分布式数据库HBase
文章目录
前言
一、HBase概述
1.1.1 什么是HBase
- HBase是一个分布式的、面向列的开源数据库
- HBase是Google BigTable的开源实现
- HBase不同于一般的关系数据库, 适合非结构化数据存储
- HBase是一种分布式、可扩展、支持海量数据存储的 NoSQL数据库。
- HBase是依赖Hadoop的。为什么HBase能存储海量的数据?因为HBase是在HDFS的基础之上构建的,HDFS是分布式文件系统。
- HBase在HDFS之上提供了高并发的随机写和支持实时查询,这是HDFS不具备的。
- 基于「列式存储」,存储数据的“结构”可以地非常灵活。
1.1.2 BigTable
- BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。
- 适合大规模海量数据,PB级数据;
- 分布式、并发数据处理,效率极高;
- 易于扩展,支持动态伸缩
- 适用于廉价设备;
- 不适用于传统关系型数据的存储;
1.1.4 什么是非结构化数据存储
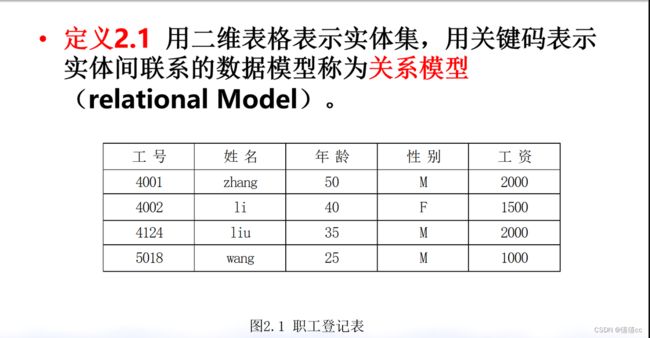
- 结构化数据
- 适合用二维表来展示的数据
- 非结构化数据
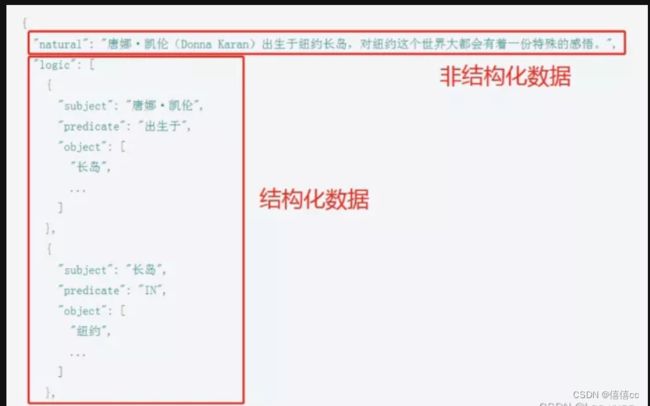
- 非结构化数据是数据结构不规则或不完整
- 没有预定义的数据模型
- 不方便用数据库二维逻辑表来表现
- 办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息
1.1.5 HBase在Hadoop生态中的地位
-
HBase是Apache基金会顶级项目
-
HBase基于HDFS进行数据存储
-
HBase可以存储超大数据并适合用来进行大数据的实时查询
1.1.6 HBase与HDFS
- HBase建立在Hadoop文件系统上, 利用了HDFS的容错能力
- HBase提供对数据的随机实时读/写访问功能
- HBase内部使用哈希表, 并存储索引, 可以快速查找HDFS中数据
1.1.7 HBase使用场景
- 瞬间写入量很大
- 大量数据需要长期保存, 且数量会持续增长
- HBase不适合有join, 多级索引, 表关系复杂的数据模型
- 适合场景(大型互联网公司都用HBase)
- 表数据量大(至少亿级别以上) 写入量大(每天千万级别以上)
- append型业务(比如日志,聊天记录等)
- 读取量相对少(读取:写入<=1/10)
- 读取场景简单、不经常变化、无排序要求
- 无跨行跨表事务要求
不适合场景
- HBase仅支持行级事务(银行业务基本不用HBase)
- 类似DW等全量读取(hive), 不太适合
1.2.4 HBase 与 传统关系数据库的区别
| HBase | 关系型数据库 | |
| 数据库大小 | PB级别 | GB TB |
| 数据类型 | Bytes | 丰富的数据类型 |
| 事务支持 | ACID只支持单个Row级别 | 全面的ACID支持, 对Row和表 |
| 索引 | 只支持Row-key | 支持 |
| 吞吐量 | 百万写入/秒 | 数千写入/秒 |
二.HBase数据模型
HBase的设计理念依据google的BigTable论文,论文中对于数据模型的首句介绍
Bigtable是一个稀疏的,分布式的,持久的多维排序的map。
之后对于映射的解释如下:
该映射由行建,列建和时间戳索引;映射中的每个值都是一个未解释的字节数组。
最终HBase关于数据模型和BigTable的对应关系如下:
HBase使用与BigTable非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同意表中的行可以具有疯狂变化的列。
最终理解Hbase数据模型的关键在于稀疏,分布式,多维,排序的映射,期中映射map值代非关系型数据库的key-value结构。
2.1、HBase逻辑结构

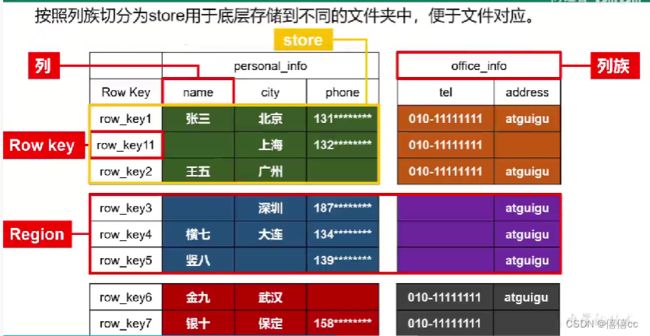
逻辑结构分析:
- Region:相当于表,数据量大的时候会进行切片,相当于数据库的水平分表分库。
- store:每个Store其实就是一个列族的数据(所以我们可以说HBase是基于列族存储的)
- 列族(Column Family):在HBase里边,先有列族,后有列;可以简单理解为:列的属性类别。
- 列(Column Qualifier,列修饰符):在HBase中用列修饰符(Column Qualifier)来标识每个列。
- 行键(RowKey):定位一行数据的唯一值。
2.2.HBase物理存储结构
物理存储结构即为数据映射关系,而在概念试图的空单元格,底层实际根本不存储。

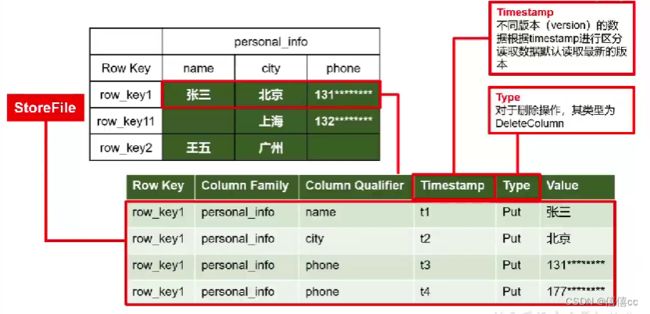
2.3数据模型
1. 表(Table)
HBase采用表来组织数据,表由行和列组成,列划分为若干个列族。
2. 行(Row)
每个HBase表都由若干行组成,每个行由行键(Row Key)来标识。访问表中的行只有3种方式:通过单个行键访问;通过一个行键的区间来访问;全表扫描。
3. 列族(Colume)
一个HBase表被分组成许多“列族”的集合,它是基本的访问控制单元。列族需要在表创建时就定义好,数量不能太多(HBase的一些缺陷使得列族数量只限于几十个),而且不要频繁修改。存储在一个列族当中的所有数据,通常都属于同一种数据类型,这通常意味着具有更高的压缩率。
4. 列限定符
列族里的数据通过列限定符(或列)来定位。列限定符不用事先定义,也不需要在不同行之间保持一致。列限定符没有数据类型,总被视为字节数组byte[]。
5. 单元格
在HBase表中,通过行、列族和列限定符确定一个“单元格”(Cell)。单元格中存储的数据没有数据类型,总被视为字节数组 byte[]。每个单元格中可以保存一个数据的多个版本,每个版本对应一个不同的时间戳。
6. 时间戳
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。每次对一个单元格执行操作(新建、修改、删除)时,HBase都会隐式地自动生成并存储一个时间戳。
三.HBase架构角色

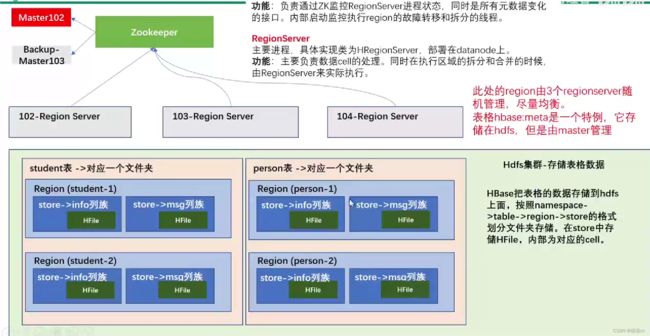
(1) Master实现类为HMaster,负责监控集群中所有的 RegionServer 实例。主要作用如下:“管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行
(2)监控region 是否需要进行负载均衡,故障转移和region 的拆分。e通过启动多个后台线程监控实现上述功能
周期性监控region 分布在regionServer 上面是否均衡,由参数 hbase.balancer.period 控周期时间,默认5 分钟。
定期检查和清理hbase:meta中的数据。meta表内容在进阶中介绍。
把master 需要执行的任记录到预写日志WAL中,如果 master 宕机,让 backupMaster读取日志继续干。
(2) Region Server
Region Server 实现类为 HRegionServer,主要作用如下:
- 负责数据 cell 的处理,例如写入数据 put,查询数据 get 等
- 拆分合并region 的实际执行者,有 master 监控,有regionServer 执行。
(3)Zookeeper
HBase 通过 7ookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储有meta 表的位置信息。
HBase 对于数据的读写操作时直接访问 Zookeeper 的,在2.3 版本出 Master Registry模式,客户可以直接访间 master。使月此功能,会加大对 master 的压力,减轻对 Zokeeper的压力。
(4) HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
扩展知识
一.Dubboy框架(远程过程调用)
1.分布式系统中的相关概念
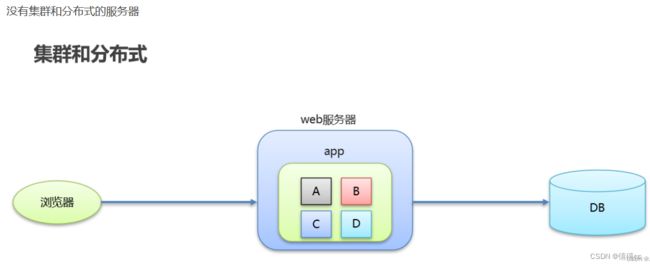
传统项目和互联网项目

大型互联网项目的架构目标

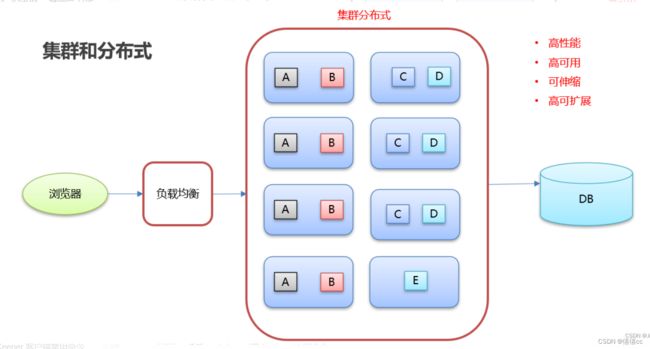
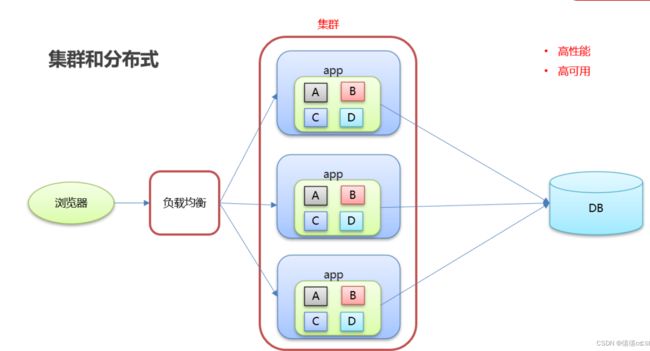
集群和分布式

进行集群的服务器-可以进行负载均衡,实现了高性能、高可用的目标
同时进行集群和分布式的服务器-除了集群实现的功能和目标,还可以实现可伸缩、高可扩展的目标