检测和减轻灰色故障
关键字: [Amazon Web Services re:Invent 2023, Gray Failures, Differential Observability, Health Checks, Outlier Detection, Availability Zone Evacuation]
本文字数: 1100, 阅读完需: 6 分钟
视频
如视频不能正常播放,请前往bilibili观看本视频。>> https://www.bilibili.com/video/BV1Nc411D7rG
导读
灰色故障可以逃避快速和明确的检测,同时影响在云端运行的工作负载。构建能够经受单实例和单可用区灰色故障的弹性应用程序需要您实现特定的可观察性和缓解策略。在本论坛中,学习什么是灰色故障,以及它们如何在云端显示。探索检测功能,例如 Amazon CloudWatch Contributor Insights、复合报警和离群值检测,以帮助您发现灰色故障。了解如何使用 ELB 健康检查、Amazon EC2 自动缩放、心跳表模式和 Amazon Route 53 Application Recovery Controller zonal shift 等工具,减轻这些故障的影响。
演讲精华
以下是小编为您整理的本次演讲的精华,共800字,阅读时间大约是4分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
亚马逊云科技的高级首席解决方案架构师Mike Hagen在他的演讲中,首先介绍了灰色故障的概念。他指出,灰色故障是由于差异观察性导致的,即从不同角度感知系统的健康状况可能会有所不同。尽管底层组件可能没有检测到任何问题,但最终用户可能会对他们的服务体验到重大影响。因此,客户不能仅依赖系统本身来检测和解决故障,而是需要构建自己的可观察性和缓解机制。
灰色故障通常发生在故障隔离边界处,如亚马逊云科技区域、可用区(AZ)、实例和软件组件或模块。例如,Hagen描述了一个有缺陷的EC2实例如何导致整体服务可用性下降2%的情况,展示了单个主机灰色故障的场景。系统的浅层健康检查(如负载均衡器ping)可能表明实例健康状况良好。然而,由于内存、CPU或软件冲突等问题,它可能无法处理客户的请求。
Hagen解释了如何通过验证依赖项的深度健康检查来绕过灰色故障,而不会终止实例。但是,这种方法有可能隐藏真实的软件错误或硬件故障,因为不健康的主机经常被自动化替换。此外,如果深度健康检查导致一系列实例替换,下游依赖的临时错误可能会使剩余的健康主机不堪重负。
总之,深度和浅层检查都不是绝对正确或错误的。浅层检查与自动扩展相结合,允许不良实例被无缝替换。深层检查能够在不替换实例的情况下绕过故障。然而,仍然需要其他机制来评估实例健康状况或检测灰色故障。
为了识别单主机灰色故障,Hagen强调需要对内部业务逻辑进行彻底的仪器化和可观察性。这包括捕捉关键指标,如响应代码、延迟和故障隔离边界的维度。他强调了亚马逊云科技的CloudWatch Embedded Metric Format作为将应用程序指标和日志组合在一个流中的方法。
云监控的贡献者洞察功能可以帮助我们对比不同实例之间的错误率,从而找出可能导致灰色失败的异常实例。通过在最大贡献者值上设置警报,我们可以识别出那些导致过多错误的单个实例。最简单的方法就是替换受影响的实例,同时在执行过程中要谨慎地控制速度,以避免大规模终止。
哈根随后探讨了检测单个可用区灰色失败模式的方法。这可能表现为某个可用区受到的影响显著高于其他可用区,或者在某个可用区中出现仅在该区明显的问题信号,也可能是因为共享资源失败而导致跨可用区的大范围影响。
通过使用异常检测方法,我们可以找到出错较多的那个可用区。云监控的复合警报可以在其他可用区正常而只有一个可用区出现问题时发出警报。在共享资源(如数据库)上设置的警报可以指示多个可用区受到影响。
结合可用区特定的可用性和延迟警报以及排除单个实例异常的贡献者洞察规则,我们可以准确地识别出孤立的可用区问题。可用区失败的潜在缓解策略包括等待问题自行解决,将流量转移到其他区域,或者进行故障切换到另一个地区。然而,哈根指出,故障切换可能会存在数据不一致的问题,而且执行时间会更长。
为了有效地疏散一个可用区,我们的架构必须是可用区独立的,并保持处理本地化。这包括禁用跨可用区负载均衡和配置每个可用区的读副本。
恢复过程应该尽量依赖于数据面而非控制面,因为前者通常更简单且更可靠。例如,应用程序恢复可以通过使用数据面API来切换到另一个可用区来实现。
通过使用一个集中的API,多个团队可以协同工作,将Route 53的健康检查失败转向相关的负载均衡器,从而疏散一个可用区。
对于像自动扩展群组这样的资源,哈根还介绍了如何编写脚本更新配置,以便从受影响的可用区中删除子网,并记录这些更改,以便在未来实现恢复。
总的来说,灰色故障在系统和最终用户之间的可观察性存在差异。为了应对不确定性,客户需要培养自己的可观察性和解决问题的能力,以便检测和解决问题。运用丰富的维度指标来界定故障隔离边界至关重要。已验证的方法包括异常检测、组合报警以及尽量利用数据平面而非控制平面。哈根提供了一些亚马逊云科技的相关资料,供进一步学习这些灰色故障处理策略。
最后,他阐述了亚马逊云科技的韧性生命周期如何涵盖了设计、实施和运营阶段中灰色故障的检测和应对措施。此外,诸如韧性中心、故障注入模拟器、弹性灾难恢复、备份和应用程序恢复控制器等服务也有助于构建灵活的系统架构。
下面是一些演讲现场的精彩瞬间:
EC2实例如何使用DynamoDB进行分布式锁定,以及在出现问题时,一个仍持有锁定的实例如何阻止进程推进,这些问题都涉及到分布式锁的使用。

通过CloudWatch,开发者可以实时监控和分析应用程序的性能数据。
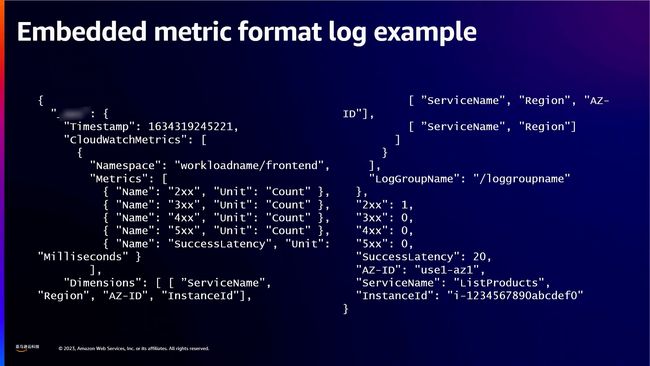
这种嵌入式的指标格式使得开发者能够轻松地查看所有指标,并将这些指标直接整合到自动转换成CloudWatch指标的日志文件中。
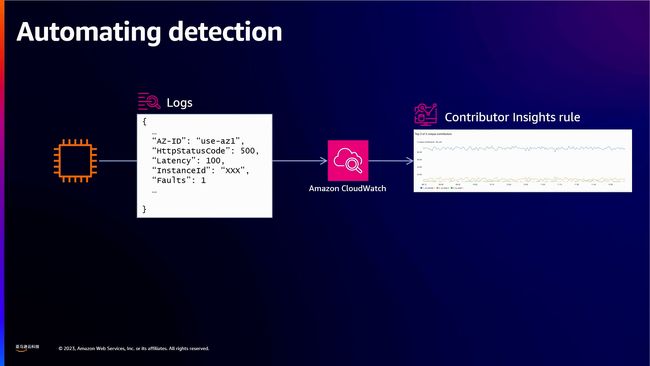
为了检测哪些主机导致了系统中超过75%的错误,演讲者建议基于Contributor Insights规则创建Amazon CloudWatch警报。

此外,演讲者还讨论了如何在Amazon CloudTech中创建复合警报,以便监控多个功能的性能和可用性。

演讲者还介绍了静态稳定性技术,这项技术可以在没有架构改变的情况下实现几乎立即从AZ故障中恢复。

总结
灰色故障"是指系统组件出现退化但仍有部分功能可用的故障现象,这种故障往往不易被发现。本视频讲解了如何在亚马逊云科技Amazon Web Services (亚马逊云科技)中通过合适的工具和结构来检测和降低灰色故障的风险。首先,通过对如可用区ID等上下文信息的补充,以便更深入地了解指标并隔离问题所在。利用贡献者洞察(Contributor Insights)对比不同实例的数据,找出可能导致灰色故障的异常值。设置自动报警以实时监测潜在问题。为了减少故障影响,只需更换出问题的实例即可。针对可用区故障,设计复合CloudWatch报警以检测孤立的问题点。通过采用Route 53健康检查或其他数据面操作而非控制面方法,分散受影响区域的流量,从而缓解故障压力。在架构设计中始终保持可用区的独立性。总的来说,通过合理的工具选择、异常值识别以及优先运用数据面技术,可以有效发现和迅速解决灰色故障。同时,利用恢复力中心(Resilience Hub)、故障注入模拟器等亚马逊云科技服务,构建更具抵抗力的系统。
演讲原文
https://blog.csdn.net/just2gooo/article/details/134807785
想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
2023亚马逊云科技re:Invent全球大会 - 官方网站
点击此处,一键获取亚马逊云科技全球最新产品/服务资讯!
点击此处,一键获取亚马逊云科技中国区最新产品/服务资讯!
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技“100 余种核心云服务产品免费试用”
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。
