Pyhon基于YOLOV实现的车辆品牌及型号检测项目源码+模型+项目文档
- 项目运行
- 运行录屏:
Pyhon基于YOLOV实现的车辆品牌及型号检测项目运行录屏
- 完整代码下载地址:Pyhon基于YOLOV实现的车辆品牌及型号检测项目
- 项目背景:
车辆检测及型号识别广泛应用于物业,交通等的管理场景中。通过在停车场出入口,路口,高速卡口等位置采集的图片数据,对车辆的数量型号等进行识别,可以以较高的效率对车型,数量信息等进行采集。通过采集的数据,在不同的场景中可以辅助不同的业务开展。如商场停车位的规划,路况规划,或者公安系统追踪肇事车辆等等。
- 项目要求:
- 使用slim框架来对图片进行分类识别。
- 掌握使用slim物体检测框架来进行物体的检测和识别。
- 传入一张图片实现上述两个功能,显示出最终的结果。
- 项目方案的分析与方案确定
- 项目提供的素材:
- 一个车辆分类的数据集。只是分类数据,内部没有定位信息。共48856张图片其43971张作为训练集,4885张作为验证集。数据已经预先打包成tfrecord格式,数据格式与课程中,分类模型使用的数据格式相同,打包关键代码参考"download_and_convert_flowers.py"。
数据集分类文件labels.txt
- 达到项目要求所缺少的因素
- 看不到具体的图片,图片已经打包成tfrecord格式,不知道是什么样的图片。
- 项目提供的素材,不包括检测的标签,也就是给定的素材不能完成检测网络的训练。
- 各种方案可行性对比和方案的确定
因此,经过讨论,我们的首要任务是将tfrecord数据复原出来,并且找到一种合适的方式能实现检测功能。
可能的方案有:
- 使用label-image 自己制作检测数据集,在原始图片上进行标注,然后就有了分类标签和检测标签,就可以训练一个端到端的模型。但是缺点是图片太多,而项目周期只有一个月,估计不可能完成。
- 使用一个现有的预训练的检测模型,例如YOLO、faster-rcnn、ssd_mobilenet_v1_coco等,他们已经实现了对一些物体的检测功能,其中还都包含小汽车,因此可以利用这种网络完成检测功能,把读取出来的图片一次输入网络中,生成检测的标定数据,然后重新打包tfrecord文件,最终可以训练出一个端到端的检测加分类模型。这样的可行性也比较高,而且感觉工作量不大,唯一一点是感觉代码难度稍微有点大(相比于下面一种方案),万一要是卡住在中间的环节有可能造成时间紧张。不过总体感觉依旧是个可行的方案。
- 像上一步一样,找一个现成的检测模型,把输入的图片进行检测,再把检测出来的结果输入到自己训练的分类网络中,就可以实现项目需求了,而且相比于其他方案难度最小,最有可能完成这项任务。但是问题是整个过程经过了两步执行操作,感觉没有一步执行完成效率高。
经过对比,我们最终选择了第三个方案。
- 方案的实施与计划
最终的方案流程如下:

图3-1 方案流程图
项目实施计划如下:
第一周:
- 数据探索,复原出原始图片内容,进行数据探索、并分析。
- 确定最终使用的检测模型 。
第二周:
- 测试检测模型的效果,编写调用接口。
- 使用Inception_v4进行分类训练,使之达到85%以上的Top5准确率。
第三周:
- 完成分类模型项目接口。
- 与检测模型的接口进行整合。
- 将功能整合进一个Web服务功能中。
第四周:
- 文档撰写与完善代码。
- 数据探索
- 复原原始图片
根据项目提示,图片打包过程参考flower的例子,经过研究源代码打包过程和解包过程,我们完成了图片的复原工作。将图片按照分类放进各自的文件夹中。
-
-
- 3-2 获取原始图片数据
-
- 如图3-2左侧是复原图片过程的输出,可以看到图片的尺寸都是4xx*320,三通道的jpg图片,图片的高都是一样的,宽度略有不同。这个输入到训练之前,会经过一些图片预处理操作。训练时会将图片统一尺寸,做一些裁剪、随机flip翻转、颜色扭曲等如图3-3。
-

- 3-3 图片预处理部分
- 最后复原出来的图片train集是43972个图片,764个文件夹对应labels.txt中764个分类,训练集的图片数比项目说明中的多了一个,我想可能是因为43971个图片分成4个数据集的取整问题,最后复原的时候可能多了一张重复的,这个没多大关系。
- 可以发现训练集中每种品类的汽车都有不同的视角、颜色、背景的图片,看来识别车型的影响因素还挺多的。但是数据的主体都拍照的比较清楚,处于画面正中位置,所以应该可以实现不同视角下汽车的分类功能。
- 发现的问题:训练集里面还是有一些错误的图片的,比如好几次把现代车放进其他车型的标签下的情况,而且是同一张图片放入多次,但是鉴于这样的错误比例不高,所以训练的时候暂时不做处理。先放进网络中训练试试。
- 选择Yolo作为检测网络
首先,Yolo是回归检测的开山之作,检测效果不错mAP~0.58,而且运行速度非常快能够达到45-150帧每秒。另外一个是因为我们团队的黎同学之前研究过这个模型,所以弄起来比较有把握。
- 在只有分类的数据集的情况下,我们不能直接使用YOLO模型去进行端到端的训练,因为我们人力有限,为了节约时间成本,我们在网上把开源的YOLO模型拿下来,调用YOLO模型在VOC训练集上训练所得到的预训练参数,写出一个检测程序。
然后我们测试了一下检测的能力:

图3-4 YOLO检测汽车测试

图3-5 YOLO检测更多辆汽车测试
可以看到,YOLO能够出色的完成多辆汽车检测的任务,框选出来的位置很准确。只是会把汽车分成truck、car、bus等分类,这个只需要后期做一下处理都当成汽车就行了。
- 使用Inception_v4进行分类网络的训练
下一步就是要进行分类网络的训练,项目要求使用Inception_v4模型。于是我们就读了一下Inception_v4的论文,然后研究了一下slim分类训练里面的代码。
- Inception_v4论文
论文中介绍了Inception_v4的网络结构还同时介绍了另外一种加了residual的Inception_v4的结构。 同时还把Inception_v3以及带residual的inception_v3做了对比,得出了一些结论:
Inception_v4在Inception_v3的网络结构上进行了一些结构上的微调,最终的实验结果是

图3-6 四种模型的训练结果
Inception_v4系列比Inception_v3系列相比,准确率方面是更优秀的,Top-5 error减少了1.多,另外加了residual的V3或者V4都比不加的模型训练更快的收敛,但是准确率方面倒没有什么更多的贡献。
- 训练Inception_v4,实现分类功能
训练的思路是,先从slim的github上下载预训练的模型
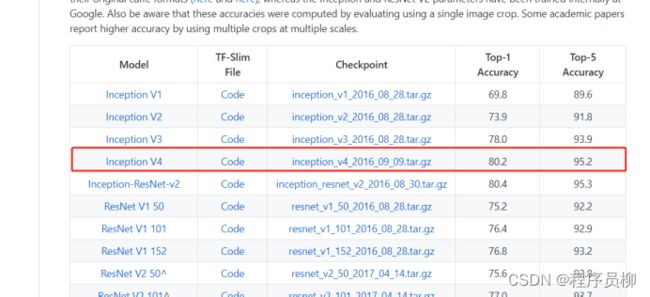
图3-7 Inception_v4
然后对这个模型进行Finetune。过程是这样的:

图3-8 Inception_v4进行finetune
这里指定了train_dir 和dataset_dir,model_name是incption_v4, checkpoint_path是我们下载的checkpoint。然后重要的一点是指定checkpoint_exclude_scopes参数,这里把InceptionV4/Logits,InceptionV4/AuxLogits这两个层排除了,这在slim中会判断没有这两层的话,会根据dataset.py中提供的_NUM_CLASSES参数,从新配置分类的层。而前面的层目前还是保持不变的。尤其注意的是,这里不需要额外指定trainable_scopes参数就行了,否则训练只会训练这里指定的层。我们这里需要将全部的层都参加训练。这样前面特征提取的层在训练中会进行微调,而后面的分类层会着重进行反向传播调整。

训练过程中打开tensorboard,查看过程如下:


可以看到total_loss稳步下降,最终稳定在1.多左右
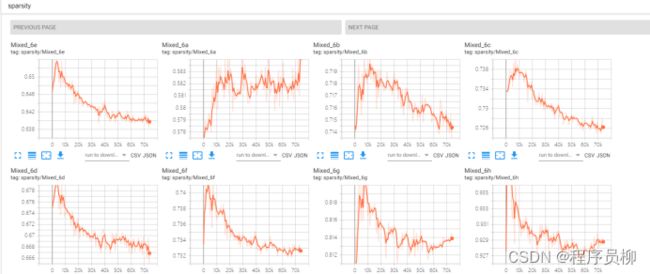
模型的稀疏度也一直在调整,下降,代表模型的拟合能力在提升。

学习率开始的时候设置的是0.001, 然后中间停止训练改成decay模式,继续训练,可以看到后面学习率在下降一段时间后,保持在我们设置的最小值上。最小值能防止模型失去反向传播的动量,而随着训练的进行减小学习率能够减小模型的震荡,让模型尽快调整到最优点。

Slim训练中有对数据进行预处理的功能,可以将图片进行裁切、反转等操作,增广训练数据,让模型的拟合能力更强。
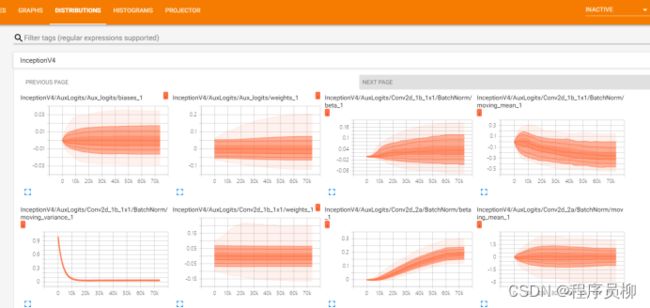
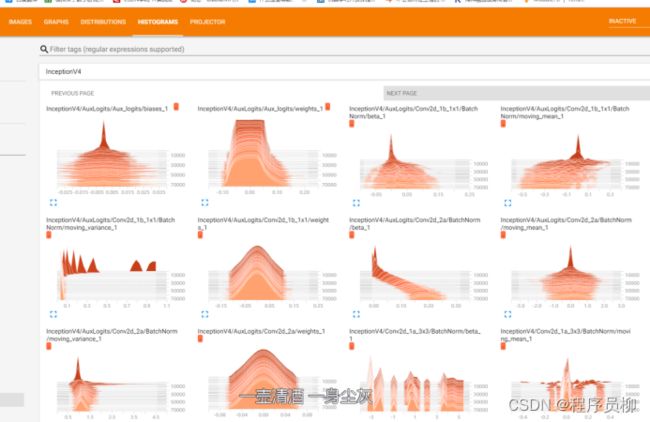
可以看到各个层的参数都在随着训练进行调整
训练的差不多了,进行一次验证:


验证集上准确率达到了88.7% ,top-5 达到了94.59%,达到了预定的要求。
- 代码整合
代码整合是把两个模型的检测程序连接起来,通过YOLO网络检测出Car,Bus,Truck类的坐标,然后根据坐标将原图裁剪,将裁剪后的数据送入inceptionV4分类网络中,得到类别,最后通过得到的类别,坐标信息在原图上标记并显示原图。
- 模型导出,与功能的对接
- 将检测出的标定框裁切(标定为Truck,Car,Bus 类别的)
- 将切出来的图片送入分类网络
- 在图片上标出目标以及分类结果
单个目标的识别结果很好
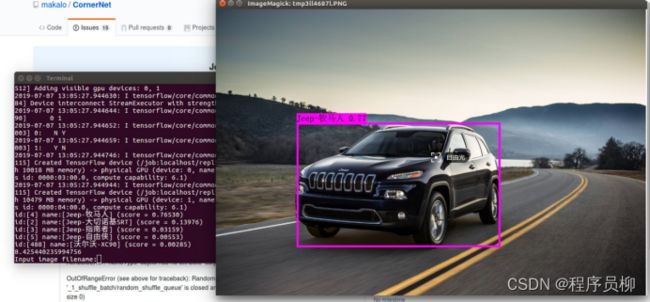
单个目标的结果1

单目标检测结果2
多个目标的情况会受图片质量,以及车辆遮挡的影响

多个目标的情况,前面的车结果正确,后面两个车明显不对

这种情况就更不行了
原因:
- 图片质量差,即使是人也看不准车型
- 车辆被遮挡,导致截图后送入分类网络中不同种车的特征混合到一起了
- 训练还不够,训练数据量少
- 遇到的问题与解决
- 读取tfrecord时,开始导出的图片是花的,后来发现是图片的col和row分别对应的是width,height,因此在生成图片的时候数据获取不对。这点修正以后就好了。

图4-1 图片的宽高对应col和row问题
- Inception_v4模型训练的时候,要指定checkpoint_exclude_scopes参数,把InceptionV4/Logits,InceptionV4/AuxLogits这两个层排除,这在slim中会判断没有这两层的话,会根据dataset.py中提供的_NUM_CLASSES参数,从新配置分类的层。而前面的层目前还是保持不变的。尤其注意的是,这里不需要额外指定trainable_scopes参数就行了,否则训练只会训练这里指定的层。开始的时候,我指定了:
trainable_scopes=InceptionV4/Logits,InceptionV4/AuxLogits
这样,模型训练的时候,将只训练最后这分类的两层。导致我们出现了如下问题:
在6-8小时训练过后也没有在验证集上达到top1 80% 准确率;

训练了53万步依然在4和5之间摇摆

Tensorboard上相关数据:
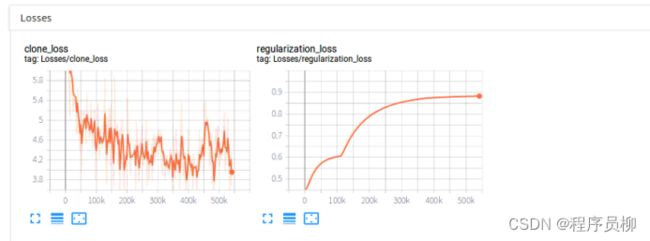
可以看到我们的正则项损失趋向平缓,说明模型参数好像没有继续拟合了。

学习率在finetune的过程中我修改过几次,好像对模型影响效果不明显。
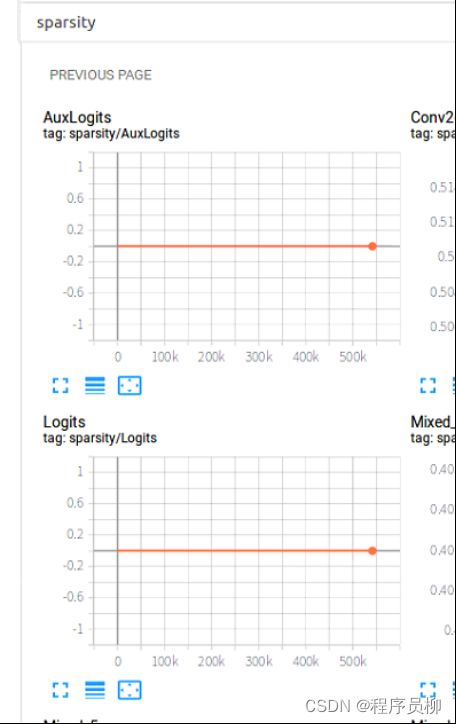
在tensorboard中这两个参数一直没有改变,看demo的话好像是把这两个节点是给排除的。
经过分析之后,感觉是训练出现了问题,于是寻找答案,发现slim上给出的finetune模式是这样的:
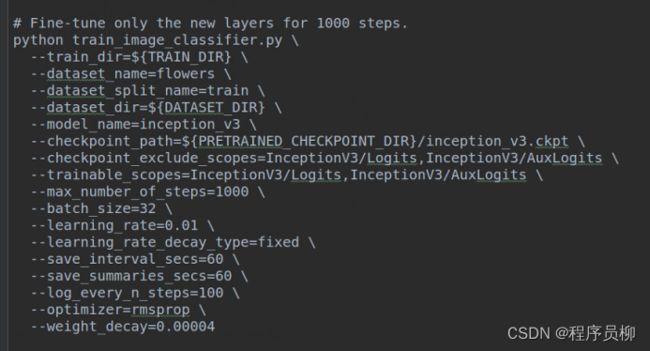

即第一步是只训练线性分类那两层,第二步是把所有参数一起训练,即就是修改这API中这两个参数。 我这里最终是在之前自己训练的基础上,继续把所有参数加入进去进行了训练,得到了上一节中达到的效果。
- 关于识别到车辆信息后,将识别到的汽车数据截取出来送进分类网络进行识别。有时会出现汽车的位置重叠,或者同一辆车得到了两个检测识别框。有两种方案:
- 直接选择置信度最高的框显示和识别。
- 通过IOU计算,将不同重叠情况的框进行合并处理
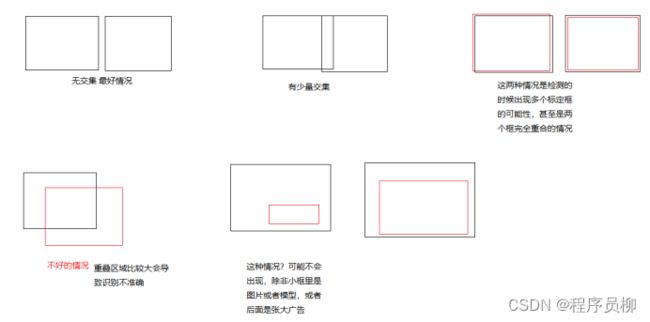
合并处理方案
- 还可以改进的地方
- 训练集中有许多错误的图片,应该进行数据筛选,提升识别的准确率。条件允许的情况下,增加训练集,进行更多的训练。
- 优化模型运行速度,将参数提取读取出来,在传入图片之后,直接进入计算步骤。现在车辆识别的步骤是经过多个session的,可以通过合并成一个session来增加程序运行的速度。
- 还想尝试同时分类和检测数据集一起训练的模式,不知道结果会怎样。
- 猜想:能不能把两个网络连接成一个网络,两个网络中应该有一些参数可以是共享的,有没有可能把这些参数实现共享。实现共享后可以减少重复参数,增加网络检测速度。
- 批量识别的功能可以通过添加batch实现一次检测多幅图片。
- 也可以增加视频检测功能。
完整代码下载地址:Pyhon基于YOLOV实现的车辆品牌及型号检测项目