程的详细推导参见博客:
https://blog.csdn.net/itplus/article/details/37998797
这个专题将分成三次发布,下一次会详细介绍Glove和Fasttext,再下一次介绍Elmo,GPT以及Bert.
敬请期待
参考文献
[1] Xin Rong, word2vec Parameter Learning Explained
[2] 来斯惟,基于神经网络的词和文档语义向量表示方法研究
[3] Tomas Mikolov,Distributed Representations of Words anand their Compositionality
[4]博客:Word2Vec中的数学原理
致转行AI的在校大学生的一封信
【AI自学】 完备的 AI 学习路线,最详细的资源整理!
转行AI需要看的一些文章
转行学AI,具体细分方向如何选,来自一线工程师的感悟
用法律武器,痛击腾讯侵权行为!!!湾区人工智能可以改善知识产权现状吗?
【送书PDF】Python编程从入门到实践
Python从入门到精通,深度学习与机器学习资料大礼包!
【免费】某机构最新3980元机器学习/大数据课程高速下载,限量200份

