SQL进阶 | 自连接
概述
SQL的自连接是指在一个SQL表中,使用自身表格中的实例进行联接并查询的操作。自连接通常使用别名来标识一个表格,在自连接中,表格被视为两个不同的表格,并分别用不同的别名来标识。然后,在WHERE子句中使用这些别名,将它们连接起来,以创建一种与自身关联的视图。
组合
假设这里有一张存放了商品名称及价格的表,表里有“苹果、橘子、香蕉”这 3 条记录。

针对不同的需求,有不同的组合结果:
排列A(n,k)
查询出所有的组合结果,有序集合。
select p1.name as name_1, p2.name as name_2
from products p1, products p2;
组合C(n,k)
查询出所有的组合结果,有相同元素的只查出一条。无序集合。
select p1.name as name_1, p2.name as name_2
from products p1, products p2
where p1.name > p2.name; 
使用等号“=”以外的比较运算符,如“<、>、<>”进行的连接称为“非等值连接”。这里将非等值连接与自连接结合使用了,因此称为“非等值自连接”。
查找局部不一致的列
还是这张商品表,要查找出价格相同,名称不同的组合。

使用非等值连接实现。
select distinct p1.name,p1.price
from products p1,products p2
where p1.name <> p2.name and p1.price = p2.price 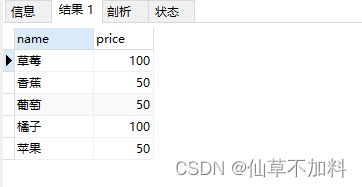
排序
现在,我们要按照价格从高到低的顺序,对下面这张表里的商品进行排序。我们让价格相同的商品位次也一样,而紧接着它们的商品则有两种排序方法,一种是跳过之后的位次,另一种是不跳过之后的位次。

使用窗口函数实现。
select name,price,
rank() over(order by price desc) as rank_1,
dense_rank() over(order by price desc) as rank_2
from products;RANK函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。也就是说,如果有多个记录的分数相同,那么这些记录的排名将会一样,并且下一个排名将会跳过这些排名相同的记录。
DENSE_RANK函数也返回一个唯一的值,但当碰到相同数据时,所有相同数据的排名都是一样的。与RANK函数不同的是,DENSE_RANK函数在下一个排名中会继续紧随这些排名相同的行,而不会跳过。也就是说,如果有多个记录的分数相同,那么这些记录的排名将会一样,并且下一个排名将会紧随在它们后面。
总的来说,RANK和DENSE_RANK都是用于排名的函数,但它们的策略略有不同。RANK函数在遇到相同数据时会产生间断的排名,而DENSE_RANK函数则会产生连续的排名。

使用非等值自连接实现。
select p1.name,p1.price,
( select count(p2.price)
from products p2
where p2.price > p1.price ) + 1 as rank_1
from products p1
order by rank_1在子查询中,统计出价格比自己高的记录的条数并将其作为自己的位次,由于一定会存在价格最高的商品没有比自己高的记录,所以位次会从0开始统计,在子查询的结果中+1能更明显的展示出排名。

外连接和内连接
外连接(Outer Join)可以分为左外连接(Left Outer Join)、右外连接(Right Outer Join)和全外连接(Full Outer Join)。左外连接返回包括左表中的所有记录和右表中连接字段相等的记录,右外连接返回包括右表中的所有记录和左表中连接字段相等的记录,全外连接返回左右表中所有的记录和左右表中连接字段相等的记录。
内连接(Inner Join)是一种常见的连接方式,它只返回两个表中连接字段相等的行。内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。
还是上面那个例子,使用外连接来实现。
select p1.name,max(p1.price) as price,
count(p2.name) + 1 as rank_1
from products p1 left join products p2 on p1.price < p2.price
group by p1.name
order by rank_1通过左外连接,与价格大于自己的商品进行连接,按照商品名称p1进行分组,统计商品名称p2的记录条数,最终结果和上面相同。
使用内连接实现。
select p1.name,max(p1.price) as price,
count(p2.name) + 1 as rank_1
from products p1 inner join products p2 on p1.price < p2.price
group by p1.name
order by rank_1
通过查询出的条件,可以发现,不存在排名为1的价格为100的橘子商品,这是因为内连接只会查找出p1.price < p2.price的记录,找不到比橘子价格还高的商品,它就被排除掉了。
总结
- 自连接经常和非等值连接结合起来使用。
- 自连接和 GROUP BY 结合使用可以生成递归集合。
- 将自连接看作不同表之间的连接更容易理解。
- 应把表看作行的集合,用面向集合的方法来思考。
- 自连接的性能开销更大,应尽量给用于连接的列建立索引。
练习题
1.请使用表products,求出两列可重组合。

代码如下:
select p1.name as name_1,p2.name as name_2
from products p1,products p2
where p1.name <= p2.name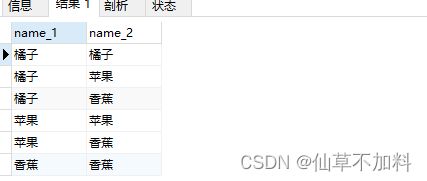
2. 这里准备了下面这样增加了“地区”列的新表 DistrictProducts,请计算一下各个地区商品价格的位次。
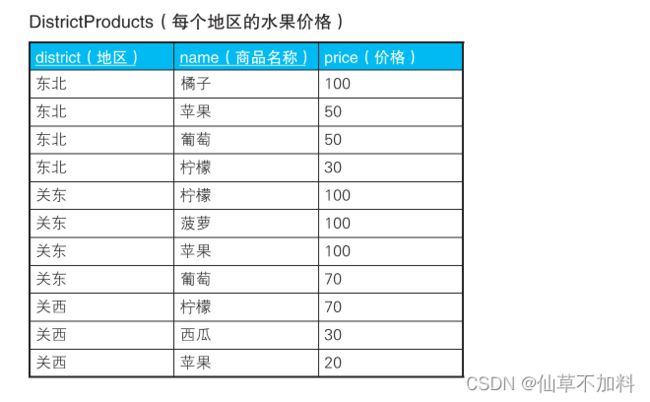
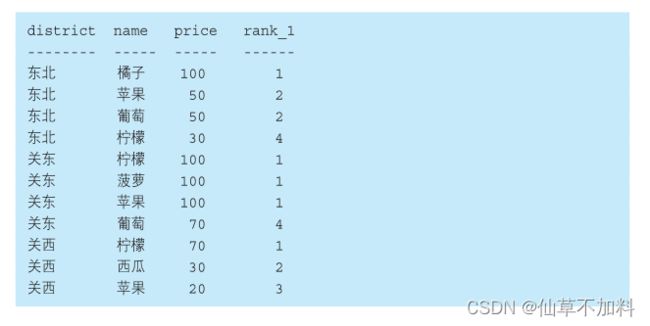
代码如下:
select d1.district,d1.name,d1.price,count(d2.name)+1 as rank_1
from districtproducts d1 left join districtproducts d2
on d1.price < d2.price and d1.district = d2.district
group by district,name,price
order by district,rank_1 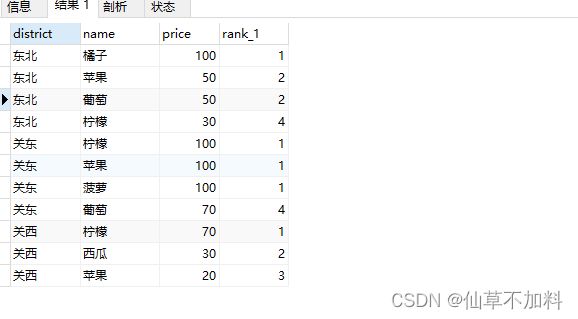
3.假设有下面这样一张表DistrictProducts2,里边原本就包含了“位次”列。不过,“位次”列的初始值都是 NULL。往这个列里写入位次。
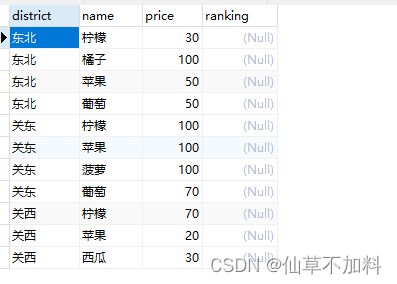
代码如下:
update districtproducts2 p1
set ranking = (select rank_1 from
(select count(p2.price) +1 rank_1
from districtproducts2 p2
where p1.district = p2.district and p2.price > p1.price) p3)
需要注意的是如果是下列代码,会报错。
UPDATE DistrictProducts2 P1
SET ranking = (SELECT COUNT(P2.price) + 1
FROM DistrictProducts2 P2
WHERE P1.district = P2.district
AND P2.price > P1.price);报错信息:
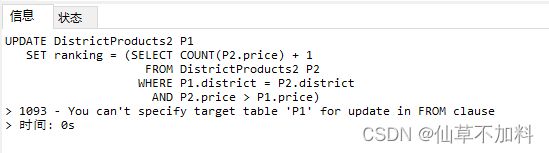
意思是不能先select出同一表中的某些值,再update这个表(在同一语句中)。 所以使用一张临时表来解决问题。
扩展
使用PARTITION BY子句
PARTITION BY子句用于在窗口函数中对结果集进行分区,以便在每个分区中进行独立的计算。PARTITION BY子句通常与ORDER BY子句一起使用,以便将数据按照指定的列进行排序,并将排序后的数据划分为多个分区。
PARTITION BY子句可以将数据按照指定的列进行分组,并在每个分区中进行独立的计算。它通常与窗口函数一起使用,以便在每个分区中计算聚合函数(如SUM、AVG、MAX等)的值。
UPDATE DistrictProducts2
SET ranking =
(SELECT P1.ranking
FROM (SELECT district , name ,
RANK() OVER(PARTITION BY district
ORDER BY price DESC) AS ranking
FROM DistrictProducts2) P1
WHERE P1.district = DistrictProducts2.district
AND P1.name = DistrictProducts2.name);PARTITION BY 子句将数据按照district进行分组,并在每个分区中按照price列进行降序排序,并结合RANK函数生成排名。