橘子学ES09之分词以及各大分词器
在ES中有很重要的一个概念就是分词,ES的全文检索也是基于分词结合倒排索引做的。所以这一文我们来看下何谓之分词。如何分词。
一、Analysis和Analyzer
Analysis和Analyzer是两个单词,第一个是动词,第二个是名字。
Analysis是指的文本分析,把一个文档全文文本按照规则转换成一系列的单词(term/token)的过程,也就是分词。
Analyzer是名词,他就是分词器,文本分析就是由他来完成的。ES内置有分词器,你也可以自己定制自己的分词器。
当我们写入一个文档的时候,ES的分词器会把文档分词,然后形成每个词的倒排索引结构。当我们再去查这个词的时候,还是要走一样的分析过程,这样才能达到分词检索的效果。
1、Analyzer的组成
分词器是专门处理分词的组件,在很多中间件设计中每个组件的职责都划分的很清楚,单一职责原则,以后改的时候好扩展。
分词器由三部分组成。
- Character Filters:主要是针对原始文本做处理,例如去除html
- Tokenizer:按照规则切分文本为单词,也就是分词
- Token Filter:将切分的单词进行加工,小写,删除stopwords,增加同义词。这里就是扩展功能都在这里处理。

可见就是当查询或者插入的时候经过这三个组件,然后成为词汇插入或者返回。
2、ES内置分词器
你可以自己扩展自己的分词器,比如 IK中文分词器,以前还听说还有个梵文分词器真是牛逼。当然了,ES内部也内置了很多种分词器供使用。具体如下。

3、测试分词器效果
一般测试分词效果有以下三种方式:
3.1、直接按照指定的分词器进行测试分词效果
GET /_analyze
{
"analyzer": "standard", 指定分词器
"text":"if you miss the train I am on,you will know that I am gone" 你要测试的文本
}
GET /_analyze
{
"analyzer": "standard",
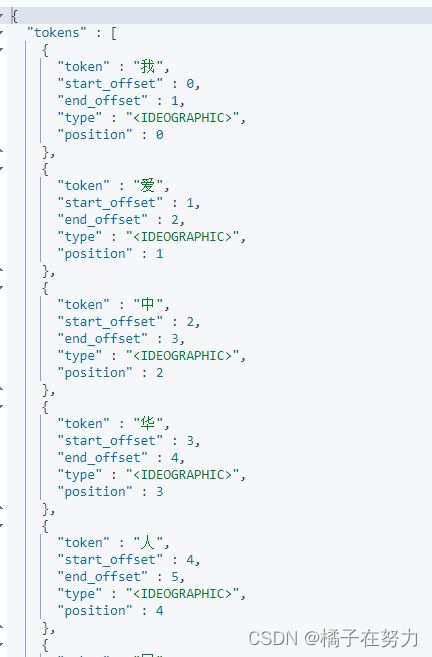
"text":"我爱中华人民共和国"
}
效果如下:我们指定的标准分词器,分析的结果就是每个文本都被以一个个词汇拆开了,他就是这么简单的分词。

3.2、指定索引中的字段,看分词效果
GET /movies/_mapping
POST movies/_analyze 指定索引
{
"field": "title", 分析你索引中字段的分析结果,分词器是你创建索引的时候指定的,各个字段可以不同分词器
"text": "god father"
}
效果如下:

3.3、指定自定义的分词器看分词效果
POST /_analyze
{
"tokenizer": "standard", 指定分词组件
"filter": ["lowercase"], 指定分词组件
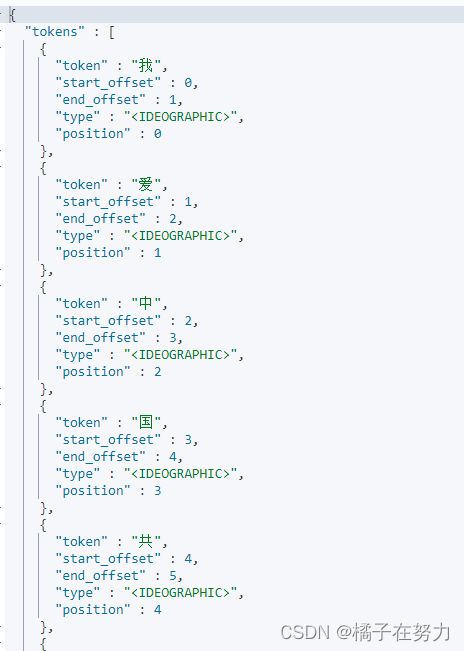
"text": "我爱中国共产党" 测试文本内容
}
测试效果如下:还是一个个词汇,因为本身都是默认的那个标准的,这个组合分词效果如下。
二、各大分词器
#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
#Whitespace Analyzer – 按照空格切分,不转小写
#Keyword Analyzer – 不分词,直接将输入当作输出
#Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
#Language – 提供了30多种常见语言的分词器
1、Standard 分词器
1.1、简介
标注分词器,ES中默认的分词器就是这个东西。他的各个组件的构成如下。
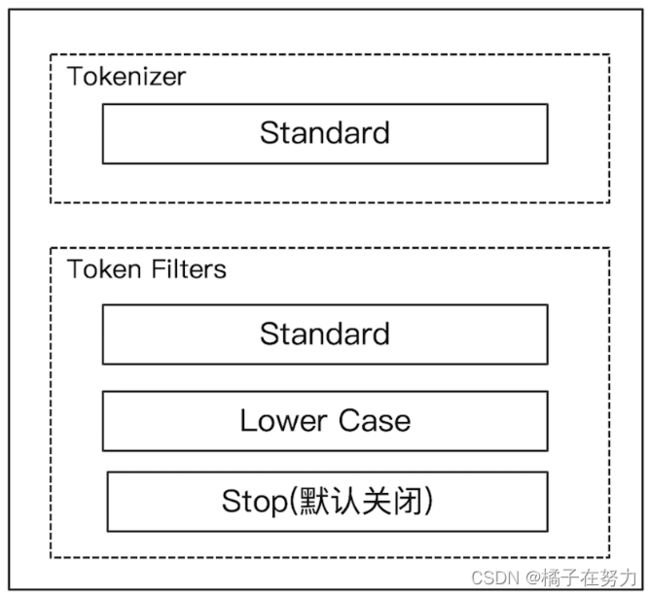
其特点就是按照词汇切分,不管什么文本都是一个一个词汇切开的。
对单词做了小写处理,也就是大小写一样的。
其停用词默认是关闭的。
1.2、测试
#standard
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
标准分词器就是按照一个个的词汇来拆分,然后大写转成了小写。

2、simpe分词器
2.1、简介
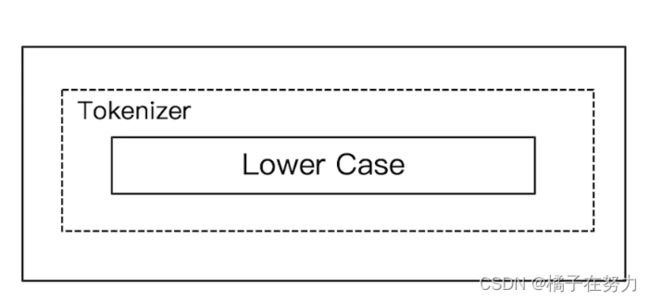
他的特点是按照非字母进行切分,把非字母去除剩下的一个个词汇进行按词汇切分。
最后大写转小写。
2.2、测试
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick 3 brown-foxes leap."
}
他把数字去掉了,剩下的按词汇切分。把中划线也去掉了,去掉之后brown foxes成为两个词。

3、whitespace分词器
3.1、简介

他的特点就是按照空格切分,然后剩余的都是一个个词。
不转小写。
3.2、测试
#whitespace
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over ."
}
结果就是按照空格拆分的,数字什么的都保留。不转小写。

4、stop分词器
4.1、简介

我们看到他多了一个组件stop,这个的作用就是去掉一些修饰词汇 is the a以及阿拉伯数字之类的。当成了停用词。
4.2、测试
# stop
GET _analyze
{
"analyzer": "stop",
"text": "2 he is sb 5"
}
数字和is会被去掉

5、keyword分词器
5.1、简介

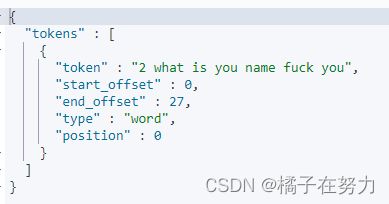
他的特点就是不分词,虽然是个分词器,但是不分词,他会把文档不做处理,原封不动。
如果你不需要分词就用这个。
5.2、测试
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 what is you name fuck you"
}
6、pattern分词器
6.1、简介
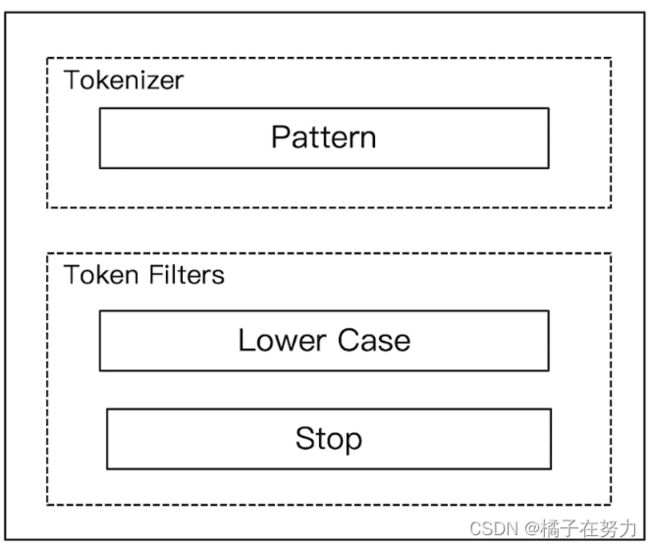
他的组件组成如上,他的特点就是通过正则表达式分词。有转小写,没有停用词。
默认是通过\W+这个正则,也就是非字母的符号进行分割。
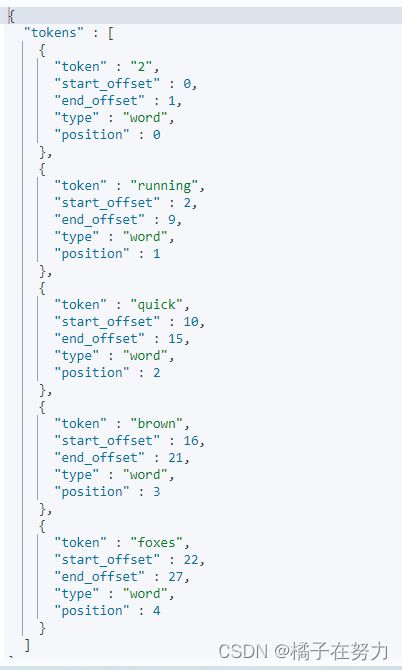
6.2、测试
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes "
}
因为那个中划线和空格都不是字母,所以被切开了。其余的就是转小写,以及is am a那些没被停用。
7、language分词器
7.1、简介
ES提供language分词器,为各个不同国家的语言进行分词具体的语言支持有以下几种。你可以指定语言。

他的特点就是比如我指定英文分词,有is am the那些停用了,然后什么进行时,过去式都会被去掉,没有时态,复数也会转为单数。
7.2、测试
#english
GET _analyze
{
"analyzer": "english", 指定英文
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}

三、中文分词
中文分词和上面的英文分词不一样,英文文档中每个词都会按照空格分开,你只需要按照空格分词就行了。但是中文限制很多,受限于语境,受限于词性。自然语言的限制,可以了解一下自然语言。
举个例子:
这个苹果,不大好吃 -----这个苹果不大,好吃。
这就很难顶,中文语言很麻烦。
1、ICU分词器
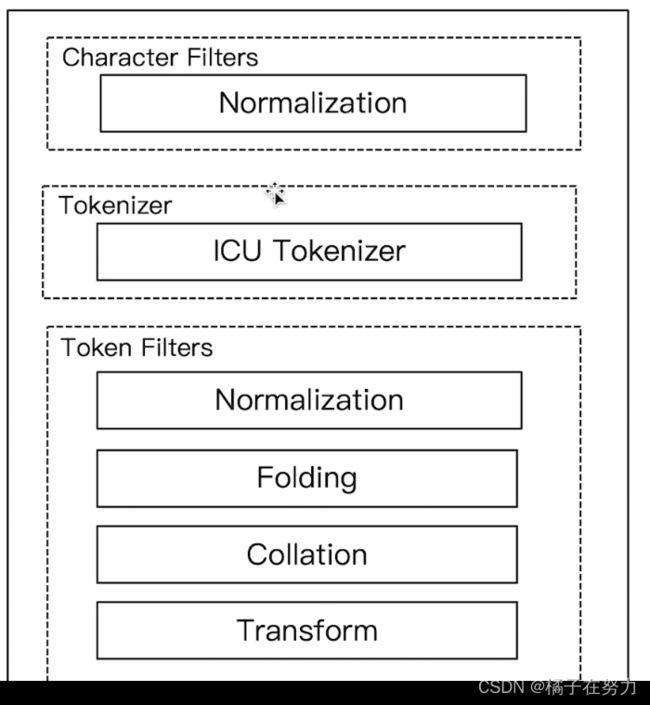
这个插件需要安装,ES不自带这个,该插件体提供了Unicode的支持,更好的支持亚洲语言。
具体怎么安装可以百度,贼简单。
测试语句在这里:
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
这个分词器分的还是不太好,中文分词器,我推荐IK分词器。

下面我来处理一下如何使用IK分词器。
2、IK分词器
目前我是docker启动的,所以需要先去下载一下这个IK分词器的包。
操作步骤:
1、查看一下当前环境的docker容器运行情况
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3b11fe0f1e23 docker.elastic.co/elasticsearch/elasticsearch:7.1.0 "/usr/local/bin/dock…" 3 days ago Up 2 hours 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 9300/tcp es7_01
9d2b07a931e5 lmenezes/cerebro:0.8.3 "/opt/cerebro/bin/ce…" 3 days ago Up 2 hours 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp cerebro
ca73ab08d5fb docker.elastic.co/kibana/kibana:7.1.0 "/usr/local/bin/kiba…" 3 days ago Up 2 hours 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana7
1fbf619f7735 docker.elastic.co/elasticsearch/elasticsearch:7.1.0 "/usr/local/bin/dock…" 3 days ago Up 2 hours 9200/tcp, 9300/tcp es7_02
2、进入容器中
docker exec -it es7_01 /bin/bash
3、执行下载拉取IK分词器的指令,注意版本和ES保持一致
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip
4、下载中点yes就行了,下载完后,退出容器
exit;
因为我有两个节点组成集群,所以每个节点都要安装一下,重复操作就行了。
5、重启docker容器
docker restart 1fbf619f7735
docker restart 3b11fe0f1e23
2.1、测试IK分词器
先看普通的分词器效果:
POST _analyze
{
"analyzer": "standard",
"text": "他的话确实有道理”"
}
我们看到就是按字拆分的,一个字一个字的,没啥语境可言。

再看IK分词器效果:IK分词器提供两种分词方式ik_smart和 ik_max_word
ik_smart:称为智能分词,网上还有别的称呼:最少切分,最粗粒度划分.分词的时候只分一次,句子里面的每个字只会出现一次。
ik_max_word:称为最细粒度划分,句子的字可以反复出现。 只要在词库里面出现过的 就拆分出来。如果没有出现的单字。如果已经在词里面出现过,那么这个就不会以单字的形势出现。尽可能细粒度的分。
ik_max_word:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "他的话确实有道理”"
}

这个其实也没分好。
ik_smart:
POST _analyze
{
"analyzer": "ik_smart",
"text": "他的话确实有道理”"
}

这个就分的很好了。自己选吧。此外IK分词器支持配置停用词,近义词等等操作,我们后面来处理。
四、总结
ES的分词机制是建立在几个组件上面的。
分词器由三部分组成。
- Character Filters:主要是针对原始文本做处理,例如去除html
- Tokenizer:按照规则切分文本为单词,也就是分词
- Token Filter:将切分的单词进行加工,小写,删除stopwords,增加同义词。这里就是扩展功能都在这里处理。
每个组件都做不同的事情,各大分词器就是不同的组件组合功能,最后的分词效果达到不同,你也可以自己开发一个.反正他是支持插件扩展的,类似IK。