C++核心编程思路(1):①程序的内存模型②引用的作用
文章目录
- 前言
- 一、不同的存储类型变量,会被存储在什么区?
-
- ①const修饰的局部变量放在栈区,全局变量放在只读数据区。
- ②static修饰的全局和局部变量都放在静态区(即数据区中的一个小区)
- 二、栈区
-
- 1.如果在函数A中定义了一个局部变量,那么在主函数里面是无法用取址符&去获取该局部变量的地址的。
- 2.return可以返回局部变量的值,但是不能返回局部变量的地址。
- 三、堆区:用new开辟内存空间,用delete销毁内存空间
-
- ①在C语言中,可以使用 malloc 函数来动态分配内存空间,并使用 free 函数来释放已分配的内存空间。
- ②在C++中,可以使用 new 运算符来动态分配内存空间,并使用 delete 运算符来释放已分配的内存空间。
- ③用new创建的堆区,返回的是这个堆区的地址,所以需要用一个指针去接收。
- ④new运算符的用法:
- 三、c++中的引用是干嘛的?
-
- ①引用就是给一个变量起一个别名(小名),但是这两个名字代表的是同一块内存空间。
- ②那变量和其别名的地址一样吗?
-
- 答:变量和其别名的地址是相同的。因为引用是变量的别名,它们共享相同的内存地址。在使用引用时,对引用的操作实际上就是对原始变量的操作。
- ③变量别名有啥用呢?就光是给变量起个小名吗?
-
- 答:主要有三个作用:
- 1.引用可以用作变量的别名,允许使用不同的名称访问同一个变量。
- 2.作为函数参数:引用可以作为函数的参数,允许在函数内部直接修改传递给函数的变量的值,这样可以避免复制大型对象的开销。(就是类似地址传递)
-
- 那既然地址传递和引用别名传递都能切实的改变实参,那为什么要创造引用别名这一传递方式呢?地址传递不是也可以避免复制对象的开销吗?
- 3.作为函数返回类型:函数的返回值被允许引用别名来代替。这样可以避免对象的复制开销,并且允许对返回的对象进行修改。
-
- ①引用作为函数返回值时,不能返回函数中的局部变量。
- ②函数的引用可以作为左值(即在等号左边)
- 四、引用的本质到底是什么?——指针常量
-
- 引用的本质是一个指针常量,它在创建时被初始化为指向某个对象的地址,并且在其生命周期内不能被修改指向其他对象的地址
- 五、函数参数传递时,用const修饰引用的参数别名。
-
- const常量引用的用处:在函数参数中传递对象,以避免对象(在函数内部)被修改。
-
- 常量引用在函数参数中的应用非常常见,它可以避免对象被修改,同时也可以避免对象的复制,提高程序的效率。
- 总结:引用的最大用处一般是函数的传参,引用可以作为函数的参数,允许在函数内部直接修改传递给函数的变量的值,而无需通过指针或返回值来实现
前言
在嵌入式学习和C语言开发中,已经无数次接触四大内存分区的概念了。
在计算机系统中,内存通常被划分为以下四个主要的分区:
代码区(Text Segment):也称为只读区,用于存储程序的机器指令。在程序执行之前,代码区的内容就已经确定,并且在程序运行期间是不可修改的。
数据区(Data Segment):用于存储全局变量和静态变量。数据区分为两个部分:初始化数据区和未初始化数据区。初始化数据区存储已经初始化的全局变量和静态变量,而未初始化数据区存储未初始化的全局变量和静态变量。
堆区(Heap):用于动态分配内存。在程序运行时,可以通过动态内存分配函数(如malloc、new等)从堆区分配一块内存,然后在不需要时手动释放。
栈区(Stack):用于存储函数调用时的局部变量、函数参数和返回地址等。栈区的内存分配和释放是由编译器自动完成的,遵循“先进后出”的原则。
以STM32的内存为例:其采用自上而下的栈结构。

一、不同的存储类型变量,会被存储在什么区?
#include 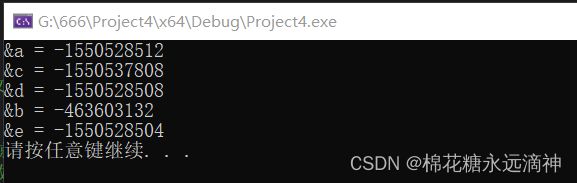
观察他们的地址,可以知道,全局变量、静态变量、常量地址非常靠近,说明他们被存储在同一个数据区。而局部变量则被存储在栈区。
①const修饰的局部变量放在栈区,全局变量放在只读数据区。
②static修饰的全局和局部变量都放在静态区(即数据区中的一个小区)
二、栈区
1.如果在函数A中定义了一个局部变量,那么在主函数里面是无法用取址符&去获取该局部变量的地址的。
取址符 & 用于获取变量的地址,但它只能在变量的作用域内使用。
2.return可以返回局部变量的值,但是不能返回局部变量的地址。
三、堆区:用new开辟内存空间,用delete销毁内存空间
①在C语言中,可以使用 malloc 函数来动态分配内存空间,并使用 free 函数来释放已分配的内存空间。
#include ②在C++中,可以使用 new 运算符来动态分配内存空间,并使用 delete 运算符来释放已分配的内存空间。
int* ptr = new int; // 动态分配一个 int 类型的内存空间
*ptr = 10; // 在分配的内存空间中存储值
// 使用分配的内存空间
cout << *ptr << endl;
delete ptr; // 释放内存空间
③用new创建的堆区,返回的是这个堆区的地址,所以需要用一个指针去接收。
④new运算符的用法:
int* p = new int(10);//int后面是括号,这代表创建了一个整型变量,其值为10
int* arr = new int[10]; // 动态分配一个含有10个元素的整型数组
// 使用分配的数组
for (int i = 0; i < 10; i++) {
arr[i] = i + 1;
cout << arr[i] << " ";
}
delete[] arr; // 释放内存空间
三、c++中的引用是干嘛的?
①引用就是给一个变量起一个别名(小名),但是这两个名字代表的是同一块内存空间。
语法为:数据类型& 别名 = 本名;
//1.创建一个变量
int a = 10;
//2.创建一个变量别名,即给一个变量起一个小名
//语法为:数据类型 &别名=原名;
int& b = a;
好比 name &小明 = 李明;
小明就是李明的别名,二者均指代这同一个人。
所以如果我修改别名b的值,那么同样a的值也会变,因为他们的内存空间是同一块。
②那变量和其别名的地址一样吗?
答:变量和其别名的地址是相同的。因为引用是变量的别名,它们共享相同的内存地址。在使用引用时,对引用的操作实际上就是对原始变量的操作。
③变量别名有啥用呢?就光是给变量起个小名吗?
答:主要有三个作用:
1.引用可以用作变量的别名,允许使用不同的名称访问同一个变量。
int a = 1;
int& b = a;
b=10;
把b赋值为10,那么a也就相应的修改为10。
2.作为函数参数:引用可以作为函数的参数,允许在函数内部直接修改传递给函数的变量的值,这样可以避免复制大型对象的开销。(就是类似地址传递)
void add1(int *p1) {//指针的地址传递,切实改变实参
*p1 += 1;
}
void add2(int& p2) {//引用的别名传递,同样切实的改变实参
p2 += 1;
}
int main() {
int a = 10;
add1(&a);//地址传递,传参要取地址
add2(a);//引用别名传递,直接是参数名,相当于int& p2 = a;
system("pause");
return 0;
}
那既然地址传递和引用别名传递都能切实的改变实参,那为什么要创造引用别名这一传递方式呢?地址传递不是也可以避免复制对象的开销吗?
答:
安全性和易用性:使用引用传递时,可以避免指针操作中的空指针和野指针问题,因为引用必须绑定到一个有效的对象上。同时,使用引用传递可以使代码更加简洁和易读,因为不需要使用 * 运算符来访问对象的值。
语义上的区别:引用传递更符合函数参数传递的语义,因为它表明函数需要访问原始对象,而不是创建对象的副本。而地址传递则更适用于需要在函数内部修改指针指向的对象的情况。
3.作为函数返回类型:函数的返回值被允许引用别名来代替。这样可以避免对象的复制开销,并且允许对返回的对象进行修改。
int& getLarger(int& a, int& b) {//函数的返回值,即返回值可以被允许引用别名
if (a > b) {
return a;
}
else {
return b;
}
}
int main() {
int x = 5;
int y = 10;
int& larger = getLarger(x, y);//别名laeger作为函数的返回值
cout << larger << endl; // 输出10 ,因为 larger 引用的是 返回值y
larger = 15; // 修改 larger 所引用的对象
cout << larger << endl; // 输出 15,因为 larger 被修改成15了。
return 0;
}
①引用作为函数返回值时,不能返回函数中的局部变量。
啥意思?就是说:如果我的函数里面int 了一个变量a,然后return a.
int& add(){
int a=5;
return a;
}
那么main函数接收时:
int& value=add();
cout << value<< endl; // 第一次输出5,因为编译器保留了结果
cout << value<< endl; // 第二次是随机值,因为局部变量被销毁后
//那块内存空间就不存在了,所以别名value也不知道自己是谁的小名,就混乱了。
②函数的引用可以作为左值(即在等号左边)
int& add(){
static int a=5;//修改成静态变量,就不会被销毁了。
return a;
}
那么main函数接收时:
int& value=add();
add()=1000;//相当于a=1000;
value =1000;//也相当于a=1000;
四、引用的本质到底是什么?——指针常量
这里就涉及一个拗口的知识:
指针常量:指针是常量。指向不能变,里面的值可以变。
常量指针:常量的指针。指向可以变,里面的值是定值不能变。
引用的本质是一个指针常量,它在创建时被初始化为指向某个对象的地址,并且在其生命周期内不能被修改指向其他对象的地址
//引用别名的本质:是一个指针常量
int liming = 10;
int& xiaoming = liming;//等效于: int* const xiaoming = &liming;
int* const xiaoming = &liming;//定义一个指针常量,指向liming这个变量
xiaoming = 15;//等效于:编译器认为就是:*xiaoming = 15;//解引用
五、函数参数传递时,用const修饰引用的参数别名。
const常量引用的用处:在函数参数中传递对象,以避免对象(在函数内部)被修改。
void print(const string& str) {
str="666";//非法的,在函数内部,不能通过const修饰的参数别名来修改本身的变量s
cout << str << endl;
}
int main() {
string s = "Hello, world!";
str="666";//合法的,因为字符串s本就是一个变量,可以进行修改
print(s);
return 0;
}