JDK21+HADOOP3.2.2+Windows安装步骤
哈哈哈 最近转战大数据这块了,分享一下hadoop3.2.2的安装步骤
借鉴了不少大佬的文章,如有雷同,都是大佬们的
1.JDK安装
我选择的是JDK21 以下是下载网址和截图,这个没有太多的,一般下载最新的就可以
JDK: Java Downloads | Oracle
我安装的是windows下 x64install

下载到本地后,双击进行安装,并根据向导进行下一步
注意:文件安装路径一定要 没有空格!我第一次安装就是有空格,失败了好几次


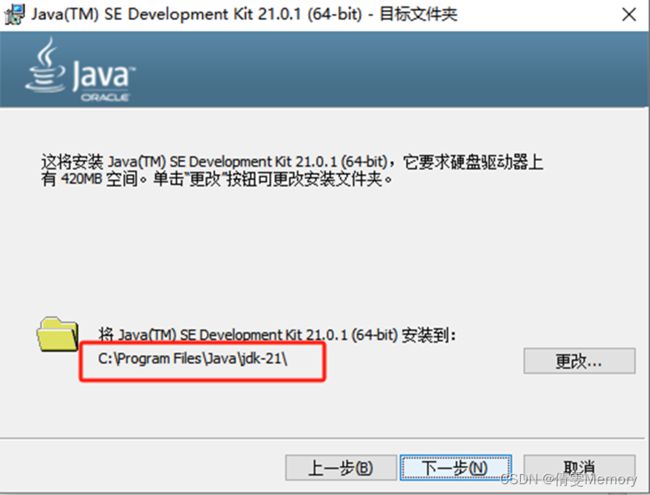
2.配置JDK的PATH文件
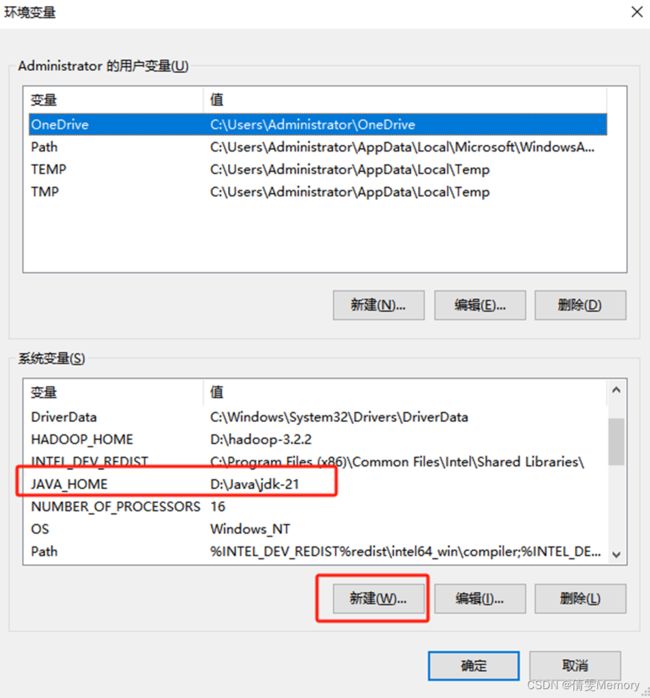
安装好后配置PATH文件
此电脑右键属性,找到“高级系统设置”- “环境变量”
新建“JAVA-HOME”和 JDK21的安装地址
双击Path 进入增加 JAVA-HOME的bin文件地址,注意:用英文;隔开


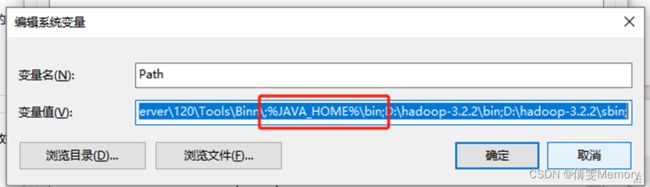
3.验证Java是否安装成功
搜索中输入CMD,找到命令提示符,双击运行
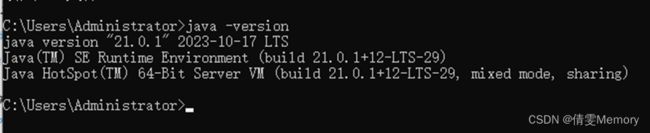
输入“java -version”,如果出现 java版本则安装成功
4.安装Hadoop
进入Hadoop官网
Hadoop: https://hadoop.apache.org/releases.html
因为需要在windows上运行,所以需要从Github下载
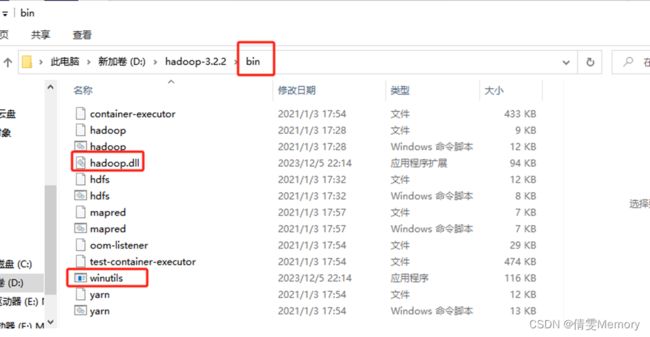
windows下使用hadoop需要的工具 winutils.exe 和 hadoop.dll
我下载的是3.2.2版本
这边找了CSDN上大佬分享的地址
安装包下载地址:3.2.2
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
下载windows下使用hadoop需要的工具winutils.exe和hadoop.dll:
https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.2/bin



双击安装包进行解压
如无法解压,“以管理员身份”运行解压即可,解压到想安装的位置
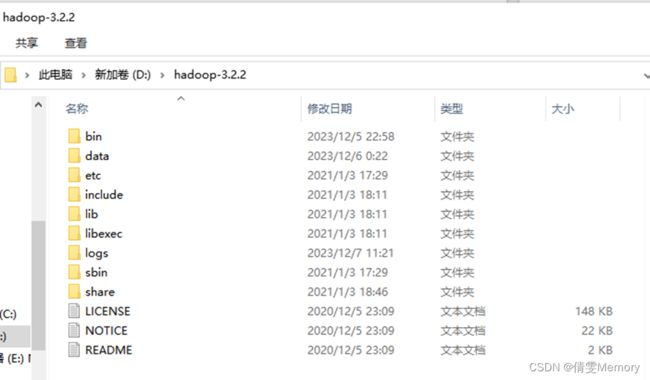
进入解压文件的bin文件,复制或替换windows下使用的两个文件
替换好后创建DATA文件夹和文件夹中多个子文件如图

5.更改hadoop下etc文件中的配置

修改core-site.xml(根据你的实际安装地址)
fs.default.name
hdfs://localhost:9000
hadoop.tmp.dir
/D:/hadoop-3.2.2/data/tmp
修改mapred-site.xml (根据你的实际安装地址)
mapreduce.framework.name
yarn
修改yarn-site.xml(根据你的实际安装地址)
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
修改hdfs-site.xml(根据你的实际安装地址)
dfs.replication
1
dfs.permissions
false
dfs.namenode.name.dir
/D:/hadoop-3.2.2/data/namenode
fs.checkpoint.dir
/D:/hadoop-3.2.2/data/snn
fs.checkpoint.edits.dir
/D:/hadoop-3.2.2/data/snn
dfs.datanode.data.dir
/D:/hadoop-3.2.2/data/datanode
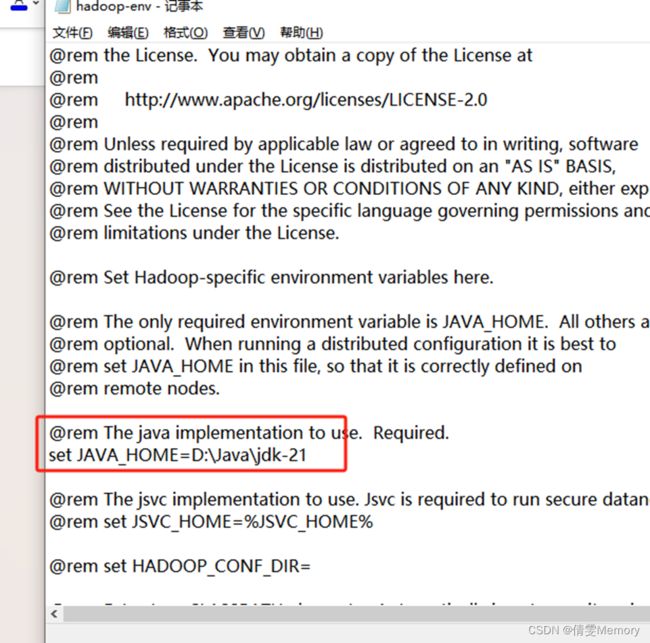
找到hadoop-env.cmd 配置JDK路径
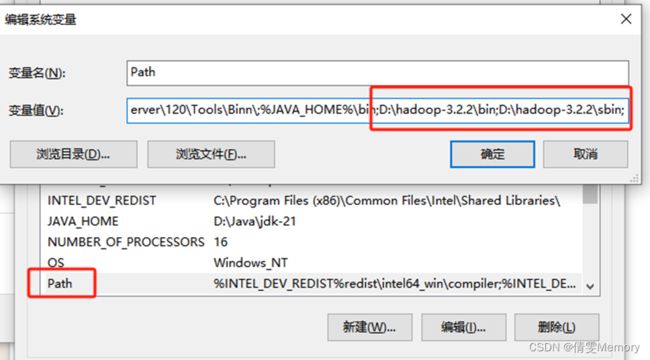
6.配置HADOOP的PATH文件
配置 PATH文件
新建HADOOP_HOME
在PATH中加入HADOOP地址,注意用英语字符;分隔

7.验证hadoop是否安装成功
验证是否安装成功
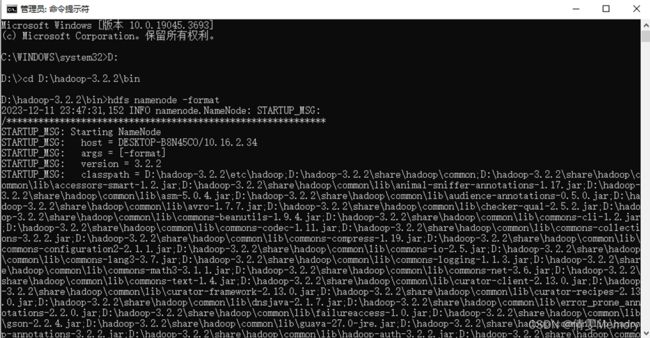
以管理员身份打开CMD “命令提示符”
进入bin文件目录

hdfs namenode -format 进入测试
通过CMD,cd 到 sbin 文件下 执行 start-all.cmd
会跳转
此时可以看到同时启动了如下4个服务: Hadoop Namenode Hadoop datanode YARN Resourc Manager YARN Node Manager

此时可以明确安装成功
8、HDFS应用
http://127.0.0.1:8088/ 即可查看集群所有节点状态
访问 http://localhost:9870/ 即可查看文件管理页面