向量自回归
VAR向量自回归模型
一、外生变量和内生变量
内生变量
- 内生变量是具有某种概率分布的随机变量,它的参数是联立方程系统估计的元素,是由模型系统决定的,同时也对模型系统产生影响。
- 内生变量–般都是明确经济意义变量。
- 一般情况下,内生变量与随机项相关,即
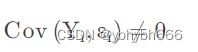
- 在联立方程模型中,内生变量既作为被解释变量,又可以在不同的方程中作为解释变量。
外生变量
- 外生变量一般是确定性变量,或者是具有临界概率分布的随机变量,其参数不是模型系统研究的元素。
- 外生变量影响系统,但本身不受系统的影响。
- 外生变量一般是经济变量、政策变量、虚拟变量。
- 一般情况下,外生变量与随机项不相关。
内生变量:又叫非政策性变量、因变量,是指在经济机制内部由纯粹的经济因素所决定的变量,不为政策所左右。内生变量是“一种理论内所要解释的变量”,是由模型决定的。 例:P=a+bQ,表示价格与数量的关系,则a、b是参数,都是外生变量;P、Q是模型要决定的变量,所以是内生变量。除此之外,譬如相关商品的价格,人们的收入等其他于模型有关的变量,都是外生变量。
外生变量:又称政策性变量,是指在经济机制中受外部因素主要是政策因素影响,而由非经济体系内部因素所决定的变量。这种变量通常能够由政策控制,并以之作为政府实现其政策目标的变量。 从广义上讲,任何一个系统(或模型)中都存在许多变量,其中自变量和因变量统称为内生变量,而作为给定条件存在的变量则称为外生变量。意指不受自变量影响,而受外部条件支配的变量。外生变量一般是确定性变量,或者是具有临界概率分布的随机变量,其参数不是模型系统研究的元素。外生变量影响系统,但本身不受系统的影响。外生变量一般是经济变量、条件变量、政策变量、虚变量。一般情况下,外生变量与随机项不相关。
从经济学的角度上解释可以是
内生变量指经济体系以内的经济力量所决定的一种变量,也称经济变量。例如,在研究经济活动时,工资支付、消费、储蓄、投资、利润和就业一般被看成是内生变量。外生变量指由经济体系以外的非经济因素所决定的变量,也称为非经济变量。例如,在研究经济活动时,出口统计数字、气候、地震、政治形势等等通常被看成外生变量。外生变量的变化数值不是经济学家的研究所能掌握的
外生变量可以影响内生变量
二、VAR模型概念
向量自回归模型,简称VAR模型,是AR 模型的推广,是一种常用的计量经济模型。在一定的条件下,多元MA和ARMA模型也可转化成VAR模型。
VAR模型是用模型中所有当期变量对所有变量的若干滞后变量进行回归。
VAR模型常用于预测相互联系的时间序列系统以及分析随机扰动对变量系统的动态影响,主要应用于宏观经济学。是处理多个相关经济指标的分析与预测中最容易操作的模型之一。
由于向量自回归模型把每个内生变量作为系统中所有内生变量滞后值的函数来构造模型,从而避开了结构建模方法中需要对系统每个内生变量关于所有内生变量滞后值的建模问题。
VAR模型结构
非限制性向量自回归模型的一般表达式如下:
模型的基本形式是弱平稳过程的自回归表达式,描述的是在同一样本期间内的若干变量可以作为它们过去值的线性函数。
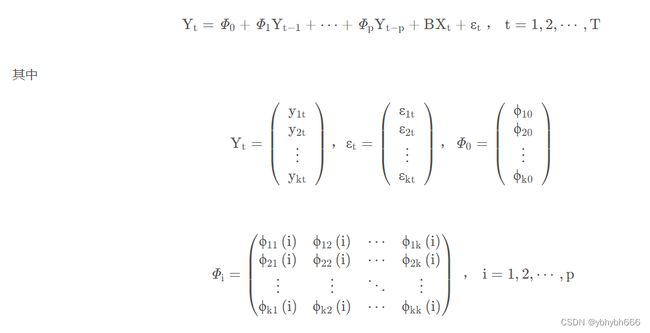

比如 1 维 p 阶 向量自回归模型
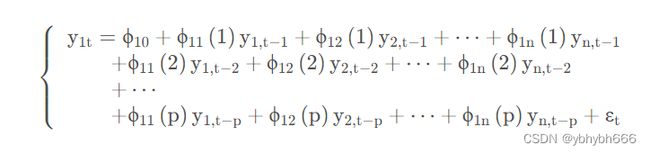
不含常数项或线性趋势项的向量自回归模型表达式为:

VAR模型特点
- 不以严格的经济理论为依据。在建模过程中只需明确两件事:①共有哪些变量是相互有关系的,把有关系的变量包括在VAR模型中;②确定滞后期 p。使模型能反映出变量间相互影响的绝大部分。
- VAR模型对参数不施加零约束。(对无显着性的参数估计值并不从模型中剔除,不分析回归参数的经济意义。)
- VAR模型的解释变量中不包括任何当期变量,所有与联立方程模型有关的问题在VAR模型中都不存在(主要是参数估计量的非一致性问题)。
- VAR模型的另一个特点是有相当多的参数需要估计。比如一个VAR模型含有三个变量,最大滞后期 p=3,则有27个参数需要估计。当样本容量较小时,多数参数的估计量误差较大。
- 无约束VAR模型的应用之一是预测。由于在VAR模型中每个方程的右侧都不含有当期变量,这种模型用于样本外一期预测的优点是不必对解释变量在预测期内的取值做任何预测。
- 用VAR模型做样本外近期预测非常准确。做样本外长期预测时,则只能预测出变动的趋势,而对短期波动预测不理想。
三、模型的定阶
滞后阶数检验需要考虑两个问题
1.如果滞后阶数 p 比较小,那么随机误差项会出现自相关的问题;
2.在实际应用中,通常希望滞后阶数 p 足够大,进而能够更好的体现所构造的模型的动态特征,但是如果滞后阶数 p 过大时,那么模型所需要估计的参数就越多,将存在自由度太小的问题,如果没有足够多的样本数量,就会造成所需要估计参数不能有效的计算出来。
有两种方法可以做滞后阶数检验:
- 分析各种准则,最后确定滞后阶数,AIC准则、SC准则、HQ准则、LogL准则、最终预测误差(FPE);
- 分析似然比(LR),这种方法不会出现第一种方法的无效结果。
第一种方法被学者们用的最多。.第一种方法中的五个指标在各个阶数的估计值,选取五个检验准则最小值数量最多的阶数即为模型的滞后期数。
例如

四、模型的系数估计
对于向量自回归模型系统中的每一个方程都可以采用OLS(最小二乘估计)方法进行估计,同时估计量具有一致性和无偏性。
一个 k 维 p 阶向量自回归模型中,各方程中所有解释变量的滞后期是相同的,都为滞后 p 期,因此共估计得到 p*k^2+k个系数
五、单位根检验
时间序列平稳性是一组数列的统计值与时间无关,不会随时间推移而变化,它通常是以因果关系为基础的数学模型的假设条件。
如果时间序列yi是一组平稳序列,那么通过计算其均值E(yi)不会随着时间的变化而变化,var(yi)也不受时间的影响
反之,其均值和方差都会受时间的影响
在VAR模型中,必须保证时间序列稳定。如果不能保证时间序列稳定,那么会导致两种结果:
- 第一,向量自回归系数的估计值是负数,做完 t 检验后,得到的结果是无效的;
- 第二,两个独立变量的相关关系或者回归关系是假的,使得模型的结果无效。
(1)DF 检验
DF 检验只适用于一阶自回归过程的平稳性检验

由于现实生活中绝大多数序列都是非平稳序列,所以单位根检验的原假设定为:

(2)ADF 检验
因为 DF 检验只适用于1阶自回归过程的平稳性检验,但实际上绝大多数时间序列都不会是一个简单的AR(1)过程。为了使DF检验能适用于AR( p )过程的平稳性检验,对其进行了一定的修正,得到增广DF检验(augmented Dickey-Fuller),简记为ADF检验。





通过蒙特卡洛方法,可以得到r检验统计量的临界值表,显然DF检验是ADF检验在自相关阶数为1时的一个特例,所以统称为ADF检验
六、格兰杰因果检验
在有些情况下,时间序列分析也会出现伪相关问题,也就是可以计算出较大的相关系数的变量实际上并不相关。
针对此问题,格兰杰因果检验由此而生。格兰杰因果检验用于检验时间序列之间是否存在相关关系,它是能否建立脉冲函数的前提。
在VAR模型中,格兰杰检验的因果关系不是通常所说的因果关系(并非真正汉语意义上的“因果关系”),而是说先发生的事情对后发生的事情有–定的影响,或者说某个变量是否可以用来提高对其他相关变量的预测能力。所以,“格兰杰因果关系的实质是一-种“预测”关系
其实质是考量一个变量的滞后量能否加入到其他变量的公式中。当一个变量确实受到其他变量的滞后量影响时,可以称这两个变量具有格兰杰因果关系。
格兰杰因果检采取以下方式验证是否是真正的相关关系:
(1)估计当前的Y值被Y本身滞后期取值所能解释的程度;
(2)检验加入X的滞后期后,Y的被解释程度是否提高;
(3)如果满足条件(2),则X是Y的格兰杰成因,此时X的滞后期系数具有统计显著性
格兰杰因果关系检验经常被解释为在VAR模型中,某个变量是否可以用来提高对其他相关变量的预测能力。在考虑x是否能引起y的问题时,主要看y能够在多大程度上被过去的 x 解释,加入 x 的滞后值是否使解释程度提高。如果 x 在 y 的预测中有帮助,就可以说“ y 是由 x Granger引起的”。
具体是通过在向量自回归模型系统中考察序列滞后项的系数是否全为零来进行检验。以一个2维p阶平稳向量自回归模型为例

由于格兰杰因果关系检验是在向量自回归模型的基础上进行的,因此向量自回归模型本身的合理性对格兰杰因果关系检验的结果也是非常重要的。例如,向量自回归模型本身应当具有恰当的滞后期。
七、脉冲响应分析
在VAR模型中,脉冲响应分析的作用是可以分析某个变量对另一个变量的影响时间和幅度。研究当扰动项发生变化时,对整个模型系统产生的影响,用来描述一个变量的变动怎样影响模型其他所有的变量。
如果时间序列是稳定的,虽然前几期受到外部冲击的影响,该变量会处于一个变化的状态,但经过一段时间,最终会处于-一个平稳的状态。
由于向量自回归模型表达式中所需要估计的参数非常多,并且一个系数只能反应局部关系。
也就是,VAR模型中的各个等式中的系数并不是研究者最终关注的对象,对模型表达式中的系数的研究意义并不大。但是如果考虑一个扰动项变动,或者受到一个干扰或冲击,各个变量之间的动态关系,也就是系统的动态反应,是具有–定意义的。
脉冲响应函数
在参数估计量的评价标准中,一般包含无偏性、有效性、相合性和一致性,而VAR模型参数的普通最小二乘法估计量只具有–致性,因此要解释复杂的经济问题,单个参数估计值是很难完成的。
一个有效的对VAR模型进行分析的方法就是脉冲响应函数。
脉冲响应函数研究的是随机干扰项遭受冲击后内生变量的反应,用来描述对随机干扰项施加一一个冲击后对内生变量的当期值和未来值造成的影响。
在实际的应用中,由于VAR模型是一种非理论性的模型,因此在对VAR模型的分析中,很少研究一个变量的变化对另-一个变量的影响,而是专注于当一个随机误差项变化时(对随机误差项施加冲击),对系统的动态影响。
八、方差分解
在VAR模型中,得到了某个变量对另一个变量的解释度后,能够分析出该变量的重要性。变量会产生一些随机误差项,这些随机误差项都包含着重要的信息,方差分解的结果能够把这些信息全部说明出来。方差分解的作用非常大,这个过程的作用是能够分析某个变量对另一个变量的解释度。
如果说脉冲响应函数是来描述数学模型中的任一内生变量的正交冲击对其他变量造成的影响,那么方差分解就是分析各个内生变量的正交冲击对目标内生变量冲击的贡献比例,进而判断分析各个变量的重要性。
建模步骤
1)画N个因子的序列相关图,计算相关系数 correlation coiffiant,查看一下线性相关度。(相关系数大小只反映线性相关程度,不反应非线性相关,如果等于0,不能排除存在非线性相关的可能。)
2)对N个因子的原始数据进行平稳性检验,也就是ADF检验。
VAR模型要求所有因子数据同阶协整,也就是N个因子里面如果有一个因子数据不平稳,就要全体做差分,一直到平稳为止。
3)对应变量(yt)和影响因子(Xt)做协整检验
一般就是EG协整关系检验了,为了看看Y和各个因子Xi之间是否存在长期平稳的关系,这个检验要放在所有数据都通过ADF检验以后才可以做。如果那个因子通不过协整检验,那基本就要剔除了。
4)然后就是通过AIC,BIC,以及LR定阶。
一般来说是综合判断三者。AIC,BIC要最小的,比如-10的AIC就优于-1AIC,LR反之要最大的。但是具体偏重那个,就看个人偏好,一般来说,博主的经验是看AIC和LR,因为BIC的惩罚力度大于AIC,大多数时间不太好用。
具体的实现步骤一般是,把滞后项的阶数列一个范围,比如1-5,然后直接建模,其他啥都不看,先看AIC,BIC,LR的值。一般符合条件的不会只有一个,可以挑2-3个最好的,继续进行。
5)定阶完成后,就是估计参数,看参数的显著性。
好的模型所有参数的要通过显著性检验。
6)对参数进行稳定性检验
VAR除了对原始数据要进行平稳处理,估计出来的参数还需要检验参数稳定性。
这是为了查看模型在拟合时,数据样本有没有发生结构性变化。
有两张检验方法,这两种方法的基本概念是:
第一个是:AR根,VAR模型特征方程根的绝对值的倒数要在单位圆里面。
第二个是:cusum检验,模型残差累积和在一个区间内波动,不超出区间。
这里要注意的是CUSUM检验的原价设(H0):系数平稳,备择假设才是不平稳。所以CUSUM结果要无法拒绝原假设才算通过。
只有通过参数稳定性检验的模型才具有预测能力,进行脉冲响应和方法分解分析才有意义。
7)使用乔里斯基正交化残差进行脉冲响应分析
举例:要分析和预测的是Y,影响Y的有两个因子X1,X2。
脉冲响应是1对1,根据以上条件,就要做两个脉冲响应分析,分别是:Y和X1,Y和X2。
看看不同因子上升或者下降,对Y的冲击的程度和方式(Y上升还是下降),以及持续时间。
8)使用乔里斯基正交化残差进行方差分解分析
举例:要分析和预测的是Y,影响Y的有两个因子X1,X2。
方差分解是1对1,根据以上条件,就要做两个方差分解分析,分别是:Y和X1,Y和X2