SpringBoot2.x整合kafka消息队列中间件
docker-compose搭建kafka
# docker-compose配置文件
version: '3.2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
restart: always
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.123.193:9092 # ip地址:端口号
- KAFKA_LISTENERS=PLAINTEXT://:9092
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
# 以后台的方式运行容器
docker-compose up -d
# 进入kafka容器内
docker exec -it kafka /bin/bash
-
Topic是Kafka数据写入操作的基本单元,可以指定副本
-
一个Topic包含一个或多个Partition,建Topic的时候可以手动指定Partition个数,个数与服务器个数相当
-
每条消息属于且仅属于一个Topic
-
生产者发布数据时,必须指定将该消息发布到哪个Topic
-
消费者订阅消息时,也必须指定订阅哪个Topic的信息
# 创建名称为message的topic
kafka-topics.sh --create --topic message --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1
# 查看刚刚创建的topic信息
kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic message
# 消费者接收消息
kafka-console-consumer.sh --bootstrap-server kafka:9092 --from-beginning --topic message
# 重新开启一个shell端口,进入容器
docker exec -it kafka /bin/bash
# 打开生产者发送消息
kafka-console-producer.sh --topic=message --broker-list kafka:9092
bash-5.1# kafka-console-producer.sh --topic=message --broker-list kafka:9092
>hello world
>My name is buddha
bash-5.1# kafka-console-consumer.sh --bootstrap-server kafka:9092 --from-beginning --topic message
hello world
My name is buddha
能够成功发送和接收信息,则说明用docker-compose安装kafka成功了。
SpringBoot2.x集成kafka
项目结构:
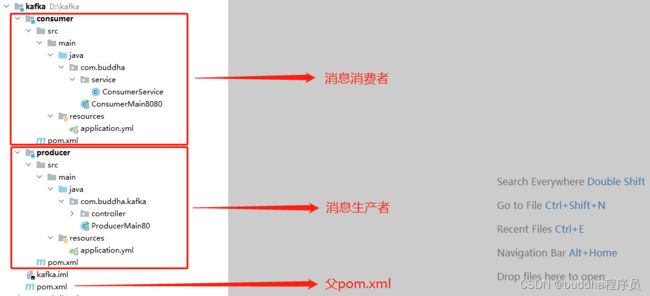
父pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<packaging>pompackaging>
<modules>
<module>producermodule>
<module>consumermodule>
modules>
<groupId>com.buddhagroupId>
<artifactId>kafkaartifactId>
<version>1.0.0version>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
<version>2.3.5.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<version>2.3.5.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
<version>2.5.7.RELEASEversion>
dependency>
dependencies>
dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
消息生产者
pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>kafkaartifactId>
<groupId>com.buddhagroupId>
<version>1.0.0version>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>producerartifactId>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
application.yml文件
server:
port: 80
spring:
application:
name: kafka-producer
kafka:
bootstrap-servers: 192.168.123.193:9092
producer: # 生产者配置
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384 #16K
buffer-memory: 33554432 #32M
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: message-group # 消费者组
enable-auto-commit: false # 关闭自动提交
auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: manual_immediate
main文件
package com.buddha.kafka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ProducerMain80 {
public static void main(String[] args) {
SpringApplication.run(ProducerMain80.class, args);
}
}
controller文件
package com.buddha.kafka.controller;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class ProducerController {
private final static String TOPIC_NAME = "message";
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public void send() {
// 发送消息
kafkaTemplate.send(TOPIC_NAME, "key", "hell world");
}
}
消息消费者
pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>kafkaartifactId>
<groupId>com.buddhagroupId>
<version>1.0.0version>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>consumerartifactId>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
application.yml文件
server:
port: 8080
spring:
application:
name: kafka-consumer
kafka:
bootstrap-servers: 192.168.123.193:9092
producer: # 生产者配置
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384 #16K
buffer-memory: 33554432 #32M
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: message-group # 消费者组
enable-auto-commit: false # 关闭自动提交
auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: manual_immediate
main文件
package com.buddha;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ConsumerMain8080 {
public static void main(String[] args) {
SpringApplication.run(ConsumerMain8080.class, args);
}
}
service文件
package com.buddha.service;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
@Component
public class ConsumerService {
@KafkaListener(topics = "message", groupId = "message-group")
public void listenMessage(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
// 手动提交offset
ack.acknowledge();
}
}