Linux--fork创建子进程详解
目录
一.初识fork函数
二.fork的返回值
三.fork原理
1.fork是如何创建子进程的?
2.为什么fork会有两个返回值?
3.为什么父进程的返回值是子进程的pid,子进程返回值是0?
4.fork之后,父子进程谁先运行?
5.如何理解同一个变量,会有不同的值?
一.初识fork函数
创建子进程的方式:
1.在命令行上创建
2.在代码中使用fork创建
今天讲述的是fork创造子进程。
使用man手册查看fork

验证:fork()创建了子进程
#include
#include
#include
int main()
{
printf("我是一父个进程,我的pid是:%d,ppid:%d\n",getpid(),getppid());
fork();
printf("我是一个进程,我的pid是:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
return 0;
} 观察图片,注意pid与ppid

在写一个循环情况观察:
#include
#include
#include
int main()
{
printf("我是一父个进程,我的pid是:%d,ppid:%d\n",getpid(),getppid());
fork();
while(1)
{
printf("我是一个进程,我的pid是:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
}
return 0;
} 
从图中我们可以看出fork()之后的代码执行行了两次,根据pid与ppid,我们可以看出是两个不同进程执行的且可以分出那个是子进程,那个是父进程
结论:只有父进程执行了fork之前的代码,fork之后,父子进程都要执行后续代码
二.fork的返回值
fork函数的返回值:
当创建子进程成功时:
有两个返回值,子进程的返回值是0,父进程的返回值是子进程的pid
当创建子进程失败:
有一个返回值,小于0.
代码验证:
#include
#include
#include
int main()
{
printf("我是一父个进程,我的pid是:%d,ppid:%d\n",getpid(),getppid());
pid_t id=fork();
while(1)
{
printf("我是一个进程,我的pid是:%d,ppid:%d\n, id=%d",getpid(),getppid(),id);
sleep(1);
}
return 0;
} 
为什么fork函数的返回值要有两个呢?
这里我们就不得不提为什么创建子进程。
原因:我们想要子进程协助父进程完成一些单进程解决不了的工作。如:对于想要电影边下载,边播放(可能不恰当,但有助于理解)。
因此,我们想要子进程与父进程执行不一样的代码。为了实现这个这个目的,我们让fork的返回值有两个,然后通过判断fork的返回值,判断谁是父进程,谁是子进程,然后让他们执行不同的代码
代码实例:
#include
#include
#include
int main()
{
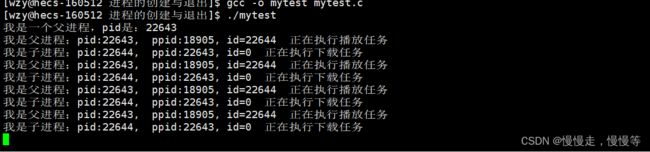
printf("我是一个父进程,pid是:%d\n",getpid());
pid_t id=fork();
if(id<0)
return 1;
else if(id==0)
{
while(1)
{
//child
printf("我是子进程;pid:%d, ppid:%d, id=%d 正在执行下载任务\n",getpid(),getppid(),id);
sleep(1);
}
}
else
{
while(1)
{
//parent
printf("我是父进程;pid:%d, ppid:%d, id=%d 正在执行播放任务\n",getpid(),getppid(),id);
sleep(1);
}
}
return 0;
}
三.fork原理
1.fork是如何创建子进程的?
我们知道
进程=可执行文件+内核数据结构(PCB)
在fork创建子进程时,系统会多一个子进程。
1.在内存中为子进程malloc申请空间并以父进程为模板,为子进程创建PCB并初始化(对父进程的PCB进行局部拷贝)
2.与父进程共享代码和数据.(这也是父子进程执行同样代码的原因)

这里我们知道了父子进程共享同一份代码与数据,那么为什么子进程不会执行fork之前的代码呢?
我们要知道程序之所以能够从上往下的顺序执行,依靠的是CPU中存在的pc/eip(程序计数器),当执行进程时,CPU会读取该进程的PCB里的pc/eip的值,然后从对应的代码开始执行。而fork创建子进程后,父进程的pc/eip指向了fork之后的代码,而子进程的PCB在创建的时候刚好拷贝了父进程的pc/eip,因此子进程不会执行fork之前的代码。
2.为什么fork会有两个返回值?
这里问大家一个问题:
如果一个函数已经执行到return了,它的核心工作做完了吗?
这里我们可以以swap(int* x,int* y)函数为例,我们可以通过调试发现,在函数执行到return的时候,两个数的数值早已交换。
因此可以认为函数在执行到return时,它的工作就已经做完了
而fork就是一个系统调用函数,fork的工作如下:
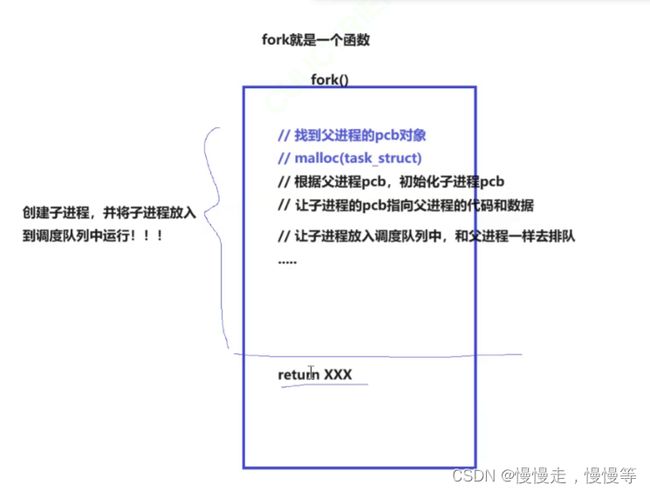
因此,在fork执行到return的时候,进已经完成了子进程的创建了。我们知道父子进程共享代码,而return时代码,因此return也被父子进程共享执行。
所以
父进程被调度,就要执行return
子进程被调度,也要执行return
3.为什么父进程的返回值是子进程的pid,子进程返回值是0?
这里我们举现实生活的例子:
在现实生活中,一个父亲可以有多个子女,但是子女只有一个父亲。
父:子=1:n,所以我们有一个天然的需求,父进程要管理子进程,需要标识子进程的唯一性,而子进程访问父进程时不需要的。而又由于子进程的pid具有唯一性,因此采用了该方法
4.fork之后,父子进程谁先运行?
在创建完子进程之后,系统的其他进程,父进程和子进程,接下来是要被调度的。
这里我们知道,操作系统是依靠双链表来管理进程的PCB的。
当父子进程的PCB都被创建并在运行队列中排队时,哪一个进程的PCB先被调度,那个进程就先运行。
而那个进程先被调度在用户层面上是不清楚的,因此我们并不知道父子进程谁先运行
因为它是由各自PCB中的调度信息(时间片,优先级)+调度器算法共同决定,完完全全又操作系统自主实现
5.如何理解同一个变量,会有不同的值?
这里由于牵扯到地址空间,会在地址空间详细解释,这里只是一个开头!
在前面我们知道fork在成功创建子进程时,两个返回值。但是这里我们使用一个变量接受的,为什么一个变量,会有不同的值 ?!!!
这里我们先说一个现象。
如果启动一个QQ,微信,浏览器。这些都是进程,如果杀掉微信进程,QQ进程,浏览器进程还在吗?当然还在。
如果父子进程中,父进程被杀掉,子进程还在吗?或者反过来。
实例:
#include
#include
#include
int main()
{
printf("我是一个父进程,pid是:%d\n",getpid());
pid_t id=fork();
if(id<0)
return 1;
else if(id==0)
{
while(1)
{
//child
printf("我是子进程;pid:%d, ppid:%d, id=%d 正在执行下载任务\n",getpid(),getppid(),id);
sleep(1);
}
}
else
{
while(1)
{
//parent
printf("我是父进程;pid:%d, ppid:%d, id=%d 正在执行播放任务\n",getpid(),getppid(),id);
sleep(1);
}
}
return 0;
}
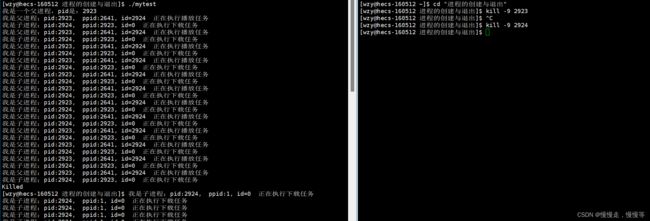
父进程被杀掉,子进程不受影响,仍可以正常运行
原因:进程进程之间运行的时候,是具有独立性的,无论是什么关系!
父子进程如何做到独立性,互不影响?
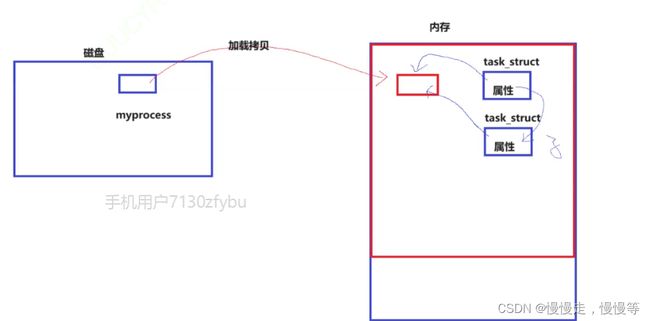
进程=可执行文件+内核数据结构(PCB)
1.父子进程有各自的PCB
2.由于代码是只读的,不会影响,数据数据父子是可以修改的。所以代码共享,数据各个进程要想办法私有一份。
而数据又是如何让私有的呢?
这里操作系统为了效率,采用了写时拷贝。
写时拷贝:在不修改数据时,父子进程共享数据,一旦修改数据,就会为修改数据的进程,重新开辟空间存储数据。
因此根据上述现象总结:
在fork函数的return处,子进程就创建完毕,开始共享代码与数据,而对于
id=fork();
这段代码,本质就是修改数据,因此发生写时拷贝,所以同一个变量会有不同的值!
那么具体是如何让一个变量的可以有两个值呢?
可能会有人觉得,只是变量名相同,地址不同。
这里我们可以用上面的代码将&id打印出来验证。

这里我们可以看出并不是的。
但是我们学过C语言,我们可以明确知道同一块地址空间,是不可能有不同内容的。
因此,我们可以确定:id的地址绝不是物理地址
接下来的内容由于牵扯到地址空间的内容,今天就讲到这里,还会在地址空间处详细讲解。