论文阅读二——基于全脸外观的凝视估计
论文阅读二——基于全脸外观的凝视估计
-
- 基础知识
- 主要内容
- 文章中需要学习的架构
-
- AlexNet
- 代码复现
该论文是2017年在CVPR中发表的一篇关于 “gaze estimation” 的文章,其论文地址与代码地址如下:
论文地址
代码地址
论文特点:文章提出了一种基于外观的方法,只将完整的人脸图像作为输入,使用卷积神经网络对人脸图像进行编码,在特征图上应用空间权重,以灵活地抑制或增强不同面部区域的信息。
基础知识
凝视估计的方法主要可以分成两种:基于模型的方法和基于外观的方法。
-
基于模型的方法:使用眼睛和面部的几何模型来估计注视方向。(会受到图像质量低和光照条件变化的影响)
- 基于角膜反射的方法:依靠外部光源来检测眼睛的特征。
- 基于形状的方法:从观察到的眼睛形状,如瞳孔中心和虹膜边缘推断凝视方向。
-
基于外观的方法:直接从眼部图像到注视方向进行回归,根据回归目标是2D还是3D还可以进一步进行分类,需要更大量的特定于用户的训练数据。如下:
| 特征 | 2D眼动估计方法 | 3D眼动估计方法 |
|---|---|---|
| 基本假设 | 目标头部姿势固定 | 目标头部姿势可以自由移动 |
| 任务重点(估计器) | 输出屏幕上的2D注视位置(x, y) | 输出在摄像机坐标系中的3D注视方向(x, y, z) |
| 摄像机移动限制 | 不允许自由摄像机移动 | 允许自由摄像机移动 |
| 技术挑战 | 可能受到头部姿势变化的限制 | 如何在不需要大量训练数据的情况下有效训练估计器 |
“单眼基线法”:指使用只有一个眼睛的信息进行眼动估计的基本方法。(使用单个眼睛)
iTracker (AlexNet) :一种基于深度学习(卷积神经网络)的眼动估计方法,仅用眼睛和脸部的裁剪来训练网络,旨在利用单眼图像进行注视点的预测。
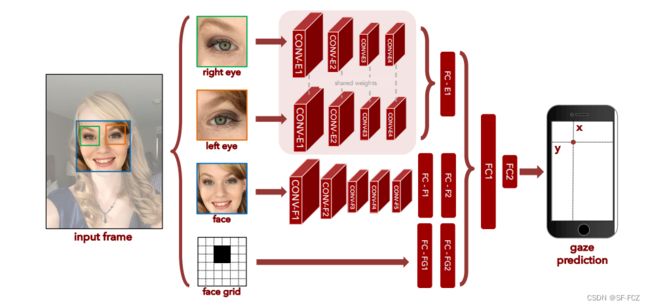
“Two eyes” :指的是同时利用两只眼睛的信息进行眼动估计的方法,两只眼睛提供了更多的深度和空间信息,有助于更准确地估计用户的注视点和眼动轨迹。
主要内容
文章指出,在机器学习方法能够从面部的其他区域获得额外的信息,采用一个多区域的卷积神经网络(CNN)架构,将眼部图像和面部图像同时作为输入,有助于提高眼动估计的性能。这些区域可能包括头部姿势或在整个图像区域内编码照明特定信息(例如:头部姿势、凝视方向和光照)的部分。相比于眼部区域,这些区域可能覆盖更大的图像范围。因此,文章作者针对MPIIGaze数据集,引入了全脸CNN架构与空间权重机制:
- 基于空间权重CNN的人脸凝视估计
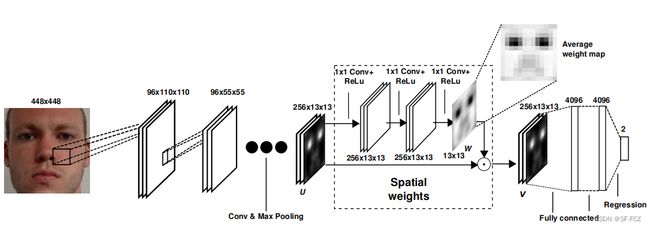
如上图,输入图像通过多个卷积层来生成特征张量U。所提出的空间权重机制以U为输入来生成使用逐元素乘法将权重映射W应用于U。输出特征张量V被馈送到根据任务的不同,按照全连接层输出最终的2D或3D凝视估计。上图中使用了三个1×1卷积层加上校正的线性单元层(Relu激活函数)的概念作为基础,将其适应于全人脸凝视估计任务,迫使网络更明确地学习和理解面部的不同区域对估计给定测试样本的凝视的不同重要性,而这部分也就是空间权重机制的结构。
全脸估计带来了头部姿势信息,可以作为眼球凝视方向的一个先验信息。
1. 直接将头部姿势作为凝视方向的朴素估计器
1. 通过训练从头部姿势输入输出凝视方向的线性回归函数。
1. 结论:不同的面部区域在推断注视方向时具有不同的重要性。(当注视方向直视前方时,眼睛区域最为重要,而当注视方向变得更极端时,模型对其他区域的重要性提高。)
- 空间权重机制
从3个1×1卷积层获得的激活张量 U(大小为 N×H×W)用于生成一个大小为 H×W 的空间权重矩阵 W。通过将 W 与 U 逐元素相乘,得到加权激活图 Vc=W⊙Uc,其中 U**c 是 U 的第 c 个通道,而 Vc 对应于相同通道的加权激活图。这些加权激活图堆叠形成加权激活张量 V,然后传递到下一层。在训练期间,前两个卷积层的过滤权重从均值为0、方差为0.01的高斯分布中随机初始化,偏差为0.1。最后一个卷积层的过滤权重从均值为0、方差为0.001的高斯分布中随机初始化,偏差为1。计算相对于 U 和 W 的梯度,其中∂U/∂V 等于梯度 ,而 ∂W/∂V 等于所有通道的梯度∂W/∂Uc 的平均值。与权重相关的梯度 ∂W/∂V 被总特征图的数量 N 归一化。这个机制通过学习连续的空间权重,保持来自不同面部区域的信息,提高了网络对全脸外观的眼动估计任务的性能。
- 图像归一化:对输入图像应用透视变换,使得估计可以在具有固定摄像机参数和参考点位置的归一化空间中进行。通过这种方法,可以处理不同摄像机参数,并在归一化的空间中进行训练和估计。
文章中需要学习的架构
AlexNet
该架构由八层组成:五个卷积层和三个全连接层。其结构图,如下:
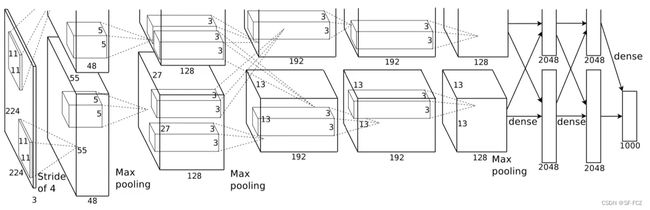
以ImageNet数据集为例子,对AlexNet每一层进行分析:
-
第一层:输入层
输入图像的大小为227x227x3(RGB三通道)。 -
第二层:卷积层(Convolutional Layer)
96个大小为11x11x3的卷积核,步长为4。
使用ReLU激活函数。
池化层(Max Pooling):3x3大小,步长为2。 -
第三层:卷积层
256个大小为5x5x48的卷积核。
使用ReLU激活函数。
池化层:3x3大小,步长为2。 -
第四层:卷积层
384个大小为3x3x256的卷积核。
使用ReLU激活函数。 -
第五层:卷积层
384个大小为3x3x192的卷积核。
使用ReLU激活函数。 -
第六层:卷积层
256个大小为3x3x192的卷积核。
使用ReLU激活函数。
池化层:3x3大小,步长为2。 -
第七层:全连接层(Fully Connected Layer)
4096个神经元。
使用ReLU激活函数。
Dropout:为了减少过拟合,引入了Dropout操作。 -
第八层:全连接层
4096个神经元。
使用ReLU激活函数,Dropout。 -
第九层:全连接层,也是输出层
1000个神经元,对应ImageNet数据集中的类别数。
使用Softmax激活函数进行分类。
代码复现
首先,根据下载后的代码进行搭建环境,最好配置一个专门的虚拟环境,防止因为环境紊乱而无法完成操作。这里主要强调:需要根据代码的README.md文档进行操作。
其次,在搭建好环境后,我主要遇到了一个问题,就是gazenet.py中的models.mobilenet.ConvBNReLU(320, 256, kernel_size=1)已经不用了,需要进行以下操作:
# 添加以下代码
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
# 将原文中的`model.mobilenet.convBNReLU`进行替换
model.features[-1] = ConvBNReLU(320, 256, kernel_size=1)
最后的gazenet.py文件的内容为:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import numpy as np
from PIL import Image
from torchvision import transforms
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class GazeNet(nn.Module):
def __init__(self, device):
super(GazeNet, self).__init__()
self.device = device
self.preprocess = transforms.Compose([
transforms.Resize((112,112)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
model = models.mobilenet_v2(pretrained=True)
model.features[-1] = ConvBNReLU(320, 256, kernel_size=1)
self.backbone = model.features
self.Conv1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1, padding=0)
self.Conv2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1, padding=0)
self.Conv3 = nn.Conv2d(in_channels=256, out_channels=1, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Sequential(
nn.Linear(256*4*4, 512),
nn.ReLU(),
nn.Dropout(0.5)
)
self.fc2 = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.5)
)
self.fc_final = nn.Linear(512, 2)
self._initialize_weight()
self._initialize_bias()
self.to(device)
def _initialize_weight(self):
nn.init.normal_(self.Conv1.weight, mean=0.0, std=0.01)
nn.init.normal_(self.Conv2.weight, mean=0.0, std=0.01)
nn.init.normal_(self.Conv3.weight, mean=0.0, std=0.001)
def _initialize_bias(self):
nn.init.constant_(self.Conv1.bias, val=0.1)
nn.init.constant_(self.Conv2.bias, val=0.1)
nn.init.constant_(self.Conv3.bias, val=1)
def forward(self, x):
x = self.backbone(x)
y = F.relu(self.Conv1(x))
y = F.relu(self.Conv2(y))
y = F.relu(self.Conv3(y))
x = F.dropout(F.relu(torch.mul(x, y)), 0.5)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
gaze = self.fc_final(x)
return gaze
def get_gaze(self, img):
img = Image.fromarray(img)
img = self.preprocess(img)[np.newaxis,:,:,:]
x = self.forward(img.to(self.device))
return x
最终运行cam_demo.py,最终可以实现实时检测人眼眼球凝视方向。