java回顾:redis基础、jedis使用、jedis连接池工具类
目录
一、NoSQL非关系型数据库
1.1、简介
1.2、 非关系型数据库分类
1.3、使用
二、Redis的value数据类型(重点)
2.1、value的数据类型_string
2.2、value的数据类型_hash
2.4、value的数据类型_set
2.5、value的数据类型_zset/sorted set
三、 Redis的其他操作(掌握)
四、Redis持久化机制
4.1、RDB持久化机制
4.1.1 rdb持久化机制默认满足的条件:
4.1.2 修改该文件中内容满足rdb持久化机制的条件 :
4.2、AOF的持久化机制
4.3、 AOF重写机制介绍
4.3.1介绍
4.3.2 AOF重写触发的方式
4.4、Redis持久化机制RDB和AOF的区别
五、使用Jedis操作操作redis【重点】
5.1、Jedis的使用
5.1.1 依赖
5.1.2 Jedis构造方法
5.1.3 Jedis方法
5.1.4 测试
5.2、Jedis连接池
5.2.1 Jedis连接池使用
5.2.2 jedis连接池的配置
5.2.3 Jedis连接池工具类
一、NoSQL非关系型数据库
1.1、简介
之前学习的mysql属于关系型数据库。表与表之间具有关系:1对一 一对多 多对多。
关系型数据库弊端:
- 磁盘IO次数影响效率
- 数据之间具有关系,操作的时候降低效率
NoSQL非关系型数据库:存储的数据之间没有关系。NoSQL (not only sql),在非关系型数据库中不使用之前学习的sql语句。属于一个新的语法。
缺点:
- 学习成本高。
- 数据存储在内存中,数据容易丢失。
优点:
- 查询快,效率高,数据位于内存中,在内存中交互比磁盘交互快。
- 数据之间没有关系,操作方便,提高效率
1.2、 非关系型数据库分类
- key-value:存储数据以键值对形式进行存储,类似于我们之前学习的map集合。redis就属于这种。
- 文档类型:在key-value形式上进行升级,一个键对应多个值,值是文档。效率比redis更快。MongoDB
- 列存储数据库:Hbase.
- 图形(Graph)数据库
1.3、使用
启动 redis-server.exe,redis的默认端口号是6379.
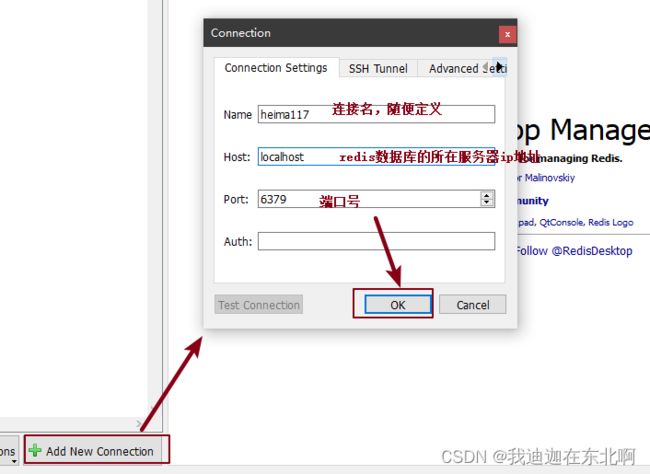
可视化工具连接
二、Redis的value数据类型(重点)
redis数据库存储数据的格式是:key-value键值对形式,key是固定的字符串。而value具有多种数据类型,value常见有五种数据类型:
string hash list set zset(sorted set)
2.1、value的数据类型_string
| 命令 | 功能 |
|---|---|
| set 键 值 | 添加或修改一个键和值,键不存在就是添加,存在就是修改 |
| get 键 | 获取值,如果存在就返回值,不存在返回nil(就是C语言中NULL) |
| del 键 | 删除指定的键和值,返回删除的个数 |
补充:批量操作:
mset 键 值 键 值 。。。
mget 键 键 键。。。
del 键 键
测例:
打开控制台


小结:
| 命令 | 描述 |
|---|---|
| set key value | 不存再key就是添加,如果存在key就是修改value |
| get key | 根据key获取value |
| del key1 key2 key3 ... | 根据键删除键值整体,返回删除的键值对个数 |
| mset key1 value1 key2 value2 ... | 批量添加 |
| mget key1 key2 ... | 根据键批量获取value |
2.2、value的数据类型_hash
value是hash数据类型适合存储对象数据,例如下面的person是对象名,value是hash类型,hash类型中存储键值对形式

| 命令 | 描述 |
|---|---|
| hset key 字段 值 | 添加数据 |
| hget key 字段 | 根据键和字段获取值 |
| hdel key 字段1 字段2 。。。 | 根据键和字段删除数据 |
| hmset key 字段 值 字段 值 。。。 | 批量添加数据 |
| hmget key 字段 字段 。。。。 | 批量获取数据 |
| hgetall key | 获取所有的字段和值 |
创建hash类型为aotuman,进行操作

2.3、value的数据类型_list
特点:
- 存取有序
- 数据可以重复
- 可以在list底层的数据结构两侧进行添加和删除数据

| 命令 | 描述 |
|---|---|
| rpush 键 值1 值2 。。 | 从列表右侧添加数据 right |
| lpush 键 值1 值2 。。 | 从列表左侧添加数据 left |
| lpop 键 | 从列表左侧删除第一个数据并返回 |
| rpop 键 | 从列表右侧删除第一个数据并返回 |
| lrange 键 起始索引 结束索引 | 从列表中获取指定索引对应的值 list |
| lindex 键 索引 | 获取指定索引对应的值 |
| llen 键 | 获取list集合长度 |
测例:对myList操作

说明:list类型数据可以重复,存取有序。
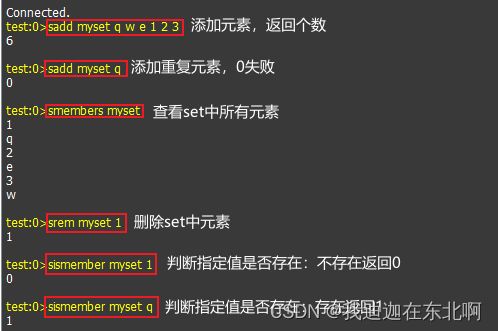
2.4、value的数据类型_set
特点:无序、唯一
| 命令 | 描述 |
|---|---|
| sadd 键 值 值。。。 | 向set集合添加数据 |
| srem 键 值 | 删除值 |
| smembers 键 | 查看所有值 |
| sismember 键 值 | 判断这指定的值是否存在于set中:存在返回1 不存在返回0 |
测例:对mySet操作
2.5、value的数据类型_zset/sorted set
redis中的value类型是zset类型,正是通过分数来为集合中的成员进行从小到大的排序。
| 命令 | 行为 |
|---|---|
| zadd 键 分数 值 分数 值 | 添加1个或多个元素,每个元素都有一个分数 |
| zrange 键 开始索引 结束索引 | 获取指定范围的元素,得到所有的元素,索引是0到-1 |
| zrange 键 开始索引 结束索引 withscores | 查询指定的元素和对应的分数 |
| zrevrange 键 开始索引 结束索引 withscores | 按照分数倒叙获取指定的元素和对应的分数 reverse |
| zrem 键 值 值 | 删除一个或多个值 |
| zcard 键 | 得到元素个数 |
| zrank 键 值 | 得到元素的索引号 |
| zscore 键 值 | 得到元素的分数 |
测例:添加键toy有序集合(sorted set)


三、 Redis的其他操作(掌握)
| 命令 | 功能 |
|---|---|
| keys 匹配字符 | 查询所有的键,可以使用通配符 * 匹配多个字符 ? 匹配1个字符 |
| del 键1 键2 | 删除任何的值类型,而且可以同时删除多个键 |
| exists 键 | 判断指定的键是否存在 |
| type 键 | 判断指定的键,值的类型。返回是类型的名字 |
| select 数据库编号 | 选择其它的数据库 |
| move 键 数据库编号 | 将当前数据库中指定的键移动到另一个数据库中 |

四、Redis持久化机制
redis持久化包括两种:
- RDB持久化机制:称为快照方式。默认的持久化方式。每隔一段时间持久化一次。
- AOF持久化机制:是将操作redis的命令存放到一个文件中。AOF简称:append only file.下次启动redis服务器的时候直接将aof持久化机制的文件中命令在执行一遍将数据存储到redis中,即加载内存中。
4.1、RDB持久化机制
RDB持久化机制:称为快照方式。默认的持久化方式。每隔一段时间持久化一次。
4.1.1 rdb持久化机制默认满足的条件:
| 关键字 | 时间(秒) | 修改键数 | 解释 |
|---|---|---|---|
| save | 900 | 1 | 到了15分钟修改了1个键,则发起快照保存 |
| save | 300 | 10 | 到了5分钟修改了10个键,则发起快照保存 |
| save | 60 | 10000 | 到了1分钟,修改了1万个键,则发起快照保存 |
可以对上述默认条件进行修改,找到redis安装目录中的配置文件:redis.windows.conf。
启动redis服务器的时候就不能直接双击,在dos窗口中执行命令: redis-server.exe 配置文件的副本
4.1.2 修改该文件中内容满足rdb持久化机制的条件 :
在10秒的时候修改3个键就执行rdb持久化机制,将修改的键和值长久保存到rdb持久化文件中。然后下次启动的时候数据依然存在。

启动redis服务器加载配置文件副本

4.2、AOF的持久化机制
AOF持久化机制:是将操作redis的命令存放到一个文件中。AOF简称:append only file.下次启动redis服务器的时候直接将aof持久化机制的文件中命令在执行一遍将数据存储到redis中,即加载内存中。
存储命令的文件是:appendonly.aof。

| REDIS中提供了3种同步策略 | 说明 |
|---|---|
| 每秒同步 | 每过一秒中记录一次 |
| 每修改同步 | 每次修改(增删改)都会记录一次 |
| 不同步 | 不记录任何操作 |
aof持久化机制默认是关闭的,我们需要在配置文件redis.windows.conf中进行开启:

修改策略:
| 关键字 | 持久化时机 | 解释 |
|---|---|---|
| appendfsync | everysec | 每秒记录 |
| appendfsync | always | 每修改记录 |
| appendfsync | no | 不记录 |
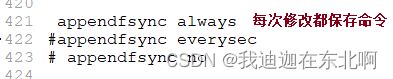
测试:
*2
$6
SELECT
$1
0
*3
$3
set
$4
name
$8
zhangsan
*3
$3
set
$3
age
$2
18
说明:
【1】
*2 :表示有两个命令执行了:SELECT 0
*3 :表示有三个命令执行:set name zhangsan
*3 :表示有三个命令执行:set age 18
说明:*x : x表示执行的命令个数
【2】
$6:表示该命令含有6个字符SELECT
$1:表示该命令只有一个字符 0
$3:表示该命令只有3个字符 set
$4:表示该命令只有4个字符 name
说明:$x:表示命令的字符个数
关闭服务器,重新启动redis服务器就会将该文件中的所有命令执行,将数据加载到redis中
4.3、 AOF重写机制介绍
4.3.1介绍
只要执行一个命令,那么就会将命令写到aof文件中,那么如果有重复的命令也会写到aof文件中,这样会导致aof文件中命令的冗余,在重新启动redis服务器的时候会导致效率很低。
不使用aof和使用aof重写机制对比:

说明:Incr命令表示将 key 中储存的数字值增一
小结:aof重写机制就是对aof文件的命令进行优化,减少命令的冗余和重复,这样可以减少文件的大小,以及在启动redis服务器加载文件aof文件时,提高效率。
4.3.2 AOF重写触发的方式
1.手动触发:用户通过调用bgrewriteaof命令手动触发。
在客户端输入命令:
![]()
2. 自动触发
修改配置文件redis.conf的如下内容: 
AOF重写目的减少aof持久化生成的文件中的冗余的命令,这样可以减少磁盘空间,主要是提高服务器读写数据的效率。
4.4、Redis持久化机制RDB和AOF的区别
RDB持久化机制:
优点:方便备份和恢复,文件都是数据,单个文件。 启动性能高。
缺点:不能完全保证数据的安全性,高并发访问会造成服务器卡顿,多个子线程操作资源。
AOF持久化机制:
优点:保证数据的绝对安全
缺点:文件过大,在redis服务器中生成比较多个文件,加载文件比较慢。我们使用aof重写机制尽量用户aof持久化机制生成的文件。
五、使用Jedis操作操作redis【重点】
redis官网: Redis
5.1、Jedis的使用
5.1.1 依赖
redis.clients
jedis
2.7.0
jar
compile
5.1.2 Jedis构造方法
Jedis(host, port)
参数:
host:表示连接redis服务器的ip地址
port:redis服务器的端口号
5.1.3 Jedis方法
【1】操作string
| 对STRING操作的方法 | 说明 |
|---|---|
| set(String key,String value) | 添加字符串类型的键和值 |
| String get(String key) | 通过键得到字符串的值 |
| del(String ... keys) | 删除一个或多个键 |
【2】操作hash
| 对HASH操作的方法 | 说明 |
|---|---|
| hset(String key,String field,String value) | 添加一个hash类型的键,字段和值 |
| Map |
通过一个键得到所有的字段和值,返回Map |
【3】操作list
| 对LIST操作的方法 | 说明 |
|---|---|
| lpush(String key,String...values) | 从左边添加多个值到list中 |
| List |
通过键得到指定范围的元素 |
【4】操作set
| 对SET操作的方法 | 说明 |
|---|---|
| sadd(String key,String...values) | 添加一个或多个元素 |
| Set |
通过键得到集合所有的元素 |
【5】操作zset
| 对ZSET操作的方法 | 说明 |
|---|---|
| zadd(String key, double score, String member) | 添加一个键,分数和值 |
| Set |
查询一个指定范围的元素 |
【6】关闭连接
| 方法名 | 说明 |
|---|---|
| close | 关闭连接 |
5.1.4 测试
使用Jedis上面的方法来访问Redis,向服务器中写入字符串、hash和list类型,并且取出打印到控制台上。
public class D1_Jedis {
//1.创建Jedis核心类对象 public Jedis(String host, int port)
private static final Jedis jedis = new Jedis("localhost",6379);
//list
@Test
public void t3() {
//2.向服务器中写入list
//赋值单个
jedis.rpush("list","woody","buzz","andi");
//获取值,一次可获取多个
List list = jedis.lrange("list", 0, -1);
System.out.println("list = " + list);
//3.关闭连接
jedis.close();
}
//hash
@Test
public void t2() {
//2.向服务器中写入hash
//赋值单个
jedis.hset("toy","name","woody");
Map map = new HashMap<>();
map.put("friend","buzz");
map.put("age","18");
//赋值多个
jedis.hmset("toy",map);
//获取值,一次可获取多个
List hmget = jedis.hmget("toy", "name", "age");
System.out.println("hmget = " + hmget);
//3.关闭连接
jedis.close();
}
//字符串
@Test
public void t1() {
//2.向服务器中写入字符串
jedis.set("name","迪迦");
System.out.println(jedis.get("name"));
//3.关闭连接
jedis.close();
}
} 5.2、Jedis连接池
5.2.1 Jedis连接池使用
介绍

jedis数据库连接池是用来优化获取jedis连接的,有了连接池之后每次都是从连接池中获取连接,使用完之后在将连接还
jedis连接池的api:
| JEDISPOOLCONFIG配置类 | 功能说明 |
|---|---|
| JedisPoolConfig() | 创建一个配置对象 |
| void setMaxTotal() | 设置连接池的最大连接数 |
| void setMaxWaitMillis() | 设置最长等待时间 |
| JEDISPOOL连接池类 | 说明 |
|---|---|
| JedisPool(配置对象,服务器名,端口号) | 创建一个连接池,参数: 1. 上面的配置对象 2. 服务器名 3. 端口号 |
| Jedis getResource() | 从连接池中得到一个连接对象Jedis |
给连接池。提高开发的效率和性能。
测例:使用连接池优化jedis操作,从连接池中得到一个创建好的Jeids对象,并且使用这个Jedis对象。从Redis数据库中获取key是name的value值,打印到控制台
public static void main(String[] args) {
//2.创建Jedis连接池的配置类对象 JedisPoolConfig配置类
JedisPoolConfig config = new JedisPoolConfig();
//3.创建Jedis连接池对象 JedisPool连接池类
JedisPool pool = new JedisPool(config, "localhost", 6379);
//4.使用连接池对象调用方法Jedis getResource()获取连接对象
Jedis jedis = pool.getResource();
//5.使用Jedis对象调用方法获取key是username的value值
String name = jedis.get("name");
//6.输出value
System.out.println("name = " + name);
//7.将连接放到连接池中
jedis.close();
}5.2.2 jedis连接池的配置
//jedis连接池的配置
@Test
public void t2() {
try {
//2.创建Jedis连接池的配置类对象 JedisPoolConfig配置类
JedisPoolConfig config = new JedisPoolConfig();
//修改连接池中的最大连接
config.setMaxTotal(10);
/*
设置等待最长时间:如果超过了等待的最长时间就报异常
*/
config.setMaxWaitMillis(5000);
/*
设置最大空闲,在实际开发中一般将连接池中的最大连接数:
maxTotal和最大空闲连接数:maxIdle的值设置为一致
*/
config.setMaxIdle(10);
//3.创建Jedis连接池对象 JedisPool连接池类
JedisPool pool = new JedisPool(config, "localhost", 6379);
//循环
for (int i = 0; i < 12; i++) {
//获取连接,因为大于10个连接,第11个连接超时后异常
Jedis jedis = pool.getResource();
System.out.println("jedis = " + jedis);
// jedis.close()不要释放资源才可以查看不同的连接对象
}
} catch (Exception e) {
//输出log日志,同时可以提示给用户即浏览器客户端
System.out.println("异常耐心等待....");
}
}1.配置方法:
1.setMaxTotal(int n);设置连接池的最大连接数量
2.setMaxWaitMillis(long time);设置等待获取连接的最长时间,单位是毫秒
3.setMaxIdle(int n);设置连接池的连接的最大空闲数量2.设置最大空闲连接数量:一般建议设置最大空闲连接数量和最大连接数一致。
3.MaxTotal:连接池中存放最多的连接数量 100
MaxIdle:连接池中存放最多空闲连接的数量,就是当前连接池中可使用的连接数量。 50
假设此时有70人访问,那么由于连接池最大空闲数量是50,还需要在连接池中在重新创建20个连接对象,就是调用系统资源创建20个连接放到连接池。降低性能
5.2.3 Jedis连接池工具类
public class JedisPoolUtil {
//定义连接池对象
private static JedisPool pool;
//1.定义静态代码块:类加载就执行,即读取配置文件
static {
//读取配置文件
//1)创建读取properties文件的类对象
//参数jedis表示配置文件jedis.properties的文件名
ResourceBundle bundle = ResourceBundle.getBundle("jedis");
//2)使用对象bundle调用方法根据key获取配置文件的value
String maxTotal = bundle.getString("jedis.maxTotal");
String maxWaitMillis = bundle.getString("jedis.maxWaitMillis");
String maxIdle = bundle.getString("jedis.maxIdle");
String host = bundle.getString("jedis.host");
String port = bundle.getString("jedis.port");
//2.创建Jedis连接池的配置类对象 JedisPoolConfig配置类
JedisPoolConfig config = new JedisPoolConfig();
//修改连接池中的最大连接
// config.setMaxTotal(10);
config.setMaxTotal(Integer.parseInt(maxTotal));
/*
设置等待最长时间:如果超过了等待的最长时间就报异常
*/
// config.setMaxWaitMillis(3000);
config.setMaxWaitMillis(Long.parseLong(maxWaitMillis));
/*
设置最大空闲,在实际开发中我们一般将连接池中的最大连接数:maxTotal和最大空闲连接数:maxIdle的值设置为一致
*/
// config.setMaxIdle(10);
config.setMaxIdle(Integer.parseInt(maxIdle));
//3.创建Jedis连接池对象 JedisPool连接池类
// pool = new JedisPool(config, "localhost", 6379);
pool = new JedisPool(config, host, Integer.parseInt(port));
}
//2.定义静态方法让外界获取Jedis连接对象
public static Jedis getJedis() {
Jedis jedis = null;
if (pool != null) {
//从连接池中获取Jedis对象
jedis = pool.getResource();
}
//返回对象
return jedis;
}
//3.定义静态方法让外界获取连接池对象
public static JedisPool getJedisPool(){
return pool;
}
//4.在工程中定义配置文件
}配置文件:
#连接池中的最大连接
jedis.maxTotal=10
#连接池中的最大等待时间
jedis.maxWaitMillis=3000
#连接池中的最大空闲的连接
jedis.maxIdle=10
#redis的服务器地址
jedis.host=localhost
#redis的服务器端口号
jedis.port=6379测试工具类:
@Test
public void t1() {
Jedis jedis = null;
try {
for (int i = 0; i < 12; i++) {
jedis = JedisPoolUtil.getJedis();
System.out.println("jedis = " + jedis);
}
} catch (Exception e) {
//如获取连接数量超过定义值,进入等待,等待超时后会异常
System.out.println("异常耐心等待....");
}
//5.使用Jedis对象调用方法获取key是username的value值
String name = jedis.get("name");
//6.输出value
System.out.println("name = " + name);
//7.将连接放到连接池中
jedis.close();
}