下午好~ 我的论文【遥感】(第一期)
写在前面:下午浑浑噩噩,泡杯茶,读篇论文吧
首先说明,时间有限没有那么精力一一回复了,对不起各位了TAT
文章目录
- 遥感
-
- Bi-Dilation-former
- CNN-GNN-Fusion
- Multi-hierarchical cross transformer
- Coupled CNNs
遥感
Bi-Dilation-former
Bidirectional Dilation Transformer for Multispectral and Hyperspectral Image Fusion
IJCAI 23
摘要:
基于Transformer的方法已被证明在各种计算机视觉任务中实现长距离建模、捕捉空间和光谱信息以及展示强大的归纳偏置方面是有效的。通常,Transformer模型包括两种常见的多头自注意力(MSA)模式:空间MSA(Spa-MSA)和光谱MSA(Spe-MSA)。然而,Spa-MSA计算效率高,但限制了局部窗口内的全局空间响应。另一方面,Spe-MSA可以计算通道自注意力以适应高分辨率图像,但它忽略了对低层次视觉任务至关重要的关键局部信息。在本研究中,我们提出了一种用于多光谱和高光谱图像融合(MHIF)的双向扩张Transformer(BDT),旨在利用MSA和MHIF任务特有的潜在多尺度信息的优势。BDT由两个设计模块组成:通过给定的空心策略动态扩展空间感受野的扩张Spa-MSA(D-Spa),以及提取特征图内的潜在特征并学习局部数据行为的分组Spe-MSA(G-Spe)。此外,为了充分利用具有不同空间分辨率的两个输入的多尺度信息,我们在BDT中采用了双向分层策略,从而提高了性能。最后,在两个常用的数据集CAVE和Harvard上进行的大量实验证明了BDT在视觉和定量方面的优越性。此外,相关代码可在https://github.com/Dengshangqi/BDT获取。

图1: 1. (a)Spa-MSA:基于Spa的多尺度自注意力。2. (b)D-Spa:在Spa-MSA基础上提出的扩展版本,通过扩张操作增加感受野。3. ( c )Spe-MSA:基于Spe的多尺度自注意力。4. (d)G-Spe:在Spe-MSA基础上提出的改进版本,允许模型在特征图中学习更多的数据行为。

图2:展示了双向融合决策树(BDT)方法的架构图。该方法由两个分支组成,分别是空间分支和光谱分支,用于提取和融合双模特征。在BFE阶段,通过空间分支和光谱分支提取双模特征。再将提取到的特征配对到BFF阶段,生成最终的输出结果。
主要是两个核心:
D-spa
空间上的注意力,输入是[bs, (h*w), c],
核心函数,Win_Dila实现了一个窗口交错操作。
x:输入张量,维度为[B, H, W, C],其中B是batch大小,H是高度,W是宽度,C是通道数。
win_size:窗口大小。
n_win:窗口数量。
B, H, W, C = x.shape:获取输入张量的维度信息。
x = x.reshape(-1, (H // n_win), n_win, (W // n_win), n_win, C):通过reshape操作将输入张量重新组织为形状为[B, n1, n_win, n2, n_win, C]的张量,其中n1 = H // n_win,n2 = W // n_win。
x = x.permute(0, 1, 3, 2, 4, 5):对张量进行维度变换,将维度排列为[B, n1, n2, n_win, n_win, C]。
xt = torch.zeros_like(x):创建一个与x具有相同形状的全零张量xt。
分别将x的四个子块赋值给xt的不同位置:
x0 = x[:, :, :, 0::2, 0::2, :]:提取x的子块,步长为2,起始位置为(0,0)。
x1 = x[:, :, :, 0::2, 1::2, :]:提取x的子块,步长为2,起始位置为(0,1)。
x2 = x[:, :, :, 1::2, 0::2, :]:提取x的子块,步长为2,起始位置为(1,0)。
x3 = x[:, :, :, 1::2, 1::2, :]:提取x的子块,步长为2,起始位置为(1,1)。
这一步就是Dila扩展操作,每隔2取一个,类似conv的空洞效果
使用赋值操作将子块放置在xt的相应位置,分成左上、左下、右上、右下,四个大区域:
xt[:, :, :, 0:n_win//2, 0:n_win//2, :] = x0:将x0放置在xt的左上区域。
xt[:, :, :, 0:n_win//2, n_win//2:n_win, :] = x1:将x1放置在xt的左下区域。
xt[:, :, :, n_win//2:n_win, 0:n_win//2, :] = x2:将x2放置在xt的右上区域。
xt[:, :, :, n_win//2:n_win, n_win//2:n_win, :] = x3:将x3放置在xt的右下区域。
xt = xt.permute(0, 1, 3, 2, 4, 5):对xt进行维度变换,将维度排列为[B, n1, n2, n_win, n_win, C]。
xt = xt.reshape(-1, H, W, C):通过reshape操作将张量重新组织为形状为[B * ?, H, W, C]的张量,即为最终的输出y。
def Win_Dila(x, win_size):
"""
:param x: B, H, W, C
:param
:return: y: B, H, W, C
"""
n_win = win_size * 2
B, H, W, C = x.shape
x = x.reshape(-1, (H // n_win), n_win, (W // n_win), n_win, C) # B x n1 x n_win x n2 x n_win x C
x = x.permute(0, 1, 3, 2, 4, 5) # B x n1 x n2 x n_win x n_win x C
xt = torch.zeros_like(x)
x0 = x[:, :, :, 0::2, 0::2, :]
x1 = x[:, :, :, 0::2, 1::2, :]
x2 = x[:, :, :, 1::2, 0::2, :]
x3 = x[:, :, :, 1::2, 1::2, :]
xt[:, :, :, 0:n_win//2, 0:n_win//2, :] = x0 # B n/2 n/2 d2c
xt[:, :, :, 0:n_win//2, n_win//2:n_win, :] = x1 # B n/2 n/2 d2c
xt[:, :, :, n_win//2:n_win, 0:n_win//2, :] = x2 # B n/2 n/2 d2c
xt[:, :, :, n_win//2:n_win, n_win//2:n_win, :] = x3 # B n/2 n/2 d2c
xt = xt.permute(0, 1, 3, 2, 4, 5)
xt = xt.reshape(-1, H, W, C)
def Win_ReDila(x, win_size):
"""
:param x: B, H, W, C
:param
:return: y: B, H, W, C
"""
n_win = win_size * 2
B, H, W, C = x.shape
x = x.reshape(-1, (H // n_win), n_win, (W // n_win), n_win, C) # B x n1 x n_win x n2 x n_win x C
x = x.permute(0, 1, 3, 2, 4, 5) # B x n1 x n2 x n_win x n_win x C
xt = torch.zeros_like(x)
xt[:, :, :, 0::2, 0::2, :] = x[:, :, :, 0:n_win // 2, 0:n_win // 2, :]
xt[:, :, :, 0::2, 1::2, :] = x[:, :, :, 0:n_win // 2, n_win // 2:n_win, :]
xt[:, :, :, 1::2, 0::2, :] = x[:, :, :, n_win // 2:n_win, 0:n_win // 2, :]
xt[:, :, :, 1::2, 1::2, :] = x[:, :, :, n_win // 2:n_win, n_win // 2:n_win, :]
xt = xt.permute(0, 1, 3, 2, 4, 5)
xt = xt.reshape(-1, H, W, C)
return xt
G-spe
光谱维度上注意,输入是[bs, c, (h*w)]
核心操作window_partition:函数的作用是将输入张量划分为一系列固定大小的小窗口,并返回这些小窗口
x:输入张量,维度为[B, H, W, C],其中B是batch大小,H是高度,W是宽度,C是通道数。
window_size:窗口大小。
接下来,开始进行窗口划分操作:
B, H, W, C = x.shape:获取输入张量的维度信息。
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C):通过view操作将输入张量重新组织为形状为[B, H // window_size, window_size, W // window_size, window_size, C]的张量。
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C):对张量进行维度变换,将维度排列为[num_windows * B, window_size, window_size, C]。将原始图像划分为一系列大小为window_size的小窗口。
permute操作通过指定维度的顺序将张量重新排列,这里的顺序是(0, 1, 3, 2, 4, 5)。
contiguous操作使用连续的内存重新排列张量,以确保能顺利进行后续的view操作。
view操作通过指定新的形状将张量重新组织为所需的形状。
最后,返回划分后的窗口张量windows。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
CNN-GNN-Fusion
Weighted Feature Fusion of Convolutional Neural Network and Graph Attention Network for Hyperspectral Image Classification
IEEE TRANSACTIONS ON IMAGE PROCESSING 2022
本文介绍了一种名为“加权特征融合的卷积神经网络和图注意力网络”的方法,用于高光谱图像分类。作者指出,尽管卷积神经网络(CNN)和图注意力网络(GAT)在高光谱图像分类领域都取得了显著的成果,但CNN面临小样本问题,而GAT则需付出巨大的计算成本,这限制了两者的性能。为了解决这一问题,作者提出了WFCG方法,该方法结合了基于超像素的GAT和基于像素的CNN的特点,并利用注意力机制构建CNN。最后,通过加权融合两种神经网络模型的特征,WFCG能够充分挖掘高光谱图像的高维特征,并在三个真实世界高光谱数据集上获得了与现有最先进技术相竞争的结果。此外,文章还探讨了卷积神经网络(CNN)和图神经网络(GNN)在高光谱图像(HSI)分类任务中的特点和应用。
小样本问题是指在监督学习中,由于训练样本数量较少,模型可能过拟合,导致泛化能力较差的问题。
CNN具有局部连接和权重共享的特性,可以显著减少参数数量。通过划分patches,CNN能够同时捕获光谱信息和空间信息。
CNN已经在HSI分类领域发挥了越来越重要的作用。例如,端到端的光谱-空间残差网络(SSRN)可以直接将原始的3D立方体数据作为输入,避免了在HSI上进行复杂的特征工程。另一种混合光谱CNN(HybridSN)则是一个光谱-空间3D-CNN,后面跟随一个空间2D-CNN,以进一步学习更抽象级别的空间表示。
而GNN方法可以通过超像素基方法将HSI数据转换为图数据,然后有效地建模光谱-空间上下文信息。这样,标签的数量就被隐式地扩展了,从而在一定程度上缓解了小样本的问题。(我是这么理解的:HSI数据可以通过超像素基方法转换为图数据,每个节点都可以与多个邻居节点连接,从而将一个节点的标签信息传播到其邻居节点上,那么这些邻居节点可以打上标签,使得标签的数量被隐式地增加(?))
例如,基于超像素分割的图卷积网络(GCN)首次被应用于HSI。它使用多阶邻节点构建邻接矩阵,使GCN能够捕获多尺度的空间信息。之后,又提出了一种在训练过程中自动学习图结构的方法,这可以促进节点特征的学习,并使图更能适应HSI的内容。
Dual Attention Network
是一种结合了CNN和图注意力网络(GAT)的深度学习框架。该框架通过加权特征融合的方法,将CNN和GAT的特征进行有效融合,用于高光谱图像分类任务。
首先对GAT特征进行全连接层和归一化处理,增强稳定性。
在卷积网络分支中引入注意力机制,以捕捉长距离信息和高级特征。
使用权重矩阵对输入节点特征进行线性变换。
使用共享注意力机制计算节点之间的注意力系数。
使用softmax函数对注意力系数进行归一化处理,得到权重信息。
通过矩阵乘法、reshape等操作,将空间注意力映射与输入特征相乘并求和,得到最终输出。
该模型还利用了位置注意力模块来获取更准确的边界信息。
由于使用超像素划分,标签数量是隐式扩展的,所以模型可以在少量标签的情况下保持高精度。
CNN分支具有强大的表达能力,可以自适应地转换信息并捕获不同维度、位置和尺度的准确边界信息。

WFCG模型的框架主要分为八个部分:
a. 光谱卷积层(Spectral convolutional layers),用于提取HSI数据的光谱特征。
作者提到在初始阶段使用了两个1×1的卷积层。这两个卷积层主要用于交换通道信息以去除无用的光谱信息并提高判别能力,同时也作为降维模块以降低计算成本。然后,由于原始的高光谱图像包含噪声和冗余信息,这些卷积层还被用作维度降低模块。
b. 数据转换模块(Data conversion module),包括分支一中的生成编码器和解码器关联节点特征激活和矩阵嵌入序列归一化以及权重化数据特征。
Data conversion module是一种将像素数据转换为节点数据的模块。在这个过程中,首先对HSI数据进行分割,得到superpixels。
Superpixels是一种图像分割技术,它将图像中的像素点聚集成一些区域,每个区域内的像素具有相似的颜色或纹理。这种技术可以用于高光谱图像(HSI)的处理,将HSI数据转换为图数据。
然后,计算每个superpixel的平均辐射度,将其作为节点的值。
最后,通过编码器和解码器实现特征的转换。编码器将像素特征转换为节点特征,解码器则将节点特征转换回网格特征。这种数据转换允许特征在图神经网络(GNN)和卷积神经网络(CNN)之间平滑传递。
下图为像素和超像素数据转换模块的流程图,其中Xi表示展平的HSI中的第i个像素,Vj表示包含在超像素S j 中的像素的平均辐射度。

c. 图注意力模块(Graph attention module),用于建模光谱-空间上下文信息。
Graph attention module是一种图神经网络中的注意力机制,它允许网络选择性地关注图中的不同节点。
详细见GAT,我也还没看()
输入节点特征(N,dim)和邻接矩阵(N,N)进入GAT,输出节点特征(N,dim)
d. 非线性特征变换模块(Non-linear feature transformation module),对特征进行进一步的非线性变换。
细节没看,通过图片估计是一层DNN+激活函数
e. 位置注意力模块和通道注意力模块(Position attention module and channel attention module),用于增强模型对空间位置和通道信息的关注度。
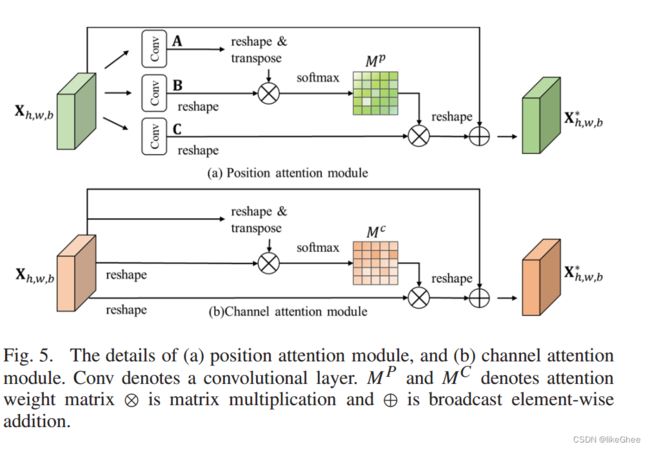
f. 深度可分离卷积层(Depthwise separable convolutional layers),使用轻量级的深度可分离卷积来构建二维卷积神经网络,以减少参数数量并提高鲁棒性。
g. 加权特征融合模块(Weighted feature fusion module),用于充分探索样本的特征并具有较强的表达能力,从而获得较高的分类精度。
作者为两个分支分别赋予了不同的权重n来进行不同程度的缩放,使得模型能够更好地融合。
由于两个分支的不同神经网络模型的影响,这两个分支的特征分布也不同。我们为这两个分支分配不同的权重 η,以便执行不同程度的缩放,从而使模型能够更好地集成,如下所示:
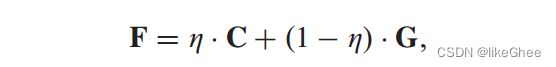
论文里面设置的是η=0.05
h. Softmax层,用于输出预测结果。
最后,通过softmax函数获取分类标签Y。
Multi-hierarchical cross transformer
MCT-Net: Multi-hierarchical cross transformer for hyperspectral and multispectral image fusion
Knowledge-Based Systems
摘要:
本文介绍了一种名为MCT-Net的多级跨变换器网络,用于高光谱和多光谱图像融合。由于光学成像的限制,图像采集设备通常需要在空间信息和光谱信息之间进行权衡。高光谱图像具有丰富的光谱信息,可以精确识别和分类成像对象,而多光谱图像则具有足够的几何特征。因此,融合HSI和MSI以实现信息互补已成为一种普遍的方式,从而提高了获得的信息的可靠性和准确性。
MCT-Net由两个组件组成:(1) 一个多级跨模态交互模块(MCIM),首先提取HSI和MSI的深度多尺度特征,然后在相同尺度上通过应用多级跨变换器(MCT)执行跨模态信息交互,以重建缺乏在MSI中的光谱信息和在HSI中的空间信息;(2) 一个特征聚合重建模块(FARM),该模块结合了MCIM的特征,使用带状卷积进一步恢复边缘特征,并通过级联上采样重建融合结果。
作者在五个主流HSI数据集上进行了比较实验,证明了所提出方法的有效性和优越性。总体而言,MCT-Net是一种有效的深度学习模型,能够有效地融合多光谱和高光谱图像,提高图像质量。在未来的研究中,可以进一步探索如何优化模型的性能,以及如何将其应用于其他领域。
图1:所提出的用于高光谱图像和多光谱图像融合的多层次交叉变换器的框架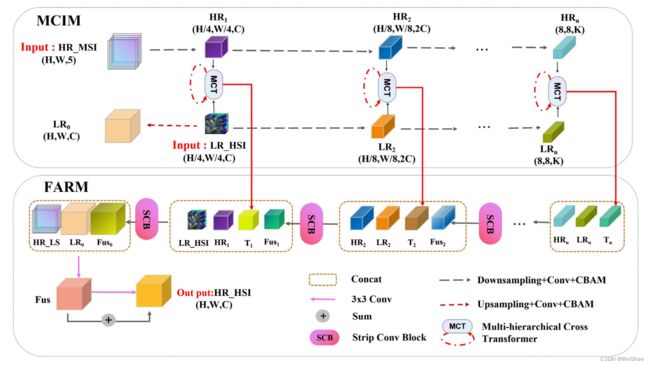
所提出的用于高光谱图像和多光谱图像融合的多层次交叉变换器(MCT-Net)的框架由两个阶段组成。
-
第一阶段是多层次跨模态交互模块(MCIM),提取HSI和MSI的深层多尺度特征。
-
第二阶段是特征聚合重建模块(FARM),它结合了MCIM的特征,使用条卷积来恢复边缘特征,并通过级联上采样重建融合结果。
我看了主干是下采样,卷积和CBAM
主要模块是两个MCT和SCB
图2:多级交叉变换器(MCT)的结构描述
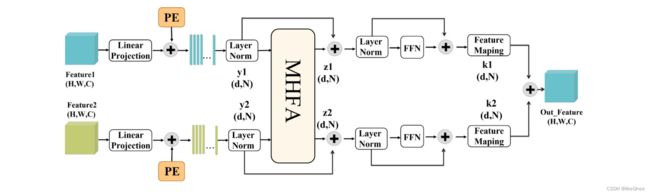
MCT采用双分支结构,由多头融合注意力(MHFA)块和前馈网络(FFN)组成。PE表示图中的位置嵌入。然后将MCT的输出特征输入到FARM。
图3:多头融合注意力(MHFA)的结构描述。
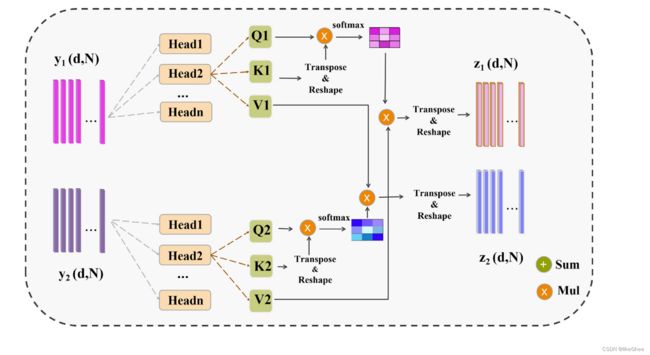
将输入特征转换为Q、K和V特征,并通过交叉乘法生成注意力图。
图4:strip convolution block.的结构。对于输入特征图,条卷积块从四个不同的方向捕获长程上下文信息:水平、垂直、左对角线和右对角线。

Coupled CNNs
Classification of Hyperspectral and LiDAR Data Using Coupled CNNs
IEEE Transactions on Geoscience and Remote Sensing. 2020
2020的时间也比较旧了
TGRS的计算机文章图一乐就好,饭后消遣用…
摘要:
该研究提出了一种有效的框架,利用耦合的卷积神经网络(CNNs)来融合高光谱和激光雷达(LiDAR)数据。高光谱数据具有丰富的光谱信息,而LiDAR数据可以记录物体的海拔信息,为高光谱数据提供补充。由于城市和农村地区存在许多难以区分的复杂对象,因此融合这两种异构特征是很有前景的。研究中设计了一个CNN来从高光谱数据中学习光谱-空间特征,另一个CNN则用于从LiDAR数据中捕获海拔信息。两者都由三个卷积层组成,最后两个卷积层通过参数共享策略进行耦合。在融合阶段,同时使用了特征级和决策级的融合方法来充分整合这些异构特征。为了评估不同的融合策略,文中采用了连接、最大化和求和三种策略。对于决策级融合,采用了加权求和策略,其中权重由每个输出的分类准确率决定。该模型在休斯顿和美国特伦托的数据集中进行了评估,分别获得了96.03%和99.12%的总体准确率,证明了其有效性。总体而言,这项研究强调了高光谱和LiDAR数据融合在土地使用和土地覆盖分类中的潜力和应用价值。该研究提出了一种基于CNN的高效融合方法,用于融合高光谱和激光雷达数据。与现有的融合模型相比,该方法具有更高的效率和效果。
研究采用了以下三个主要步骤:
-
设计了两个耦合的CNN来充分融合高光谱和激光雷达数据。这些耦合的卷积层可以减少参数数量,并引导两个CNN相互学习,从而促进后续的特征融合过程。
-
在融合阶段,研究同时采用了特征级和决策级融合策略。对于特征级融合,除了广泛采用的连接方法外,还提出了求和和最大化融合方法。为了增强学习到的特征的判别能力,还在CNN中添加了两个输出层。这三个输出结果通过加权求和方式组合在一起,其权重由每个输出在训练数据上的分类准确率确定。
-
通过对两个数据集进行测试,验证了所提出模型的有效性。在休斯顿数据集上,研究实现了96.03%的总体准确率,这是文献中报道的最佳结果。该研究提出了一种基于耦合CNN的融合模型,用于处理高光谱和LiDAR数据。该模型包括两个主要部分:一个HS网络和一个LiDAR网络,分别用来学习光谱-空间特征和高度特征。在HS网络中,首先使用PCA减少原始高光谱数据的冗余信息,然后从第二个卷积层提取一个小立方体。类似地,可以从LiDAR数据中直接提取相同位置的图像补丁。在特征学习模块中,使用了三个卷积层,其中最后两个共享参数。在融合模块中,构建了三个分类器。每个CNN都有一个输出层,它们的融合特征也被输入到一个输出层。为了有效地融合X和Y的信息,提出了一种新的基于特征级和决策级的结合策略。最终的输出是所有输出层的集成结果。该研究提出了一种基于深度学习的融合方法,用于处理和分类来自不同源的数据。具体来说,该方法结合了卷积神经网络(CNN)、特征级和决策级的融合策略,以实现对来自高光谱和激光雷达(LiDAR)数据的高效处理和准确分类。
知识补充:
"异构特征"通常用于描述具有不同性质或类型的特征,特别是在数据科学、机器学习和计算机视觉等领域中。这里有一些相关的解释:
数据科学和机器学习: 在机器学习任务中,数据往往包含多种类型的特征,例如数值型、类别型、文本型等。这些不同类型的特征被称为异构特征,因为它们在类型和性质上存在差异。处理异构特征可能需要不同的技术和方法。
计算机视觉: 在图像处理中,异构特征可能指的是来自不同传感器或不同模态的特征。例如,结合光学图像和红外图像,利用它们的不同特性来提高目标检测的性能。
数据库和数据集成: 在数据库领域,异构特征可以指的是来自不同数据源、不同数据库或不同数据模型的特征。数据集成的任务就是将这些异构的数据整合在一起,使其能够协同工作。
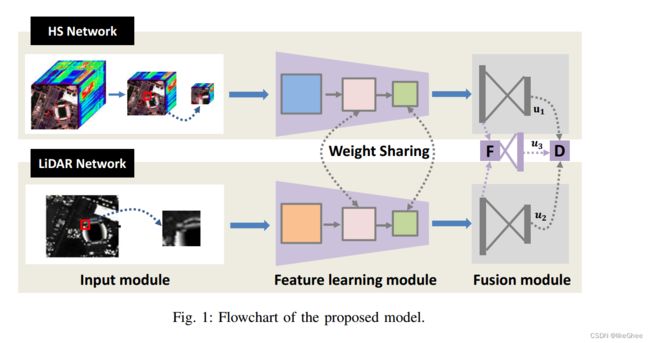
该模型包括三个主要模块:输入模块、特征学习模块和融合模块。
输入模块:接收高光谱图像X和激光雷达数据Z作为输入。
特征学习模块:包含两个分支网络,一个是HS网络(用于提取高光谱图像特征),另一个是LiDAR网络(用于提取激光雷达数据特征)。这两个网络共享参数以减少参数数量。每个分支网络包括卷积层、批归一化层、ReLU激活函数和最大池化操作。
融合模块:有三个分类器,分别对应于三种不同的融合策略:连接(concatenation)、求和(summation)和最大值(maximization)。这些分类器的输出进一步被送入一个输出层进行最终决策。
输出层:根据不同融合策略,输出层的构造方式也不同

coupled CNNs:每个分支网络包括卷积层、批归一化层、ReLU激活函数和最大池化操作。

Structure of the fusion module:
该模块有三个分类器,对应三种不同的融合策略:连接(concatenation)、求和(summation)和最大值(maximization)。
融合过程: O = D [ f 1 ( R h ; W 1 ) , f 2 ( R l ; W 2 ) , f 3 ( F ( R h , R l ) ; W 3 ) ; U ] \mathbf{O}=D[f_1(\mathbf{R}_h;\mathbf{W}_1),f_2(\mathbf{R}_l;\mathbf{W}_2),f_3(F(\mathbf{R}_h,\mathbf{R}_l);\mathbf{W}_3);\mathbf{U}] O=D[f1(Rh;W1),f2(Rl;W2),f3(F(Rh,Rl);W3);U]
O表示融合模块的最终输出,D和F分别为决策级和特征级融合, U对应于D的聚变权值。
对于特征级融合F,除了广泛使用的串联方法外,我们还使用了求和和最大化方法。求和融合的目的是计算两种表示的和: F ( R h , R l ) = R h + R l F(\mathbf{R}_h,\mathbf{R}_l)=\mathbf{R}_h+\mathbf{R}_l F(Rh,Rl)=Rh+Rl
类似地,最大化融合的目的是执行一个元素的最大化: F ( R h , R l ) = m a x ( R h , R l ) F(\mathbf{R}_h,\mathbf{R}_l)=max(\mathbf{R}_h,\mathbf{R}_l) F(Rh,Rl)=max(Rh,Rl)
还增加了两个输出层f1和f2来监督它们的学习过程。在输出阶段,它们还可以帮助做出决策。f1的输出值可推导为: y ^ 1 = f 1 ( R h ; W 1 ) = s o f t m a x ( W 1 R h ) \hat{\mathbf{y}}_1=f_1(\mathbf{R}_h;\mathbf{W}_1)=softmax(\mathbf{W}_1\mathbf{R}_h) y^1=f1(Rh;W1)=softmax(W1Rh)
与上式类似,我们也可以分别推导出f2和f3的输出值y^2和y^3。对于决策级融合D,我们采用加权求和方法: O = D ( y ^ 1 , y ^ 2 , y ^ 3 ; U ) = u 1 ⊙ y ^ 1 + u 2 ⊙ y ^ 2 + u 3 ⊙ y ^ 3 \mathbf{O}=D(\hat{\mathbf{y}}_1,\hat{\mathbf{y}}_2,\hat{\mathbf{y}}_3;\mathbf{U})=\mathbf{u}_1\odot\hat{\mathbf{y}}_1+\mathbf{u}_2\odot\hat{\mathbf{y}}_2+\mathbf{u}_3\odot\hat{\mathbf{y}}_3 O=D(y^1,y^2,y^3;U)=u1⊙y^1+u2⊙y^2+u3⊙y^3