MySQL数据库 设计用户表
需求
做一个展示用户信息的页面,有一个users表,里面该有的信息都有。
性能要求
- 数据量30亿。
- 页面必选条件:性别(男/女), 昵称前缀, 年龄。查询条件一定会带上这三个条件。
- 每页展现10条记录。
- 大翻页需求,如查第80w页。
- 尽可能的高性能
- 按注册时间倒序展现
设计思路
没有标准答案,可以考虑各种方案,大家一起来讨论好的解决方案~
分表方式
怎么分表呢?
用出生时间分表
每1年建一个表。
查年龄的时候,如,查2岁的。今天是2019-11-08,就要查出生日期在 2016-11-08 ~ 2017-11-08 的数据。
按年建表的话就要查2个表T_2016 和T_2017
查完需要在应用层做merge。(这个操作会比较麻烦,如查第80页数据(800w-800w+10),需要按相同的查询条件在两个表都拿10w条数据出来做merge,看到底merge完之后哪些才是800w ~ 800w+10的数据)
是否能每两年建一个表(T_2016_2017, T2017_2018)呢?这样就可以避免merge查询。不过会有双写和重复问题。也算是一个解决方案?
联合所有条件分表
性别+昵称前缀+出生年份
如: hash(“男_陈_2016_2017”)
输入条件: 男 陈 2岁, 直接能定位到这个表
这个单表里面包含的数据: 所有男性,陈开头,2岁的数据。
单表建联合索引(注册时间,昵称)【为了保证注册时间有序】
大分页的时候:
用户输入 男 陈 2岁 limit 800w, 10
下午做个实验试试!
做个实验
设计数据表
create table t_male_chen_9899 (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(20) NOT NULL COMMENT 'name',
`birthday` varchar(8) NOT NULL COMMENT 'birthday',
`register_time` int(11) NOT NULL COMMENT 'register_time',
PRIMARY KEY(`id`),
INDEX `registertime_name_idx` (`register_time`, `name`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT="test_male_chen_9899";
批量插入数据
import random
def randstr(num=None):
# 猜猜变量名为啥叫 H
H = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'
salt = ''
if num is None:
num = random.randint(1, 9)
for i in range(num):
salt += random.choice(H)
return salt
def randtime():
# 06-17年
return random.randint(1136044800, 1514736000)
def randbirth():
# 1998-2000年
randint = random.randint(883584000, 946656000)
date_touple = time.localtime(randint)
return time.strftime("%Y%m%d", date_touple)
db = Mysql(config.DB_CONF['host'],
int(config.DB_CONF['port']),
config.DB_CONF['user'],
config.DB_CONF['pswd'],
config.DB_CONF['db'], debug=0)
tb_name = 't_male_chen_9899'
start = datetime.datetime.now()
print 'start', start
MAX_LINE = 10000000
for i in range(MAX_LINE):
data = {
"name": "陈" + randstr(),
"register_time": randtime(),
"birthday": randbirth()
}
ret = db.insert(tb_name, data)
if i % 10000 == 0:
print i, float(i) / MAX_LINE * 100, "%", json.dumps(data)
end = datetime.datetime.now()
print 'end', end
timepass = end - start
print 'timepass', timepass, timepass.seconds
按照需求,查询数据:
explain select * from t_male_chen_9899 where birthday between "19981108" and "19991108" and name like "陈%" order by register_time desc limit 100000, 10;
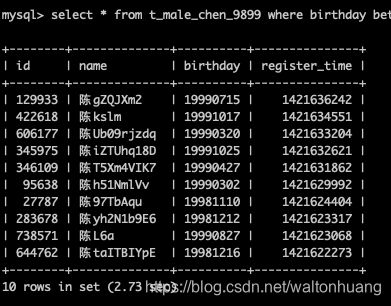

没有用到索引,2.73s,还是会慢。。
这是因为昵称的前缀索引 和 birthday的范围索引 没法一起工作。
小总结
综上所述,我是真的想不到完美的解决方案了
除非砍掉部分需求,比如年龄的定义放宽一些,不要精确到日,或者不实现大分页之类的。
不过积极的思考还是好事。
参考:解决大分页问题
参考:https://cloud.tencent.com/developer/article/1441929
https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/
先根据覆盖索引查到所需数据的id
另外的一些想法
如果能按年龄分表就好了。
但是建好表之后每天都会有数据迁移。
比如说:
20191108 0点。 2岁的表应该是 20161108 - 20171108
到了20191109 0点。 2岁的表就应该是20161109 - 2017119。涉及每个表都会删除一天的数据而且增加一天的数据。比较恶心。
求助
求大佬们批评指正
最后做一个实验吧
覆盖索引
基于上面的那个表和数据
当我们不考虑birthday的时候
索引是 注册时间和昵称
能否高效地大分页?
查询:
explain select id,name,register_time from t_male_chen_9899 where name like "陈%" order by register_time desc limit 100000, 10;
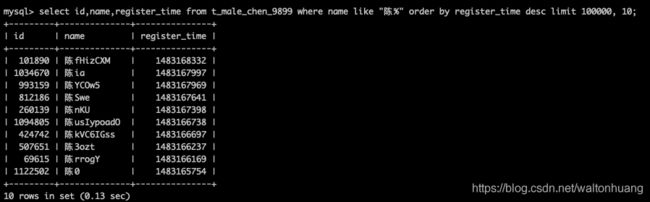
0.13s 速度还行

也能用上索引了