JPA与MySQL锁实战
前言:最近使用jpa和mysql时,遇到了死锁问题。在解决后将一些排查过程中新学到和复习到的知识点再总结整理一下。首先对InnoDB中锁相关的概念进行介绍,然后展示如何利用JPA提供的排他锁来实现想要的功能,最后对死锁问题进行讨论。
InnoDB锁的介绍
意向锁
意向锁是一个表级锁,一共有两种:意向共享锁和意向排他锁。主要的目的是表示当前表中某行记录正在被锁,或者即将被锁。事务在获取共享锁和排他锁之前,需要先获取对应的意向共享锁或者意向排他锁。
表级锁和行级锁是允许共存的,但也有不能共存的情况,比如当有一行记录存在排他锁时,就不允许再存在表锁了。
假设现在有一条记录被排他锁锁定,那么它会持有:该记录的行级排他锁,该表的意向排他锁。那么当另外一个事务想要将整张表锁定时,不需要挨个检查每个记录是否存在排他锁,只要检查该表是否有意向排他锁就可以达到目的了。
记录锁、间隙锁,临键锁
记录锁、间隙锁和临键锁是用来描述记录键锁的情况的。假设现在有如下几条记录:
1 3 5 7 9
每个记录之间是存在空间的,如1和3可以插入新的记录2。下面被括号包围的记录是被锁住的记录。
(1) 3( )5( 7) 9
记录锁
第一个括号包围的记录1,就是被记录锁锁住的。其他的事务不允许再更改1这条记录。记录锁实际上是锁住的索引,即便表里没有索引,InnoDB也会隐式创建一个聚簇索引来锁住。
间隙锁
第二个括号包围的是从3后面开始但不包括3,到5前面结束但不包括5的范围,锁住的是两条记录3和5之间的间隙,也就是间隙锁。
间隙锁和间隙锁不是互斥的,它的作用是保护两条记录的间隙不被插入新的记录。也即当在间隙锁锁住的范围进行插入操作时,需要进行等待。为什么间隙锁和间隙锁不互斥呢?
首先,前面说到间隙锁的作用是保护两条记录的间隙不被插入新记录,那么即便有两个间隙锁同时锁住了这个间隙,它们还是各自完成了自己的任务。
然后再考虑如下场景:
3( )5( )7
记录3和5之间被间隙锁锁住了,同时记录5和7之间的间隙也被锁住了,但记录5实际上是没有被任何锁锁住的。假设现在删除记录5:
3( )5( )7
那么这两个间隙锁必然要进行合并,锁住的内容就一样了:
3( )7
临键锁
上面第三个括号就是临键锁能锁住的范围,是记录5到记录7之间的间隙加上记录7本身。相当于是间隙锁在右面加上了一个记录锁。明白前面两个锁,这个自然也就明白了。
插入意向锁
插入意向锁不要和最开始提到的意向锁相混淆。插入意向锁使用的场景是:在对表进行insert操作之前,先要获取插入意向锁。插入意向锁来锁住要插入的记录两侧的间隙。比如当要在记录3和7之间插入记录5时,会锁住3到7之间的间隙:
3( 5 )7
可以看到插入意向锁实际上也是一种gap锁,不同事务的插入意向锁当然也不互相阻塞。
可重复读(Repeatable Read)
Mysql默认的事务隔离级别是可重复读,简称RR,RR隔离级别解决的并发事务下的幻读问题。复习一下什么是幻读:在一个事务中执行了两次查询,第二次查询结果中比第一次查询结果多出了记录,好像出现了幻觉。
假设现在表包含数据:0 1 2 4
| 事务1 | 事务2 |
|---|---|
| select * from test_table where id > 1 and id < 4 for update:2 | |
| insert into test_table values (3) | |
| select * from test_table where id > 1 and id < 4 for update: 2 |
我们假设当前隔离级别是RC再来分析一下这个过程。首先在查询语句后跟了for update,无论结果怎样,我们的目的是不希望两次查询被干扰的,或者说两次查询的结果要是一样的。此时即便对记录1、2、4都加上锁,那么事务2执行的插入语句是能成功将3插入进来的,因为这是一条不存在的记录,仅凭记录锁是没有办法锁住的。但是如果在2和4之间的范围上加临键锁,那么此时事务2的插入就需要等待了,2和4之间的间隙能有效地被间隙锁保护,记录2也能被记录锁保护。这样引入了临键锁(间隙锁+记录锁)也就避免了幻读问题,使隔离级别升级到了RR。
另外说一下,Oracle和PostgreSQL的默认事务隔离级别都是RC。
JPA排他锁
在介绍jpa之前,先说一下sql语句select ... for update,使用for update的前提是手动管理事务,即通过start transaction开启事务后再查询。for update的加锁周期是从事务开始到事务结束或回滚。for update的加锁有两种情况:
- where条件不是索引
这种情况下会直接将整个表锁住。 - where条件上有索引
有索引时会将符合条件的索引都锁住。
现在给出一个场景:有一张表test_tb,包括两个字段,id和status。两个字段均建有索引。每次接到一个请求,表中会插入statsu为2的数据。需求是,每经过一段时间,将最先插入的status为2的数据,更新为status = 1。服务是多实例部署,因此在读取数据时一定会考虑使用for update。
@Lock注解
在JPA中,使用for update语句只需要在Repository接口方法上添加注解@Lock(LockModeType.PESSIMISTIC_WRITE),比如下面这个方法:
@Lock(LockModeType.PESSIMISTIC_WRITE)
TestTb findFirstByStatus(int status);
当然,仅仅标记一个@Lock注解是不够的。我们前面提到了,for update语句是需要在事务中执行的,因此还必须与事务注解搭配使用。
插入语句是比较简单的,看一下使用sql如何达到更新的目的:
start;
select * from test_tb t where t.status = 2 limit 1 for update;
update test_tb t set t.status = 1 where t.id = 1001; -- 这里id应该是select查出来的
commit;
如何使用JPA将上面的sql转为代码呢?实际上很简单,除了上面的接口方法外,还需要在另外一个类中新建一个方法:
@Transactional
public TestTb findTestTbByStatusOnLock(int status) {
TestTb testTb = testTbRepository.findFirstByStatus(status);
// 不存在是返回null
if (testTb == null) {
return null;
}
// 更新状态并保存至数据库
testTb.setStatus(1);
testTbRepository.save(testTb);
return testTb;
}
多实例读取缓存问题
在上面的方法中,实现了查询和更新的完整事务。不过这样写还是存在问题的,表现出来的现象就是没有锁住。有同学可能会想,是不是因为调用的save方法没有及时flush。我们知道save方法在执行后并不会立即保存到数据库,而是会先被缓存起来,必须要进行一个flush操作后才会立即同步到数据库。实际上出问题的地方并不在保存这一步,在事务提交时数据就会写入数据库了。原因在于前面testTbRepository.findFirstByStatus(status)这一步读取到的很可能并不是数据库中最新的数据(缓存中的数据),从而导致前面的findTestTbByStatusOnLock方法会重复更新其他实例已经读取并更新过的内容。
同时这里还会产生死锁,在死锁的时候会产生异常使该方法不能返回值 。因此还需要对异常和事务回滚做一下处理:
// Exception用于捕获死锁异常
@Transactional(rollbackFor = Exception.class)
public TestTb findTestTbByStatusOnLock(int status) {
TestTb testTb;
try {
testTb = testTbRepository.findFirstByStatus(status);
} catch (Exception e) {
// 死锁异常时手动回滚,这样方法才能有返回值
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return null;
}
testTb.setStatus(1);
testTbRepository.save(testTb);
return testTb;
}
我们先来解决没有锁住,也就是重复更新问题。其实很简单,我们不用缓存就可以了。并且在这种情况下,我们是希望每次查询都去数据库读取最新状态的,没有使用缓存的必要。因此我们在实体类上通过注解@Cacheable关闭就可以了:
@Entity
@Table(name = "test_tb")
@Cacheable(value = false)
public class TestTb {
// ···
}
死锁
前面实际上已经实现了场景所需的功能,只是有可能会报出死锁的错误。因此将死锁问题单独拿出来分析。首先对场景进行复现:
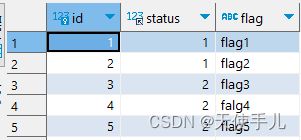
begin;
SELECT * FROM test_DB.test_tb tt WHERE tt.status = 2 limit 1 for UPDATE; --1
UPDATE test_DB.test_tb tt SET tt.status = 1 WHERE tt.id = 3; --2
commit;
上面sql分别在两个会话中执行,会话1执行1,会话2执行1,会话1执行2,此时会话2产生死锁。
死锁日志及分析
再来看一下会产生的死锁日志show engine innodb status;:
------------------------
LATEST DETECTED DEADLOCK
------------------------
2023-12-04 15:42:59 139984137955072
*** (1) TRANSACTION:
TRANSACTION 1961, ACTIVE 39 sec starting index read // 根据索引读取数据
mysql tables in use 1, locked 1 // 锁住一张表,一行数据
LOCK WAIT 2 lock struct(s), heap size 1128, 1 row lock(s) // 等待2个锁结构
MySQL thread id 47, OS thread handle 139984461809408, query id 923 192.168.1.3 root executing
/* ApplicationName=DBeaver 23.2.5 - SQLEditor */ SELECT * FROM test_DB.test_tb tt WHERE tt.status = 2 limit 1 for UPDATE // 执行的sql语句
*** (1) HOLDS THE LOCK(S): // 持有的锁 // 写锁正在等待,应该是临键锁
RECORD LOCKS space id 2 page no 5 n bits 80 index test_tb_status_IDX of table `test_DB`.`test_tb` trx id 1961 lock_mode X waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
// 锁的索引上的信息
0: len 4; hex 80000002; asc ;; // hex 16进制编码,status 2
1: len 4; hex 80000003; asc ;; // id 3
*** (1) WAITING FOR THIS LOCK TO BE GRANTED: // 正在等待的锁
RECORD LOCKS space id 2 page no 5 n bits 80 index test_tb_status_IDX of table `test_DB`.`test_tb` trx id 1961 lock_mode X waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 80000002; asc ;;
1: len 4; hex 80000003; asc ;;
*** (2) TRANSACTION:
TRANSACTION 1960, ACTIVE 55 sec updating or deleting // 执行更新或删除操作
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1128, 3 row lock(s), undo log entries 1
MySQL thread id 45, OS thread handle 139984467093248, query id 930 192.168.1.3 root updating
/* ApplicationName=DBeaver 23.2.5 - SQLEditor */ UPDATE test_DB.test_tb tt SET tt.status = 1 WHERE tt.id = 3 // 更新语句导致的死锁
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 2 page no 5 n bits 80 index test_tb_status_IDX of table `test_DB`.`test_tb` trx id 1960 lock_mode X // 持有写锁,临键锁
Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 80000002; asc ;;
1: len 4; hex 80000003; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED: // 等待插入意向锁
RECORD LOCKS space id 2 page no 5 n bits 80 index test_tb_status_IDX of table `test_DB`.`test_tb` trx id 1960 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 80000002; asc ;;
1: len 4; hex 80000003; asc ;;
*** WE ROLL BACK TRANSACTION (1)
事务一在查询时申请了status索引上记录2的临键锁,和id索引上记录3的锁:

1 1( 2 2) 2
1 2 (3) 4 5
接着事务二在查询时同样申请到status索引上记录2的临建锁,等待id索引上记录1的锁:

1 1([ 2 2)] 2
1 2 (3) 4 5
事务一执行更新语句获取status上记录2的插入意向锁,导致和事务二死锁:

1 1{([ 2 2)] 2 }
1 2 (3) 4 5
解决方案
解决的方案就是将数据库隔离级别进行降级,SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;设置数据库隔离级别为RC。
在我们这个例子中,对查询方法执行会话级别的设置也是可以的:@Transactional(rollbackFor = Exception.class, isolation = Isolation.READ_COMMITTED)。此外,针对这种类似队列的场景,使用skip locked语句也能较好地处理。该语句的作用是跳过被锁定的记录进行读取。
RR隔离级别并非一定优于RC级别,在并发量较大时使用RC级别能更好地保证数据库性能。
文中只是对一个死锁场景进行了分析,但在分析过程中也查阅了相关资料。会产生死锁的情况非常多,可以参考一下:https://github.com/aneasystone/mysql-deadlocks/。
解决死锁问题的方法通常也是关注以下几点:
- 打印和分析相关日志,包括数据库日志和应用日志
- 尽量缩短事务范围,减少事务间的业务代码
- 事务持续时间不宜过长
- 使用for update或for share时降低隔离级别
- 事务间操作按顺序执行,避免交叉