Kafka内容分享(四):Kafka 架构和幂等性与事务
目录
一、架构
1.1、Kafka重要概念
1.1.1、broker
1.1.2、zookeeper
1.1.3、producer(生产者)
1.1.4、consumer(消费者)
1.1.5、consumer group(消费者组)
1.1.6、分区(Partitions)
1.1.7、副本(Replicas)
1.1.8、主题(Topic)
1.1.9、偏移量(offset)
1.2、消费者组
二、Kafka生产者幂等性与事务
2.1、幂等性
2.1.1、简介
2.1.2、Kafka生产者幂等性
2.1.3、配置幂等性
2.1.4、幂等性原理
2.2、Kafka事务
2.2.1、简介
2.2.2、事务操作API
2.3、【理解】Kafka事务编程
2.3.1、事务相关属性配置
2.3.1.1、生产者
2.3.1.2、消费者
2.3.2、Kafka事务编程
2.3.2.1、需求
2.3.2.2、启动生产者控制台程序模拟数据
2.3.2.3、编写创建消费者代码
2.3.2.4、编写创建生产者代码
2.3.2.5、编写代码消费并生产数据
2.3.2.6、测试
2.3.2.7、模拟异常测试事务
一、架构
1.1、Kafka重要概念
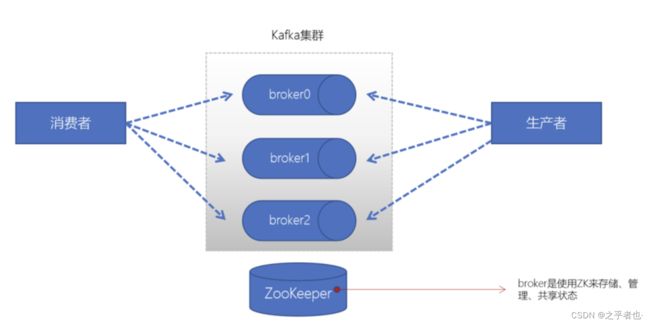
1.1.1、broker
- Kafka服务器进程,生产者、消费者都要连接broker
- 一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错
- broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
- 一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
1.1.2、zookeeper
- ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
- ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
注意:Kafka正在逐步想办法将ZooKeeper剥离,维护两套集群成本较高,社区提出KIP-500就是要替换掉ZooKeeper的依赖。“Kafka on Kafka”——Kafka自己来管理自己的元数据
1.1.3、producer(生产者)
- 生产者负责将数据推送给broker的topic
1.1.4、consumer(消费者)
- 消费者负责从broker的topic中拉取数据,并自己进行处理
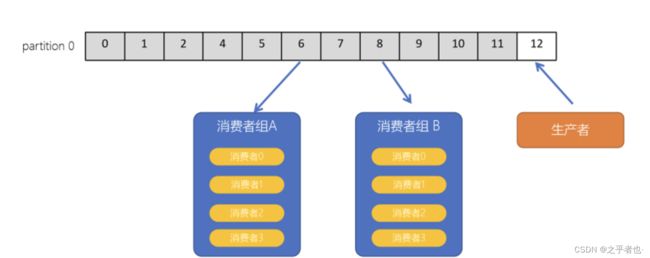
1.1.5、consumer group(消费者组)
- consumer group是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id),配置group.id一样的消费者是属于同一个组中
- 组内的消费者一起消费主题的所有分区数据
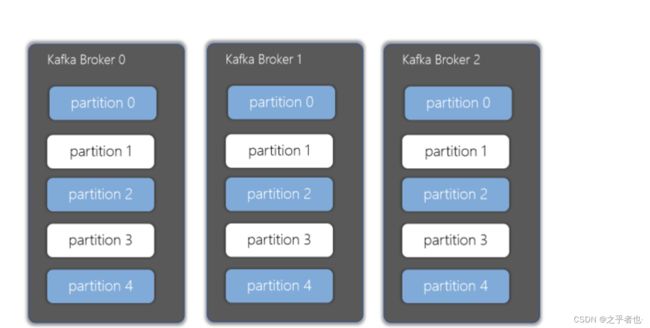
1.1.6、分区(Partitions)
- 在Kafka集群中,主题被分为多个分区
- Kafka集群的分布式就是由分区来实现的。一个topic中的消息可以分布在topic中的不同partition中
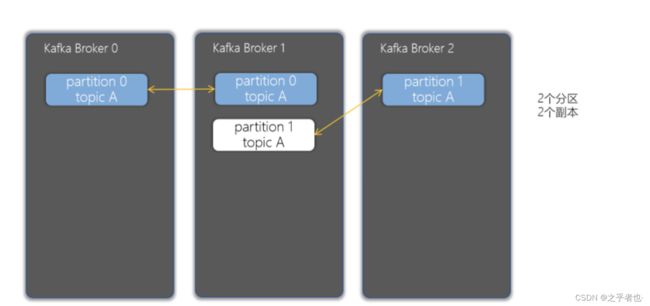
1.1.7、副本(Replicas)
- 实现Kafkaf集群的容错,实现partition的容错。一个topic至少应该包含大于1个的副本
- 副本可以确保某个服务器出现故障时,确保数据依然可用
- 在Kafka中,一般都会设计副本的个数>1
1.1.8、主题(Topic)
- 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
- 一个Kafka集群中,可以包含多个topic。一个topic可以包含多个分区
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
- 在主题中的消息是有结构的,一般一个主题包含某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
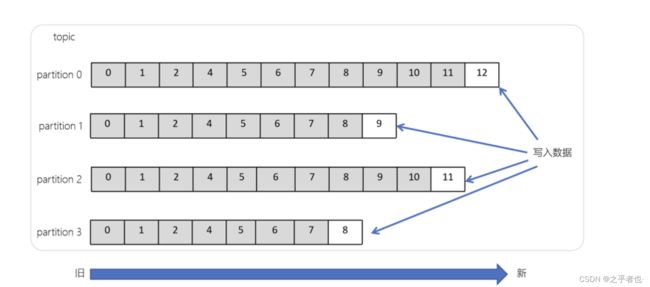
1.1.9、偏移量(offset)
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
- 相对消费者、partition来说,可以通过offset来拉取数据
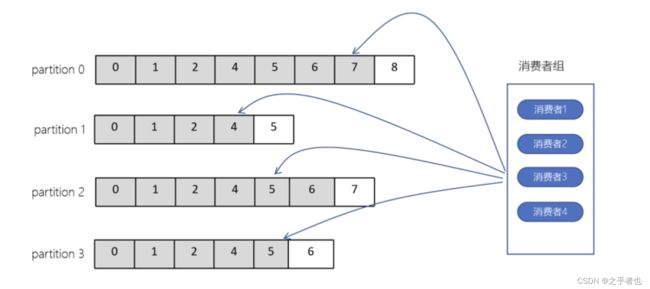
1.2、消费者组
- 一个消费者组中可以包含多个消费者,共同来消费topic中的数据
- 一个topic中如果只有一个分区,那么这个分区只能被某个组中的一个消费者消费
- 有多少个分区,那么就可以被同一个组内的多少个消费者消费
二、Kafka生产者幂等性与事务
2.1、幂等性
2.1.1、简介
拿http举例来说,一次或多次请求,得到地响应是一致的(网络超时等问题除外),换句话说,就是执行多次操作与执行一次操作的影响是一样的。
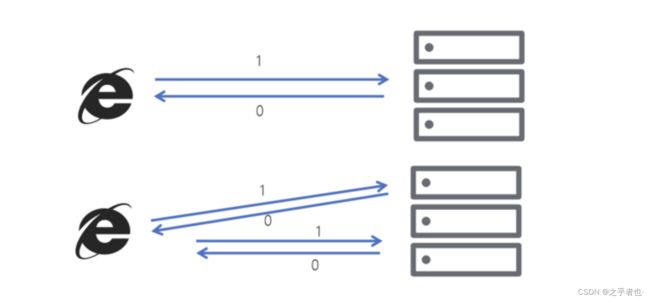
如果,某个系统是不具备幂等性的,如果用户重复提交了某个表格,就可能会造成不良影响。例如:用户在浏览器上点击了多次提交订单按钮,会在后台生成多个一模一样的订单。
2.1.2、Kafka生产者幂等性
在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,就有可能会在partition中保存多条一模一样的消息。
- 生产者消息重复问题
- Kafka生产者生产消息到partition,如果直接发送消息,kafka会将消息保存到分区中,但Kafka会返回一个ack给生产者,表示当前操作是否成功,是否已经保存了这条消息。如果ack响应的过程失败了,此时生产者会重试,继续发送没有发送成功的消息,Kafka又会保存一条一模一样的消息

2.1.3、配置幂等性
props.put("enable.idempotence",true);
2.1.4、幂等性原理
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
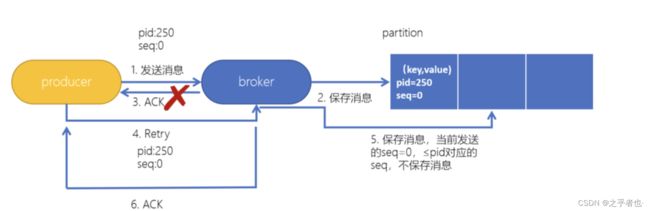
- 在Kafka中可以开启幂等性
- 当Kafka的生产者生产消息时,会增加一个pid(生产者的唯一编号)和sequence number(针对消息的一个递增序列)
- 发送消息,会连着pid和sequence number一块发送
- kafka接收到消息,会将消息和pid、sequence number一并保存下来
- 如果ack响应失败,生产者重试,再次发送消息时,Kafka会根据pid、sequence number是否需要再保存一条消息
- 判断条件:生产者发送过来的sequence number 是否小于等于 partition中消息对应的sequence
2.2、Kafka事务
2.2.1、简介
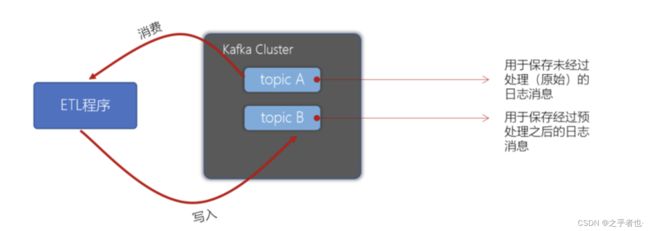
Kafka事务是2017年Kafka 0.11.0.0引入的新特性。类似于数据库的事务。Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。(consumer-transform-producer模式)
2.2.2、事务操作API
Producer接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作
- beginTransaction(开始事务):启动一个Kafka事务
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交
- commitTransaction(提交事务):提交事务
- abortTransaction(放弃事务):取消事务
2.3、【理解】Kafka事务编程
2.3.1、事务相关属性配置
2.3.1.1、生产者
// 配置事务的id,开启了事务会默认开启幂等性
props.put("transactional.id", "first-transactional");
-
生产者
- 初始化事务
- 开启事务
- 需要使用producer来将消费者的offset提交到事务中
- 提交事务
- 如果出现异常回滚事务
如果使用了事务,不要使用异步发送
2.3.1.2、消费者
// 1. 消费者需要设置隔离级别
props.put("isolation.level","read_committed");
// 2. 关闭自动提交
props.put("enable.auto.commit", "false");
2.3.2、Kafka事务编程
2.3.2.1、需求
在Kafka的topic 「ods_user」中有一些用户数据,数据格式如下:
姓名,性别,出生日期
张三,1,1980-10-09
李四,0,1985-11-01
我们需要编写程序,将用户的性别转换为男、女(1-男,0-女),转换后将数据写入到topic 「dwd_user」中。要求使用事务保障,要么消费了数据同时写入数据到 topic,提交offset。要么全部失败。
2.3.2.2、启动生产者控制台程序模拟数据
# 创建名为ods_user和dwd_user的主题
bin/kafka-topics.sh --create --bootstrap-server node1.angyan.cn:9092 --topic ods_user
bin/kafka-topics.sh --create --bootstrap-server node1.angyan.cn:9092 --topic dwd_user
# 生产数据到 ods_user
bin/kafka-console-producer.sh --broker-list node1.angyan.cn:9092 --topic ods_user
# 从dwd_user消费数据
bin/kafka-console-consumer.sh --bootstrap-server node1.angyan.cn:9092 --topic dwd_user --from-beginning --isolation-level read_committed
2.3.2.3、编写创建消费者代码
编写一个方法 createConsumer,该方法中返回一个消费者,订阅「ods_user」主题。注意:需要配置事务隔离级别、关闭自动提交。
实现步骤:
创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1.angyan.cn:9092");
props.setProperty("group.id", "ods_user");
props.put("isolation.level","read_committed");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
创建消费者,并订阅 ods_user 主题
// 1. 创建消费者
public static Consumer createConsumer() {
// 1. 创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1.angyan.cn:9092");
props.setProperty("group.id", "ods_user");
props.put("isolation.level","read_committed");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2. 创建Kafka消费者
KafkaConsumer consumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
consumer.subscribe(Arrays.asList("ods_user"));
return consumer;
}
2.3.2.4、编写创建生产者代码
编写一个方法 createProducer,返回一个生产者对象。注意:需要配置事务的id,开启了事务会默认开启幂等性。
创建生产者配置
Properties props = new Properties();
props.put("bootstrap.servers", "node1.angyan.cn:9092");
props.put("transactional.id", "dwd_user");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
创建生产者对象
public static Producer createProduceer() {
// 1. 创建生产者配置
Properties props = new Properties();
props.put("bootstrap.servers", "node1.angyan.cn:9092");
props.put("transactional.id", "dwd_user");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建生产者
Producer producer = new KafkaProducer<>(props);
return producer;
}
2.3.2.5、编写代码消费并生产数据
实现步骤:
- 调用之前实现的方法,创建消费者、生产者对象
- 生产者调用initTransactions初始化事务
- 编写一个while死循环,在while循环中不断拉取数据,进行处理后,再写入到指定的topic
(1) 生产者开启事务
(2) 消费者拉取消息
(3) 遍历拉取到的消息,并进行预处理(将1转换为男,0转换为女)
(4) 生产消息到dwd_user topic中
(5) 提交偏移量到事务中
(6) 提交事务
(7) 捕获异常,如果出现异常,则取消事务
public static void main(String[] args) {
Consumer consumer = createConsumer();
Producer producer = createProducer();
// 初始化事务
producer.initTransactions();
while(true) {
try {
// 1. 开启事务
producer.beginTransaction();
// 2. 定义Map结构,用于保存分区对应的offset
Map offsetCommits = new HashMap<>();
// 2. 拉取消息
ConsumerRecords records = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord record : records) {
// 3. 保存偏移量
offsetCommits.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset() + 1));
// 4. 进行转换处理
String[] fields = record.value().split(",");
fields[1] = fields[1].equalsIgnoreCase("1") ? "男":"女";
String message = fields[0] + "," + fields[1] + "," + fields[2];
// 5. 生产消息到dwd_user
producer.send(new ProducerRecord<>("dwd_user", message));
}
// 6. 提交偏移量到事务
producer.sendOffsetsToTransaction(offsetCommits, "ods_user");
// 7. 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 8. 放弃事务
producer.abortTransaction();
}
}
}
2.3.2.6、测试
2.3.2.7、模拟异常测试事务
// 3. 保存偏移量
offsetCommits.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset() + 1));
// 4. 进行转换处理
String[] fields = record.value().split(",");
fields[1] = fields[1].equalsIgnoreCase("1") ? "男":"女";
String message = fields[0] + "," + fields[1] + "," + fields[2];
// 模拟异常
int i = 1/0;
// 5. 生产消息到dwd_user
producer.send(new ProducerRecord<>("dwd_user", message));
启动程序一次,抛出异常。
再启动程序一次,还是抛出异常。
直到我们处理该异常为止。
我们发现,可以消费到消息,但如果中间出现异常的话,offset是不会被提交的,除非消费、生产消息都成功,才会提交事务。