论文阅读:PointCLIP V2: Prompting CLIP and GPT for Powerful3D Open-world Learning
https://arxiv.org/abs/2211.11682
0 Abstract
大规模的预训练模型在视觉和语言任务的开放世界中都表现出了良好的表现。然而,它们在三维点云上的传输能力仍然有限,仅局限于分类任务。在本文中,我们首先协作CLIP和GPT成为一个统一的3D开放世界学习器,命名为PointCLIP V2,它充分释放了它们在零弹3D分类、分割和检测方面的潜力。为了更好地将3D数据与预先训练的语言知识对齐,PointCLIP V2包含两个关键设计。对于视觉效果,我们通过形状投影模块提示CLIP生成更真实的深度图,缩小投影点云与自然图像之间的区域差距。对于文本的结尾,我们提示GPT模型生成特定于3d的文本,作为CLIP文本编码器的输入。在没有任何3D领域训练的情况下,该方法在3个数据集上的零点3D分类正确率显著高于PointCLIP,分别为+42.90%、+40.44%和+28.75%。此外,V2可以以简单的方式扩展到少镜头3D分类、零镜头3D零件分割、3D物体检测,展示了我们在统一的3D开放世界学习中的泛化能力。代码可以在https://github.com/ yangyang127/PointCLIP_V2获得。
1. Introduction
近年来,空间传感器的发展引起了学术界和工业界的广泛关注。为了有效地理解点云这一3D中的主要数据形式,许多相关的任务被提出并取得了很大的进展,包括3D分类[35,51,66],分割[36,54,48,52],检测[55,29],以及自监督学习[65,17,61,11]。重要的是,由于开放世界环境的复杂性和多样性,收集到的3D数据通常包含大量“看不见”的对象,也就是说,已经部署的3D系统从未定义和训练过这些对象。在人工数据标注的情况下,如何识别这些新类别的3D形状成为一个有待深入研究的热点问题。
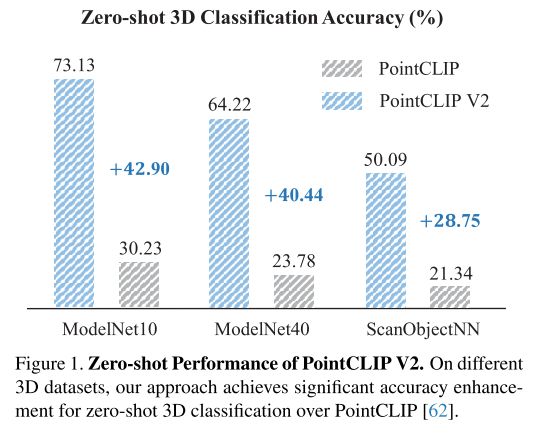
最近,大规模的预先训练的视觉和语言模型,如CLIP[37]和GPT-3[3],已经获得了在两种模式下处理数据的强大能力。然而,其在点云上的应用还很有限,现有的工作只是探讨了CLIP在3D分类任务中的可能性,而没有考虑其他3D开放世界任务。PointCLIP[62]首次表明,CLIP可以适应于零弹点云分类,无需任何3D训练。它将“看不见的”3D点云稀疏地投射到2D深度图中,并利用CLIP的图像-文本对齐来识别深度图。然而,作为一项前期工作,PointCLIP的性能远不能令人满意,如图1所示,无法投入实际使用。更重要的是,PointCLIP只从预训练的CLIP中获得支持,而没有考虑强大的大规模语言模型(LLM)。因此,我们提出了一个问题:我们是否可以适当地将CLIP和LLM统一起来,以充分释放它们统一3D开放世界理解的潜力?

我们观察到PointCLIP在2D-3D域间隙方面主要受到两个因素的影响。(1)稀疏投影。PointCLIP简单地将3D点云作为稀疏分布的点投影到深度图上(图2)。虽然简单,但散点风格的图形在外观和语义上都与现实世界的前训练图像有很大的不同,这严重地混淆了CLIP的视觉编码器。(2)朴素文本。PointCLIP主要继承CLIP的2D文本输入,“一个[CLASS]的照片。,并且只添加了简单的3d相关词汇“深度图”。如图3所示,CLIP提取的文本特征很难集中在相似度得分较高的目标对象上。这种朴素的文本不能完全描述3D形状,并损害了预先训练的语言-图像对齐。

在本文中,我们整合了CLIP和GPT-3[3]模型的优势,提出了PointCLIP V2,一个强大的框架,用于统一的3D开放世界理解,包括零镜头/少镜头3D分类,零镜头部分分割,以及零镜头3D对象检测。在不“看到”任何3D训练数据的情况下,V2可以将点云投射到逼真的2D图形中,并将它们与3D感知文本对齐,这充分释放了CLIP在3D领域中预先训练的知识。
首先,我们提出了带有Prompt CLIP with Realistic Projection,它从三维点云生成剪辑首选图像。具体来说,我们将不规则点云转化为基于网格的体素,然后在其上应用非参数的三维局部滤波。通过这种方法,投影的3D形状由密集的点和平滑的深度值组成。如图2所示,我们生成的图形在视觉上更类似于真实世界的3D点云。具体来说,我们将不规则点云转化为基于网格的体素,然后在其上应用非参数的三维局部滤波。通过这种方法,投影的3D形状由密集的点和平滑的深度值组成。如图2所示,我们生成的图形在视觉上更接近真实世界的图像,可以高度释放CLIP预先训练的视觉编码器的表示能力。其次,我们用3D命令提示GPT生成具有丰富3D语义的文本,作为CLIP文本编码器的输入。通过将启发式的面向3d的命令输入到GPT-3中,例如,“Give a caption of a table depth map:”,我们利用其语言生成知识来获取一系列特定于3d的文本,例如,“A height map of a table with a top and several legs”。定制了一组语言命令,以提示GPT-3生成带有3D形状信息的各种文本。如图3所示,PointCLIP V2的文本特征对投影的地图具有更强的匹配属性,极大地增强了CLIP对3D点云的图像-文本对齐。
在我们的提示方案中,PointCLIP V2在ModelNet10[53]、ModelNet40[53]和ScanObjectNN[44]数据集上表现出了卓越的零击3D分类性能,分别比PointCLIP提高了+42.90%、+40.44%和+28.75%的准确率。此外,我们的方法可以通过边缘修改来适应更重要的3D开放世界任务,例如可学习的3D平滑用于3D少拍分类,反投影头部用于零拍分割,以及用于零拍检测的3D区域提议网络。这充分表明了V2对于一般3D开放世界理解的威力。
•我们提出了PointCLIP V2,这是一种功能强大的跨模态学习者,将CLIP和GPT-3结合起来,将预先训练好的视觉语言知识转化为3D领域。
•我们引入了逼真的投影到提示剪辑和面向3D的命令提示GPT-3,以有效地缓解2D、3D和语言之间的领域差距。
•作为第一个统一3D开放世界学习的工作,我们的PointCLIP V2可以进一步扩展为零镜头部分分割和3D对象检测。
2. Related Works
3D开放世界学习。传统的三维开放世界学习方法仍然需要三维训练数据作为前训练阶段。Cheraghian等人的一系列工作通过最大化潜在空间中的类间分歧来训练“可见”3D类别的零射击分类器,然后对“未可见”类别进行测试[6,8,7]。最近的一些作品[30,24,32,27]也研究了开放世界语义分割和更复杂的3D场景的3D对象检测。PointCLIP[62]受到基于clip的自适应方法的启发[60,13,23],无需对三维数据集进行任何训练即可实现零拍点云识别。通过传递预训练的CLIP模型[37],可以有效地利用二维知识对三维数据进行识别。CLIP2Point[19]通过额外的3D预训练进一步提高了CLIP在点云上的自适应性能。在本文中,我们提出PointCLIP V2,并遵循PointCLIP的开放世界设置,与图4相比,这比以前的方法更具挑战性。我们不需要‘seen’3D训练,首次同时进行零拍3D局部分割和目标检测,实现统一的3D开放世界理解。
点云的投影。与基于点的方法并行[35,36,28],基于投影的点云分析旨在通过将点云投影到2D图像中,利用丰富的2D网络进行3D域分析[42,41,58,47,50,1]。其中PointCLIP[62]跟随SimpleView[14]进行了3d - 2d投影的透视变换,效率高但分类精度有限。在3D开放世界设置下,我们有动力开发更有效和现实的投影方法,以提示在点云数据上的CLIP。在表1中,我们将我们的方法与现有的先进投影方法在延迟和准确性方面进行了比较。为了进行公平的比较,我们在我们V2的流水线下实现了所有之前的工作,也就是说,使用我们的GPT提示方法来充分展示它们的有效性。如图所示,我们的现实投影显示出比其他方法更快的推理速度,并获得比PointCLIP更高的零拍性能。
视觉上的快速学习。提示工程首先源自自然语言处理,其中生成一个文本模板,称为提示,以缩小训练前的前文本任务和下游场景之间的领域差距[25,22,46,22]。受此启发,CoOp[69]首先将可学习提示引入二维视觉语言分类中,随后的CoOp[68]将其扩展到二维领域概化。CuPL[34]和CaFo[63]利用GPT-3[3]来增强CLIP在各种2D数据集上的下游性能。从另一个角度来看,视觉提示方法提出在输入图像上附加可学习的视觉像素[21,2,5,12]或嵌入[21,16,64],并在不进行下游微调的情况下改善预先训练的视觉骨干。在本文中,我们寻求用现实投影提示CLIP的视觉编码器和用GPT-3提示文本编码器,以提高其零镜头预测。
GPT-3模型。生成式预训练转换器(GPT)模型[38,39,3]在处理自然语言方面已经取得了进步。其中,GPT-3的语言理解能力和语言生成能力较前几代GPT-3具有显著的优势[38,39,26,56,40]。GPT-3是一个包含1750亿个可训练参数的大规模自回归语言模型。虽然不是开源的,但一些研究已经探索了它在下游任务中的应用,如用于视觉回答问题的PICa[57],用于2D零镜头识别的CuPL[34],以及用于2D少镜头学习的CaFo[63]。在本工作中,我们首次通过3D相关命令提示GPT-3[3]来推进开放世界的3D任务。
3. Methods

PointCLIP V2的总体框架如图7所示。从CLIP[37]继承,我们的框架由两个预先训练的视觉和文本编码器组成。为了弥补模式差异,我们引入了从3D到深度地图的逼真投影(3.1节),以及gpt生成的特定于3D的文本(3.2节),以将深度地图与语言对齐。PointCLIP V2还可以扩展到各种3D任务,实现统一的3D开放世界学习(第3.3节)。
3.1. Prompting CLIP with Realistic Projection
为了从CLIP的3D数据中生成更真实的2D输入,同时实现时间效率,我们通过四个步骤将3D点云投影到深度图中:量化、致密化、平滑和挤压,如图5所示。

量化。对于不同的M个要投影的视图,我们分别创建一个零初始化的3D网格G∈RH×W×D,其中H,W,D表示其空间分辨率,D表示垂直于视图平面的深度维度。以一个视图为例,我们将输入点云的3D坐标归一化为[0,1],并通过将点p = (x, y, z)投影到网格中的体素中
![]()
其中体素被赋予不同的深度值,s∈(0,1)表示一个比例因子来调整投影形状的大小。对于投射到同一体素中的多个点,我们只需指定最小深度值。这是因为从目标图像平面上看,深度值z较小的点会遮挡较大的点。然后,我们得到一个包含稀疏深度值的3D网格G,由于点云的稀疏性,大部分体素为空。
致密化。为了解决这种不真实的散射问题,我们通过局部极小值池化操作对网格进行致密化,以保证视觉的连续性。我们通过局部空间窗口内的最小体素值来重新分配G中的每个体素。同样,相对于均值和最大池化,保留最小深度值符合投影地图上被遮挡的视觉外观。这样,稀疏点之间的原始空体素可以被合理的深度值有效填充,而背景体素仍然是空的,从而得到密集而立体的空间形状表示。
平滑。由于局部池化操作可能在某些三维曲面上引入伪影,我们采用非参数高斯核进行形状平滑和噪声滤波。在适当的核大小和方差的条件下,该滤波方法既能去除因密度增大而产生的空间噪声,又能保持原三维形状中棱角的锐度。通过这一点,我们获得了一个更紧凑和光滑的形状,由3D网格表示。
挤压。作为最后一步,我们简单地挤压G的深度维度,得到投影的深度图V∈RH×W。我们提取每个深度通道的最小值作为每个像素位置的值,并重复三次作为RGB强度。我们的基于网格的投影可以简单地通过沿着G的深度通道的最小池化来实现,对硬件实现更友好。
(最后还是投影到二维,直接投影到二维然后深度补全与这种的方式区别大吗)
3.2. Prompting GPT with 3D Command
为了更好地激活CLIP的文本编码器以匹配我们的深度图,我们的目标是利用带有类别形状特征的特定3d描述作为CLIP的文本输入,而不是使用一般的“[CLASS]的照片:”。考虑到LLMs强大的描述能力,我们利用GPT-3[3]为CLIP文本编码器生成具有足够3D语义的3D特定文本,如图6所示。通常,GPT-3接收语言命令并通过预先训练的知识输出响应。为了使GPT-3完全适应3D领域,我们提出了以下四个系列的启发式命令:
标题生成。给定一个描述性的命令,GPT-3为目标投影的3D形状合成一般的标题,例如,输入:“描述一个[窗口]的深度图:”;GPT-3:“它将窗口描绘成一个黑色的窗格。”
回答问题。GPT-3对3d相关的问题产生描述性的答案,例如,输入:“如何描述一个[桌子]的深度图?”;GPT3:“(桌子)可能有一个长方形或圆形的平顶和桌腿。”
释义生成。对于深度图的描述,GPT-3期望生成一个同义的句子。例如,输入:“生成该句子的同义词:倾斜的[床]的灰度深度图”;GPT-3:“斜(床)的单色深度图。”
单词到句子。GPT3以一组关键词为基础,将其组织成一个完整的句子,并增加与形状相关的附加内容,如:输入:“用a [table], depth map, smooth.”;GPT-3:“这张平滑的深度地图在角落里显示了一张桌子。”形容词“smooth”在这里描述的是由平滑操作引起的自然外观。
(通过gpt3生成更好的提示)
对于K类别的3D数据集,我们将K个类别名放在每个命令的“[CLASS]”位置,并将它们输入GPT-3, GPT-3生成具有丰富的类别语义的特定于3D的描述。最后,我们整合每个类别的描述,并将它们作为CLIP文本编码器的输入。
3.3. Unified Open-world Learning
通过引入逼真的投影和特定于3D的文本,PointCLIP V2展示了强大的泛化能力,可以适应不同的3D开放世界任务。
3D零拍分类。对于视觉分支中的所有M个视图,我们将投影深度图{Vi}M i=1输入CLIP的视觉编码器,并获得多视图特征{fi}M i=1,其中fi∈R1×C。对于文本分支,我们利用CLIP的文本编码器提取类别特征Wt∈RK×C,作为零镜头分类权值。然后将{fi}M i=1与Wt之间的多视图对齐进行聚合,计算出最终的零镜头分类logits,公式为

其中,αi表示衡量视图i重要性的超参数。

3D少射击分类。给定一小组3D训练数据,我们可以将我们对真实形状投影的平滑操作修改为可学习的,如图5所示。其中,由于不规则点云已转化为基于网格的体素,我们采用了高斯滤波后的两个三维卷积层。这些可学习的模块可以从少镜头数据集中总结出三维几何知识,并进一步调整三维形状,使其更适合clip。在训练过程中,我们冻结了CLIP的两个编码器,以保存预先训练的知识,并避免在小规模的少镜头数据上过度拟合。
3D零拍局部分割。除了形状分类,我们还为我们的框架提出了一个零镜头分割管道,它也可以用于现有的PointCLIP。我们没有采用全局特征![]() ,而是采用CLIP的可视编码器从{Vi}M i=1中提取密集特征
,而是采用CLIP的可视编码器从{Vi}M i=1中提取密集特征![]() ,其中
,其中![]() 。具体来说,我们在视觉编码器最终的池化操作之前输出特征图,并将特征上采样到原始深度图大小。对于我们的3d特定文本,我们利用GPT-3生成不同部件类别的描述。例如,对于对象“[CLASS]”中的部件类别“[part]”,我们构造命令为“在深度图中描述[CLASS]的[part]部分:”。然后,对于视图i,我们将每个像素与文本特征Wt进行密集对齐,即在多视图深度图上分割形状的不同部分,表示为
。具体来说,我们在视觉编码器最终的池化操作之前输出特征图,并将特征上采样到原始深度图大小。对于我们的3d特定文本,我们利用GPT-3生成不同部件类别的描述。例如,对于对象“[CLASS]”中的部件类别“[part]”,我们构造命令为“在深度图中描述[CLASS]的[part]部分:”。然后,对于视图i,我们将每个像素与文本特征Wt进行密集对齐,即在多视图深度图上分割形状的不同部分,表示为

logitsi中的每个元素表示像素级分类logit。在此之后,我们根据2D-3D对应关系将不同视图的logit反向投影到3D空间中。由于遮挡,一个视图只能描述一个局部点云,因此我们对每个点在不同视图中的预测进行平均,从而获得3D空间中的最终部分分割logit。通过几何背投影,可以在三维的分割任务,以一种零镜头的方式处理。
零镜头三维物体检测。对于3D对象检测,我们遵循2D开放世界检测的设置[15,67],将我们的V2装备为预先训练的区域建议网络(RPN)之上的零镜头分类头。我们首先利用3DETR[31]作为3D RPN来生成与类无关的3D框候选。然后,我们提取每个3D盒子中的原始点,并将它们输入V2进行零拍分类。通过这种方式,基于v2的3DETR可以以零拍的方式探测“看不见的”物体。
4. Experiments
在本节中,我们首先演示PointCLIP V2的详细网络配置,然后展示我们在不同3D任务上的开放世界性能。
4.1. Implementation Details
剪辑提示。我们按照PointCLIP[62]将点云投影到10个视图的纵深图中。我们设网格G的大小为H×W×D = 112 × 112 × 8,将投影深度图上采样到224 × 224。点云放置在网格的中心,为获得更好的视觉效果,将比例因子s设置为0.7。用于致密化的最小pooling的窗口大小为(6,6,2)。高斯滤波器的kernel大小设为(3,3,1)。我们随机采样1024个点作为输入,采用Vision Transformer[10],默认patch大小为16×16,记为vi - b /16。
GPT提示。我们设计了50个不同的3D语言命令,其中13个用于生成标题,13个用于回答问题,12个用于释义,12个用于逐字逐句。每个命令触发GPT-3生成20个特定于3d的描述,我们最终为每种命令类型获得大约250个描述,为一个类别总共获得1000个描述。我们使用“text-davinci002”GPT-3引擎,并将温度常数设置为0.7。3d特定描述的最大长度设置为40。对于文本编码器,采用12层转换器[45]对生成的文本进行编码。
4.2. Zero-shot Classification
设置。零镜头分类性能是在三个广泛使用的基准上进行评估的:ModelNet10[53]、ModelNet40[53]和ScanObjectNN[44]。我们研究了ScanObjectNN数据集的三部分:OBJ ONLY、OBJ BG和PB T50 RS。遵循零射击原则,我们直接在完整的测试集上测试分类性能,而不需要从训练集学习。我们在最佳设置下比较现有的方法。具体来说,我们的模型和CLIP2Point[19]都采用了vi - b /16。对于PointCLIP,我们在ModelNet10、ModelNet40和ScanObjectNN数据集上分别使用了ResNet101[18]、ResNet-50×4[37]和vi - b /16,充分实现了其最佳性能。
主要结果。在表2中,我们比较了零镜头分类与现有方法的性能。一些模型需要对3D点云数据集进行额外的预训练。CLIP2Point在ShapeNet数据集[4]上训练深度地图编码器,然后将其用于3D零拍分类任务。Cheraghian等人的[7]直接使用3D编码器提取点云特征。他们对数据集中的“见过的”类别进行抽样,以对模型进行预训练,并对“未见过的”类别进行验证。相反,PointCLIP和我们的V2放弃了任何3D训练,可以直接在3D数据集上进行测试。对于所有三个基准,我们的方法比现有的作品有显著的优势。V2在ModelNet10和Model Net40上的准确率分别为73.13%和64.22%,比PointCLIP高出+42.90%和+40.44%。V2在ScanObjectNN数据集的PB T50 RS分割上也达到了35.36%,证明了我们在嘈杂的现实场景下的有效性。
消融研究。在表4中,我们对PointCLIP V2进行了一项关于真实投影模块的四个步骤的消融研究。通过正交投影将点云直接投影到二维图像中,零拍精度达到57.35%,降低了−6.87%。如果采用量化步骤,致密化平滑操作可使零拍性能分别提高+15.14%和+5.7%,说明这两步的重要性。我们还比较了密度化步骤的替代池操作,包括最大池、最小池和平均池。我们观察到最小的池化实现了最好的性能,这与现实世界中的遮挡效应是一致的。在表5中,我们展示了GPT提示模块中四种命令类型的效果。在不同的命令组合下,零射性能有不同程度的提高。如果同时使用这四种类型,3d文本的零拍性能提高了+25.11%,说明了更好的语言-图像对齐的重要性。

4.3. Few-shot Classification
设置。我们在ModelNet40[53]和ScanObjectNN[44]数据集上测试k-shot分类性能,其中k∈{1,2,4,8,16}。我们采用与零拍任务相同的3d特定文本作为文本输入,联合训练可学习平滑(图5)和访问视图适配器[62]。3D卷积层采用5 × 5 × 3的核大小,然后是批量归一化[20]和ReLU非线性激活[33]。
主要结果。在图8中,我们展示了V2的少shot分类结果,并与PointCLIP和其他四个具有代表性的3D网络PointNet[35]、PointNet++[36]、SimpleView[14]和CurveNet[54]进行比较。从图中可以看出,通过少拍训练,V2的表现优于其他所有方法,并且在单拍分类上有更显著的改进。V2在ModelNet40上超过PointCLIP的1次射击精度+12%,在ScanObjectNN上+7%。此外,我们的方法在ModelNet40数据集上实现了89.55%的16镜头精度,甚至接近完全监督的PointNet[35]。
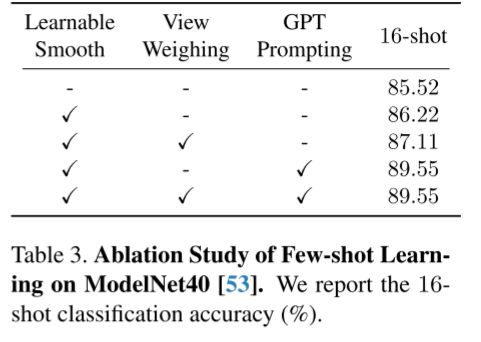
消融研究。在表3中,我们报告了不同模块对少镜头V2和16镜头结果的影响,包括可学习的平滑,PointCLIP之后的视图权重,以及来自GPT提示的3d特定文本。我们发现,可学习的3D投影模块比固定的模块提高了16次射击的正确率+0.7%,采用3D特定文本提高了正确率+3.33%。
4.4. Zero-shot Part Segmentation
设置。我们在ShapeNetPart数据集[59]上评估零镜头分割性能,该数据集包括16个类别和50个标注部件。按照之前的方法[36,48,28],我们从每个点云中抽取2048个点,并对官方测试分割进行测试。为了比较,我们通过我们建议的零镜头分割管道实现PointCLIP,并报告最佳性能的结果。
主要结果。我们在表6中显示了跨实例(mIoUI)的联合得分的平均交集。我们的方法在总体mIoUI上比PointCLIP高出了+17.4%,并且在不同的对象类别上表现得更好。我们还在图9中可视化了分割结果,这进一步证明了我们以零镜头方式捕获细粒度3D模式的有效性。

4.5. Zero-shot 3D Object Detection.
设置。使用ScanNet V2数据集[9]评估检测性能,该数据集包含18个对象类别。我们采用预训练的3DETR-m[31]模型作为区域提案网络,在每个3D框内提取1024个点。我们报告了在两个不同的IoU阈值0.25和0.5(标记为AP25和AP50)下,使用平均平均精度(mAP)在验证集上的零射击检测性能。此外,PointCLIP是通过我们的努力实现的零镜头3D检测,我们报告了表现最好的结果。
主要结果。表7显示了我们与PointCLIP的零拍3D检测结果。我们观察到PointCLIP V2达到了mAP25和mAP50的18.97%和11.53%,比PointCLIP分别高出了+12.97%和+6.77%。这证明了V2在现实世界场景中识别3D开放世界对象的能力更强,为通用的3D开放世界学习提供了巨大的潜力。
4.6. Other Experiments
计算负担。我们在表1中比较了推理的潜伏期。此外,我们比较了表8中的PointCLIP[62]和CLIP2Point[19]的计算复杂度。我们在1台RTX A6000上测试了每个推理的计算开销。从表中可以看出,V2导致了与PointCLIP类似的开销,并在ModelNet40上实现了优越的零拍精度。因此,我们实现了一个更好的精度-效率的权衡。
更多的消融。在表9和10中,我们还研究了影响零拍分类性能的2个因素:视觉编码器主干和采样点数。1)不同的脊梁。在表9中,我们检查了在ModelNet40[53]和ScanObjectNN[44]数据集上使用不同骨干的结果。我们观察到,默认的vi - b /16主干网获得了最好的整体性能。2)抽样点率。表10给出了不同采样点数的影响。请注意,官方发布的ModelNet40数据集每个点云只有2048个点,因此我们采用了[49]的重采样版本的ModelNet40,每个点云包含8192个点。当增加点的采样率时,我们观察到改进。
5. Conclusion
我们提出了PointCLIP V2,一个强大的、统一的3D开放世界学习器,它大大超越了现有的PointCLIP。我们建议使用逼真的投影模块来提示CLIP,以便从3D中生成高质量的深度图,并提示GPT-3模型生成特定于3D的描述。通过提示,视觉和语言表示实现了更好的对齐。除了分类外,V2还可以泛化到各种具有挑战性的任务,并具有良好的性能,包括3D少镜头分类、3D零镜头部分分割和物体检测。在未来的工作中,我们将进一步探索如何使CLIP适应更广泛的开放世界应用,例如户外3D检测和视觉接地。
自己总结:
1、比上一篇工作提升巨大,同时增加分割内容
2、深度图稠密应该比较合理,毕竟最后模仿RGB
3、文字特征提取更加有效
代码阅读疑问:在zeroshot_seg任务中,首先存储特征
torch.save(feat_store, os.path.join(save_path, "{}_features.pt".format(mode)))
torch.Size([14, 10, 512, 14, 14])14 is batch,10 is num of views, 512, is channel of feature dim, and image width is 14*14
test_feat = test_feat.reshape(-1, 10, 196, 512)为什么可以直接reshape不需要把512这个维度放在最后吗
test_feat = test_feat.permute(0,1,3,4,2)
test_feat = test_feat.reshape(-1, 10, 196, 512)