爬虫字体反爬的解决(三)
前面带大家了解了静态字体反爬,本文再从动态字体反爬的角度带大家理解另一种破解方式。相对于静态字体反爬,动态字体反爬的破解会更难一些。因为每一次刷新页面,你会发现这个页面所使用的字体文件会变,就导致了不能够再像以前一样只去构建字体映射,还需要从字体的轮廓等方面去探寻答案。文末有完整代码,建议大家参照代码阅读文章。
一、背景
本来我想要从Cat’s eye movie这个网站抓取一部分电影数据,进行数据分析,结果摆在我眼前的数据是加密的,网站使用了字体反爬,那确实没办法,想要数据就只能先进行反爬的破解。
二、数据抓取
先把想要的数据抓取到,然后通过此网站使用的字体文件进行破解。
由于网站是动态类型的,所以不得不使用 selenium 进行网页源码的获取,那么还需要你的电脑上有 Google Chrome,下载链接:https://www.google.cn/chrome/index.html
抓取数据的过程不再赘述,直接看下方代码,涉及知识点为:正则表达式、 selenium 模块、 webdriver-manager 模块等。
import re
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
def selenium_setting(link: str) -> str:
driver_path = ChromeDriverManager(path='./', cache_valid_range=7).install()
s = ChromeService(executable_path=driver_path)
# 创建配置项对象
Options = webdriver.ChromeOptions()
Options.add_argument('blink-settings=imagesEnabled=false')
Options.add_argument("disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(service=s, options=Options)
driver.get(url=link)
WebDriverWait(driver, 20).until(
EC.text_to_be_present_in_element(
('xpath', '/html/body/div[3]/div/div[2]/div[2]/div/a[1]/div/span'), '想看'
)
)
html = driver.page_source
driver.quit()
return html
def movie_info_spider(html_code):
"""电影信息获取"""
# 电影名
movie_name = re.findall(r'(.*?)
', html_code)[0]
# 猫眼口碑、参与评分人数、累计票房
reputation, num, ticket_office = re.findall(r'(.*?)', html_code)
movie_data = {'电影': movie_name, '口碑': reputation, '评分人数': num, '累计票房': ticket_office}
return movie_data
movie_url = 'https://www.maoyan.com/films/1200486'
html_source = selenium_setting(movie_url)
movie_info = movie_info_spider(html_source)
print(f'源数据{movie_info}')
上方代码得到的结果是这样的:源数据{'电影': '我不是药神', '口碑': '\ue9ea.\uf7ff', '评分人数': '\ue99c\ueb92\ue8ee.\ueb92万', '累计票房': '\ue8d7\uf85e.\uf726\uf726'}
三、字体文件的下载
拿到了加密后的数据,我们就需要再找到网页使用的字体文件进行随后的破解,然而因为这个网站每重新加载一次,便会使用一个新的字体文件,因此至少我们还要拿到 2-3 个字体文件作为样本。经过源代码的关键字检索,发现每次页面会同时加载2个字体文件,复制链接,给每一个字体文件的链接前添加 https:,便能直接下载相应的字体文件,我一共拿了 3 个字体文件。


四、字体文件的解析与内容解读
字体文件是可以进行解析的,我们可以使用fonttools模块,将字体文件解析处理为 xml 类型的文件。这是它的官方文档:https://github.com/fonttools/fonttools,安装的命令就是 pip install fonttools 。
我将下载好的字体文件存入到指定的目录下,然后使用代码将其处理,直接来看解析代码。
import os
from fontTools.ttLib import TTFont
def font_to_xml(font_path):
"""字体 转 xml文件"""
font_list = os.listdir(font_path)
for file_name in font_list:
if file_name[-5:] == '.woff' and f'{file_name[:-5]}.xml' not in font_list:
print(f'正在转换{file_name}')
font = TTFont(f'{font_path}/{file_name}')
font.saveXML(f'{font_path}/{file_name[:-5]}.xml')
print(f'{file_name}转换完成')
sample_font_path = './font/font_sample'
font_to_xml(sample_font_path)
这是字体样本解析处理后的结果,你可以打开每一个 xml 文件进行查看,看一下每个字体文件的内部构造。我来带大家解读一下我们需要的信息,随便打开一个解析后的 xml 文件。
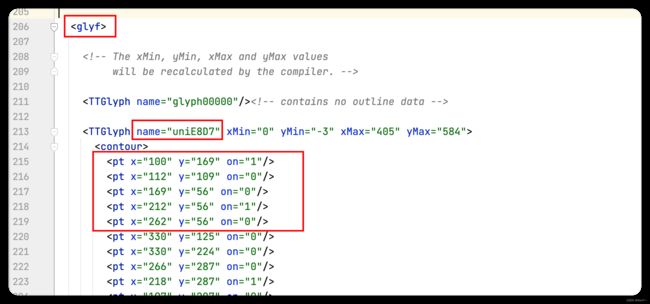
大家可以看我圈出的部分,每一个 TTGlyph 代表一个符号、name 就是这个符号映射的编码、pt 就是这个符号每一笔的坐标,其中 on 是轮廓,on=1 表示直线、 on=0 表示弧线。
我们需要的便是这个 name 和 on,首先每个符号在一个字体文件中都有对应的映射后的编码,其次每个符号在不同字体文件中虽然坐标可能不同,但是大致轮廓是相同的,可以通过相似度对比来确认是否是同一个符号。 那么接下来,我们便需要根据字体文件构建映射、需要从 xml 文件中提取出 name 和 on,使得映射和轮廓相对应。
映射的构建可以使用这个网站:https://kekee000.github.io/fonteditor/,name 和 on 的提取可以使用 lxml 模块结合 XPath 表达式,看图和代码:
import os
from glob import glob
from lxml import etree
from uuid import uuid1
def font_outline(font_path):
"""获取符号轮廓数据"""
xml_list = glob(f'{font_path}/*.xml')
font_outline_data = {}
for xml_file in xml_list:
with open(xml_file, 'rb') as file:
root = etree.XML(file.read())
TTGlyph_list = root.xpath('./glyf/TTGlyph')[1:-1]
for i in TTGlyph_list:
code_name = i.xpath('./@name')[0]
pt_on = i.xpath('.//pt/@on')
font_outline_data[f'{code_name}_{uuid1()}'] = ''.join(pt_on)
return font_outline_data
def font_map(font_data):
"""符号与符号轮廓的构建"""
font_20a70494 = {
'uniF726': 0, 'uniF85E': 1, 'uniE99C': 2, 'uniE8D7': 3, 'uniE8EE': 4,
'uniECDC': 5, 'uniF7FF': 6, 'uniEB92': 7, 'uniF1FC': 8, 'uniE9EA': 9
}
font_75e5b39d = {
'uniF66D': 0, 'uniE6D5': 1, 'uniEC68': 2, 'uniF615': 3, 'uniEAB3': 4,
'uniEF74': 5, 'uniE5AC': 6, 'uniE317': 7, 'uniE1B7': 8, 'uniE274': 9
}
font_e3dfe524 = {
'uniEA6F': 0, 'uniED30': 1, 'uniE3EC': 2, 'uniF11C': 3, 'uniF7D2': 4,
'uniF3E8': 5, 'uniEA60': 6, 'uniE3DF': 7, 'uniEF28': 8, 'uniEB19': 9
}
font_list = [font_20a70494, font_75e5b39d, font_e3dfe524]
for font_map in font_list:
for key, value in font_map.items():
font_data = str(font_data).replace(key, str(value))
with open('./font_sample_data.txt', 'w') as file:
file.write(font_data)
print('字体样本数据保存完成!!!')
sample_font_path = './font/font_sample'
outline_data = font_outline(sample_font_path)
font_map(outline_data)
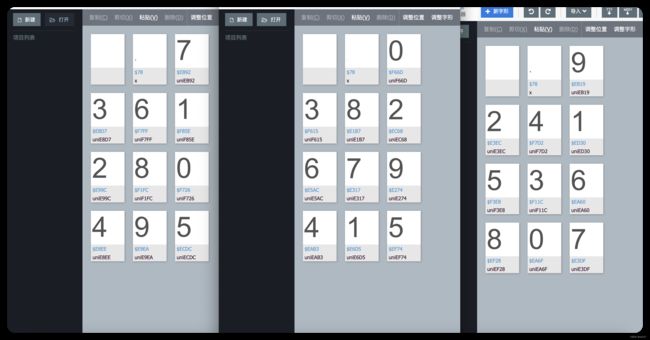
这是拿到的每个字体样本中的每个符号及其轮廓的字典, 出于后续需要以及性能角度考虑,已经将样本轮廓数据写入到 txt 文本文件中了。文件中的数据大概是如下方截图所示这样的,每个键值对的键的第一个元素就是符号,值就是其对应的轮廓,但是我在符号上应用了 uuid 模块,就变成了大家看到的键的样子,使用这个模块就是为了防止数据缺失,大家都知道一个字典中键不能出现两次,何况这分别是三个字体文件中的 0-10 这 10 个符号,我就是为了防止不同的字体文件中出现了同样的符号进而导致数据缺失,才使用的 uuid 模块中的 uuid1 方法,将时间戳拼接到符号上防止重复。

五、实时页面字体数据获取
这个网站每次获取数据时,页面使用的字体文件会变,所以我们必须实时的将字体文件获取下来,通过相似度对比进行破解,下方代码是下载页面实时字体文件的代码:
import requests
def download_font(html_code):
"""实时 font 下载 与转xml
注意此处有坑,一个页面会同时出现两个字体文件,随机使用其中一个
"""
match_font_link = re.findall(r',url\("(//s3plus.meituan.net/v1/.*?.woff)', html_code)
for i in match_font_link:
font_url = 'https:' + i
print(f'字体文件下载链接{font_url}')
response = requests.get(url=font_url)
test_font_path = 'font/cracking_font'
with open(f'{test_font_path}/{font_url[font_url.rindex("/"):]}', 'wb') as f:
f.write(response.content)
download_font(html_source)
同时,我们还需要实时字体文件的相关数据(符号编码、符号轮廓),前面已经构建好了函数,我们直接调用即可。
from font_sample_processing import font_to_xml, font_outline
test_font_path = './font/cracking_font'
font_to_xml(test_font_path)
test_font = font_outline(test_font_path)
六、使用相似度匹配进行数据的破解
我们根据已经够建好的字体样本数据以及每次爬取页面数据时获取到的实时字体文件的数据,进行相似度匹配。
from difflib import SequenceMatcher
def similarity_comparison(test_f, sample_f):
"""相似度比较"""
result_font_map = {}
for test_key, test_value in test_f.items():
possibility = 0
for sample_key, sample_value in sample_f.items():
mid_similarity = SequenceMatcher(None, test_value, sample_value).ratio()
if mid_similarity >= possibility:
possibility = mid_similarity
result_font_map.update({test_key[:7].lower(): sample_key[0]})
return result_font_map
test_font_path = './font/cracking_font'
font_to_xml(test_font_path)
test_font = font_outline(test_font_path)
sample_font = eval(open('font_sample_data.txt').read())
similarity_result = similarity_comparison(test_font, sample_font)
movie_info = str(movie_info).replace('\\u', 'uni')
for key, value in similarity_result.items():
movie_info = movie_info.replace(key, value)
print(f'破解后{eval(movie_info)}')

七、文件的删除
因为涉及到实时字体文件的实时性,所以每个页面数据爬取完,需要删除本次下载好的文件,不然会产生文件冗余以及不必要的影响。
import os
file_list = os.listdir(test_font_path)
for i in file_list:
os.remove(f'{test_font_path}/{i}')
八、完整代码
https://download.csdn.net/download/weixin_42788769/87945832
九、总结
代码中没涉及太多的注释,一方面是考虑到爬虫能学到这一步,相信大家能力是足够的;另一方面也是为了让大家能够自己探求每一行代码在程序中的功能,所以只提供代码和大致思路,具体的理解就依靠大家自己了。