四. 基于环视Camera的BEV感知算法-BEVDet
目录
-
- 前言
- 0. 简述
- 1. 算法动机&开创性思路
- 2. 主体结构
- 3. 损失函数
- 4. 性能对比
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVDet 感知算法
课程大纲可以看下面的思维导图
0. 简述
本次课程我们和大家一起学习一下一篇非常经典的环视算法 BEVDet,其实从题目中也能看出来像 BEVDet 算法是 High-Performance 一个高性能的 BEV 算法,它这个性能是包含两方面的,一方面准确度是很好的,另一方面它的速度也是比较快的,偏工程应用性质的一篇文章,我们一起来学习一下
首先还是从四个方面展开,算法动机&开创性思路、主体结构、损失函数和性能对比
1. 算法动机&开创性思路
它的开创性思路是什么呢,我们在介绍 BEVDet 的动机前,我们先看一下题目是什么意思,BEVDet 的全文名字叫 BEVDET: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View,那什么意思呢,High-Performance 是一个性能很高的一种检测器,那性能我们刚刚也讲过包含两个方面,一方面是它的精度很高,另一方面是速度很快;那 Multi-Camera 我们很熟悉了环视的意思,环视表示的是多视角的图像,所以我们知道 BEVDet 这篇工作是在基于多视角的图像来做 3D 处理的;另一个关键词是 Bird-Eye-View 也就是我们说的上帝视角俯视图,那我们结合这两个词可以猜到 BEVDet 怎么做呢,利用的是多视角的图片统一到 BEV 的视角后去进行 3D 检测任务
刚提到的这个是目前自动驾驶领域比较火的一个研究方向,我们主要是基于采集到的环视图像信息构建 BEV 视角特征从而完成自动驾驶感知的相关任务。从相机视角能够转换到 BEV 视角是非常重要的一个事情,那目前主流的方法是分为两种,一种叫显式估计的图像深度完成 BEV 多视角的构建,那也被称为从下而上的构建方式;另一种是利用 Transformer 的 Query 查询机制可以利用 BEV Query 来构建 BEV 特征,也叫自上而下的构建方式

上图所示的是我们第二章一个基础模块的部分,BEV 感知算法开山之作叫 LSS(Lift-Splat-Shoot),我们说 LSS 提供了一个非常好的融合 BEV 视角的方法,融合了多视角的图像特征,是一个纯视觉的方案,那也是现在很多基于多视角图像 3D 目标检测算法的一个非常重要的 baseline。后续可以看到我们要讲的 BEVDet 其实也是基于 LSS 框架去做的延伸拓展的操作
那图中 Lift 操作输入是什么呢,是多视角图像,送入 Backbone 之后提取多视角图像特征,进一步利用深度估计网络去估计出每个像素对应的深度分布,我们这里要强调一点它并不是对每个像素预测一个 depth 值而是利用深度分布的方式表示每个 Pixel 的深度信息,它是一个点和线的对应关系,我们强调了很多次一个点如果在未知深度的情况下映射到 3D 空间是一条射线,如下图所示:
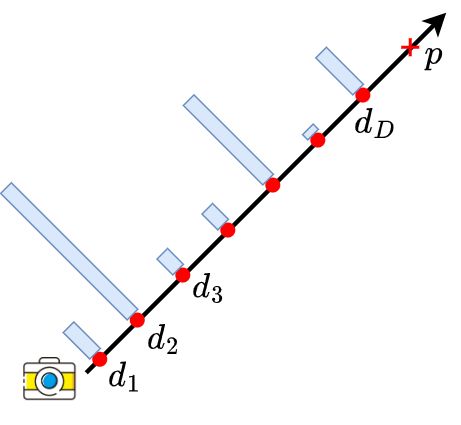
我们预测的其实是射线上的深度分布概率值,所以在原文当中 LSS 的作者也多次强调他所说的 Depth 是一个 Ambiguous,也就是说是模棱两可的 Depth,它并不是说一个确定性的 Depth,我们就一定坐落在某个深度位置。我们得到深度分布之后呢,原有的图像特征维度比如说是 C × H × W C\times H \times W C×H×W,每个像素点是 C C C 维特征向量,如果我们为每一个像素点分配了一个 D D D 维的深度分布向量和它原始的 C C C 维特征向量组合起来是 D × C D \times C D×C 维,也就是说我们一个像素映射完之后应该是一个 D × C D \times C D×C 的向量。如果我们本身是构建了一个 H × W H\times W H×W 的空间之后,那我们完整的视锥特征的维度是什么呢,应该就是 D × C × H × W D\times C\times H\times W D×C×H×W,那这一步操作完成之后我们就相当于在每个像素上都预测了一个深度分布的值,通过相机的内外参数可以转换到 BEV 视角下
那我们在做完这个操作之后还存在一个什么问题呢,我们 BEV 网格上每一个点它是不止一个像素映射过来的,存在很多的点,那我们需要对这个点去进行求和的操作,我们将特征进行拍扁降维我们可以得到最终的多视角图像融合后的 BEV 特征,那也就是对应我们 Splat 的这个操作。我们有了 BEV 特征之后我们将它送到后续的检测网络当中我们就可以完成相应的检测任务,那包括我们现在说的自动驾驶场景也不外乎是这些操作的
那我们讲到这里大家可能会有疑问,我们这篇论文讲的不是 BEVDet 吗,那为什么现在我们都在说 LSS 方法的原理呢,那一方面我们这里其实是想给大家复习一下本身 BEVDet 算法的核心内容,2D 到 3D 的转换模块;另外一个本身而言 BEVDet 这份工作更偏向于一个偏工程性质的工作,也就是说这篇工作本身没有什么特别有创新点的地方,那这其实也是作者在原文当中说的,他本身没有设计出任何新的模型而是更关注于 BEV 去做 3D 检测的可行性,是通过一些成熟的框架来构建 BEVDet 的,所以说 BEVDet 的原理和出发点和之前 BEV 论文是相似的,你读懂了 LSS 你就读懂了 BEVDet,它们的核心思想是通过多视角的 2D 图像可以转换到 3D 空间从而构建 BEV 空间,那我们这里所说的多视角 2D 图像其实也就是我们说的环视图像
所以最后我们总结一下 BEVDet 的动机其实是通过多视角的 2D 图像预测出对应的深度分布,利用相机的内外参转换到 3D 空间当中进一步投影到 BEV 空间完成 3D 检测任务,那 BEVDet 干的事情其实就是把这个流程完整化进一步工程化,通过这样的一个方式得到一个完整的 Detection 框架
2. 主体结构
接着我们看一下 BEVDet 网络的主体结构是什么,那我们具体是怎么设计这个网络的,它的框图如下所示:
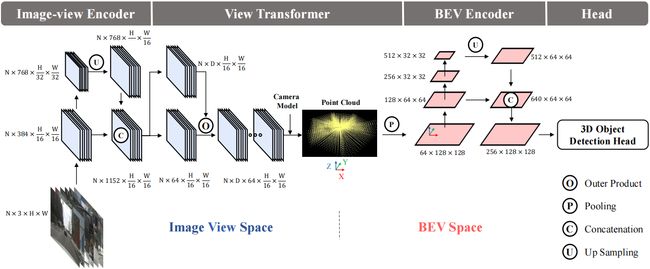
上图是 BEVDet 完整的框架图,我们还是老套路看网络先看输入输出,输入是多视角图像,那这里维度也很清楚是 N × 3 × H × W N\times 3\times H\times W N×3×H×W,前面 N N N 是图像的个数, H × W H\times W H×W 是输入图像的尺寸, 3 3 3 表示通道数,输出对于 3D 检测任务而言自然是检测结果,也就是 3D 的 Bounding Box
我们知道输入输出之后我们再仔细看一下整体框架,整个框架图画得非常清晰一目了然,其中包括 4 个模块,前面第一个模块是 Image-view Encoder 图像编码模块,是用来做什么事情呢,来做图像特征的编码;第二个叫 View Transformer,是用来做什么呢,用来做视角转换,BEVDet 主要想实现的是从图像空间可以转换到 BEV 空间,那我们之前在前面讲过这个转换过程是一个 2D 到 3D 的转换,图像特征从 2D 映射到 3D 再拍扁到 BEV 特征,我们刚刚讲 LSS 的时候也详细讲了这个过程
那后续第三个是 BEV Encoder,是用来做什么的呢,是对 BEV 特征做进一步编码,那 Head 其实是任务头,我们一般说有一个特定的任务我们用什么头呢,那比如检测任务我们叫 Detection Head 是一个特定任务的头,所以 BEVDet 它是针对 3D 检测任务的就是 3D 检测头,那图中也写得很清楚叫 3D Object Detection Head
所以 BEVDet 完整的流程其实非常简单一目了然而且使用的模块全都是我们已知的模块,那对于输入的多视角图像先提取特征,图像转换到 BEV 空间得到 BEV 表征再通过 BEV 编码去进一步的提取 BEV 特征,然后将提取完的 BEV 特征送入到检测头完成 3D 目标检测任务
接下来我们看一下每一个模块是怎么实现的,图像特征编码是怎么做的,从图像 Encoder 看起,框图如下所示:
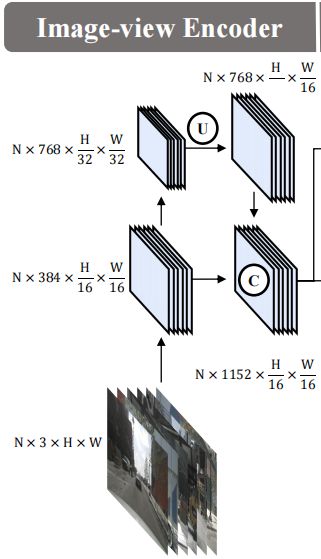
Image-view Encoder 设计流程如下:
- 输入:多视角图像
- 步骤 1:2D Backbone 提取基础图像特征
- 步骤 2:多尺度特征融合
- 输出:Camera Features
我们上面讲过图像特征编码模块输入是多视角图像,输出是多视角图像特征,那流程怎么做呢,有多视角图像,图像应该用什么网络处理呢,应该用图像编码器处理,所以这里是个 2D 的 Backbone,2D 的 主干网络提取图像特征,提取完成之后又引入了我们常见的老伙伴尺度融合,跨尺度的一个融合,不同视角的图像是共享 Backbone 和 Neck 的,比如说我们在 nuScenes 数据集中有 6 个不同的视角,6 个视角它不会为每个视角去单独设计一个 Backbone,6 个视角是共享一个 Backbone 的
OK,那我们仔细拆解一下图像 Encoder 的前向过程,输入图像的维度是 N × 3 × H × W N\times 3\times H\times W N×3×H×W, N N N 是什么,是相机个数,后面的 3 × H × W 3\times H \times W 3×H×W 是图像维度,那我们经过 Backbone 之后呢,输入其实是有一个下采样的状态的,同时通道数变多,通道数从 3 扩大到了 384,图像尺寸下采样 16 倍,那就是 H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W,相机个数不变还是 N N N 个,所以我们经过 Backbone 之后图像特征变成什么呢,变成了 N × 384 × H 16 × W 16 N\times 384 \times \frac{H}{16} \times \frac{W}{16} N×384×16H×16W
然后我们想提取多尺度特征要怎么做,对已有的特征图继续下采样,也就是说尺度我们还要缩一倍,但是通道数我们翻一倍,所以从图中我们能看到经过继续的下采样后通道维度变成了 768,尺度维度由原来的 1 16 \frac{1}{16} 161 的原始尺寸变成了 1 32 \frac{1}{32} 321 的原始尺寸,通过下采样的操作我们一方面增大通道数一方面我们降低尺寸,然后我们再和原始尺寸的特征去做融合,融合完之后通道数将原有的 384 和后来的 768 合在一起变成了 1152,通过上采样之后和原始尺寸相加,所以说图像的尺寸还是和我们前面的 1 16 \frac{1}{16} 161 一样的尺寸,那通过这样的方式我们图像编码的前向过程就完成了,
到目前为止我们已经讲过了前面 Backbone 网络的前向过程,那我们具体到 BEVDet 模型是怎么做的呢,那其实作者选用了一个 ResNet 网络和 Swin Transformer 作为提取图像特征的 Backbone 网络的,那多尺度融合网络选用的是比较经典的 FPN,我们这里说的 ResNet、Swin Transformer 和 FPN 都是可以换成其他网络模型的,非常方便。那所以这里也验证了作者的初衷,没有设计什么新的复杂的结构来构建 BEV 网络,而是通过一些成熟的可行的框架把 BEV 流程变得更完善,可扩展性非常强
OK,总结一下,图像编码部分输入是多视角图像,输出是多尺度融合后的特征,其实我们这里已经得到图像特征了,那图像特征怎么用呢,怎么把图像特征转换到 BEV 上呢,我们来接着看图像特征怎么到 3D,也就是 View-Transformer 模块所实现的功能,其框图如下所示:
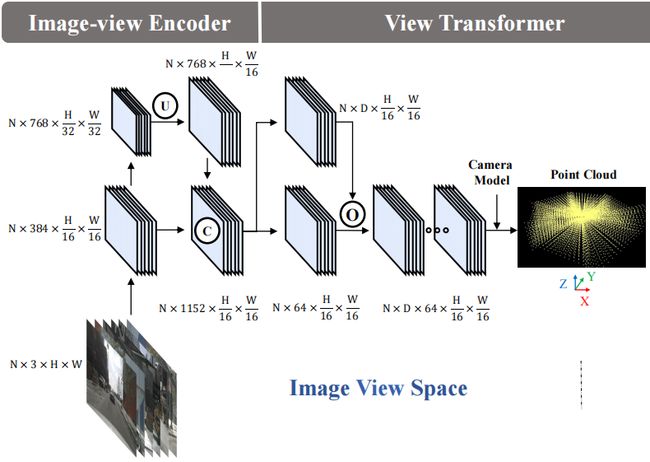
View Transformer 设计流程如下:
- 输入:多视角图像特征
- 步骤 1:深度分布预测
- 步骤 2:2D ➡ 3D 特征映射
- 输出:3D 视锥特征(伪体素)
这里又翻出我们在基础模块讲解中提到的 2D 到 3D 的特征转换,大家如果忘记了可以先去复习一下,转换的过程其实是对每个像素位置去进行深度分布的预测,会预测一系列离散深度概率,那这个概率其实作为权重乘上像素原始特征就得到了按深度分布的特征转换方法了。每一个像素它会有一条投影射线,那这条射线其实对应的是一个深度分布,把所有像素点都投影完就组成了我们所谓的 3D 空间,我们说这个空间从 3D 特征来讲其实更倾向于一种体素空间,因为跟体素的概念很类似它都是网格,所以我们可以称之为体素空间,那不过这不是真实的体素空间而是一种伪体素,是从图像投影过来的,那伪体素按照高度维度拍扁也好,卷积也好,池化也好投影到 BEV 空间,那这就是 View Transformer 输出的核心内容 BEV Feature 也就是相机的俯视特征
OK,我们回到 BEVDet,BEVDet 中 View Transformer 的流程其实和 LSS 的思路是一样的,当然 View Transformer 也可以替换成其他框架中的一些做法,同时也论证了作者论文的主旨它具有一个非常强的扩展性,任何模块都是可以替换的,View Transformer 的前向过程也非常简单,对图像 Encoder 我们编码得到的多视角图像特征先利用深度分布预测网络去预测对应的深度分布,尺寸与原特征图保持不变维度是 N × D × H 16 × W 16 N\times D\times \frac{H}{16}\times \frac{W}{16} N×D×16H×16W,我们得到特征图之后利用外积运算可以得到我们最终的特征表达,然后再利用相机的内外参数将我们得到的特征图转换到 3D 点云场景中,由此完成从 2D 空间到 3D 空间的一个转换过程
那我们经过 View Transformer 模块之后我们得到了 2D 空间到 3D 空间的转换过程,同时我们可以得到这个 3D 视锥特征,那对于这个 BEV 特征 BEVDet 其实也遵循了以前的 BEV 检测的范式用一个 BEV Encoder 进一步编码 BEV 特征,框图如下图所示:

BEV Encoder 设计流程如下:
- 输入:3D 视锥特征(伪体素)
- 步骤 1:Pooling
- 步骤 2:多尺度融合
- 输出:BEV 空间特征
从图中我们看到 BEV Encoder 和 Image-view Encoder 类似,它们的结构几乎是一样的,其实都是一个多尺度融合的网络结构,但 BEV Encoder 输入是 BEV 空间信息,因为 BEV Encoder 可以感知到深度、方向、速度等比较关键的信息,而这些信息其实对 3D 目标检测任务而言是非常关键的,那我们具体到 BEVDet 当中作者选用的是哪一个多尺度融合网络结构呢,是 ResNet+FPN 分别作为 Backbone 和 Neck 来构建 BEV Encoder,也就是说先对输入的 BEV 特征进行下采样,然后再利用 FPN 特征金字塔网络做多尺度的融合
OK,我们依然带大家走一下 BEV Encoder 的前向过程,BEV Encoder 输入的特征维度是 64 × 128 × 128 64\times 128\times128 64×128×128,64 是通道维度,128 是尺寸维度,在 Backbone 网络当中先进行特征的下采样,也就是说我们特征图的尺寸在不断减小,通道数在不断增加,我们从上图中能看到尺寸由原先的 128 × 128 128\times 128 128×128 变到了 32 × 32 32 \times 32 32×32,通道数从 64 直接变到了 512,那所以通过这样的一个操作我们对原始的 BEV 特征去进行了下采样。然后就是一个 FPN 的上采样过程,对于维度为 512 × 32 × 32 512\times32\times32 512×32×32 的特征上采样到 640 × 64 × 64 640\times64\times64 640×64×64,我们最后得到什么呢,拼接可以得到 768 × 64 × 64 768\times64\times64 768×64×64 的特征,最后再经过一个卷积层我们得到 256 × 128 × 128 256\times128\times128 256×128×128 的特征维度
那到这里整个 BEV Encoder 前向过程就走完了,输入是 3D 视锥特征输出是 BEV 空间特征,那最后将我们得到的 BEV 空间特征输入到检测头就可以完成 3D 检测任务了
那在整个训练过程当中 BEVDet 作者发现一个非常严重的过拟合问题,那为什么会产生这种问题呢,为什么会有过拟合现象呢,那什么叫过拟合呢,过拟合的意思是我们数据被过度训练了,我们在训练集中 Loss 是不断降低的,然而在测试集和验证集情况表现并不好,我们叫过拟合,那为什么会产生这种过拟合现象呢,有一方面是由于图像层面的数据增广,比如我们在原始图像上会做随机裁剪旋转等等操作,但原始图像无论怎么变我们 BEV 空间的表征是不变的,那比如图像原本映射在 BEV 某个特定的位置,经过裁剪经过翻转等操作之后它映射在 BEV 上还是应该是原来的位置而不应该产生一些变化,所以说图像层面的增广只能提升图像 Encoder 的表征能力而没有办法提升 BEV Encoder 的表征能力
那我们知道我们刚讲 Encoder 的时候讲到过图像 Encoder 和 BEV Encoder 两个网络是很类似的,它们均是由 Backbone 网络和一个 FPN Neck 组成的,然而图像 Encoder 的训练数据却是 BEV 的很多倍,那因为 BEV Encoder 的输入多视角图像变成了一个,而图像网络输入其实有 N 个相机组成,那图像 Encoder 训练了 N 个而 BEV Encoder 只训练了一个,训练数据是 BEV Encoder 的 6 倍,训练数据的不足进一步推动了 BEV Encoder 的一个过拟合问题
所以在 BEVDet 中作者将两个编码器数据增广的过程分开了,图像中的 Encoder 图像数据按照原始设定去进行数据增广,那转换到 BEV 空间之后呢,也就是说我们经过 View Transformer 之后,BEV 空间也进行相似的数据增强,那包括翻转旋转缩放等等,从而保证 BEV 上的 Encoder 也能得到充分的训练,所以在一定程度上缓解了过拟合问题
我们这里再提一下 Scale-NMS,那大家都知道目标检测任务一般会用到 NMS 操作来去除冗余框,那我们要注意什么呢,BEV 空间中不同类别的空间分布与图像视图中的空间分布是完全不同的,图像视图相机的透视成像机制使得不同类别共享相似的空间分布,那比较经典的 NMS 策略对不同类别采用相同的阈值来做的,那比如在 2D 目标检测当中,两个实例的 Bounding Box 的 IoU 是低于 0.5 的,那在 BEV 空间当中所有实例间的重叠是接近于 0,预测结果之间 IoU 分布也因类别而异
我们最常见的目标检测范式,在 BEV 空间当中有些目标占比很小,例如行人和交通锥,那冗余的框可能和 GT 之间并没有交集的,那也就是说 IoU 可能是等于 0,那这就导致了正样本和负样本空间关系如果依赖 IoU 的 NMS 其实是失效的,所以 BEVDet 利用 Scale-NMS 缓解这个问题,它怎么做呢,如下图所示:
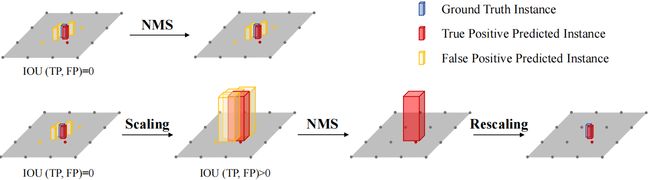
我们 Scale-NMS 输入还是我们预测结果,输出是经过 Scale-NMS 之后的结果,先根据每个对象的类别去对我们预测好的目标进行大小的放缩,比如图中的实例在尺度小的时候没有交集,如果变大了之后我们可以看到有明显的交集产生,所以说先根据每个对象类别放缩其大小,通过缩放的方式调整预测框之间的 IoU 分布,有了交集之后我们就可以和 NMS 一样去做滤除,滤除后剩下的结果我们再缩放回原始尺寸。不能说我们预测完之后就保留放缩后的尺寸大小,那比如人可能只有 1.7m,你将他缩放完之后可能变成了 4m,那我们需要一个 ReScaling 的操作把这个人再缩放回 1.7m 而不能说保留 4m 这个检测框,这显然是不对的。目标类别不同缩放因子其实也是不同的,那这个缩放因子应该缩多少呢,是对验证集进行搜索得到的,其实就是一个遍历,它去遍历看哪一个缩放因子是最有效的
3. 损失函数
OK,那我们这里把 BEVDet 和大家一起再过一遍,框图如下所示:
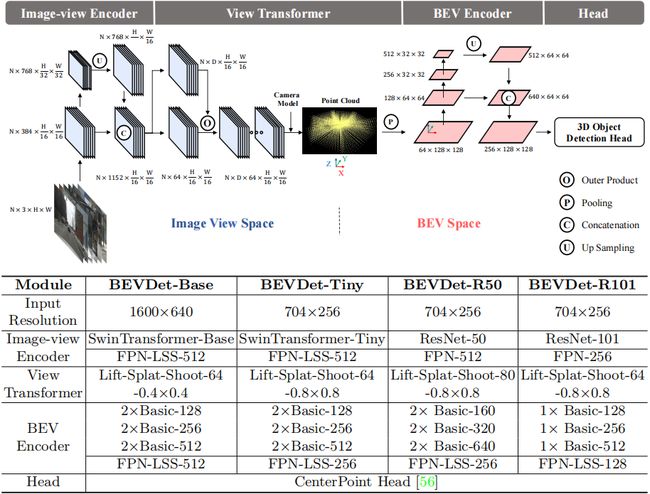
BEVDet 输入是多视角的图像,那对于 nuScenes 数据集而言视角个数就是 6,输出是 3D 检测结果,BEVDet 主要由四个模块构成,前面的图像编码通过图像 Encoder 得到多视角图像特征,图像 Encoder 由 Backbone 和多尺度的 Neck 组成,View Transformer 是 2D 到 3D 的转换器,将图像特征从 2D 映射到 3D 再投影到 BEV 空间当中,我们得到 BEV 特征之后通过 BEV Encoder 对 BEV 特征进行进一步的编码提取,其结构其实和 Image-view Encoder 一样,但它们的输入有区别,BEV Encoder 输入是 BEV 特征,Image-view Encoder 是图像特征是输入图像,那编码完之后其实我们就得到了构建好的 BEV 特征再连到 3D 检测头当中,我们自然可以得到一个比较好的预测结果
那上面的表格当中也给出了详细的 BEVDet 各个模块的网络结构,也给出了不同版本的 BEVDet 模型,那大家如果感兴趣可以稍微仔细看一下,我们这里就不再赘述了,它们的区别无非就是输入分辨率的区别,使用的图像编码网络的区别,使用的 BEV Encoder 的区别,那也就仅此而已了
4. 性能对比
那我们最后还是要看一下性能,模型无论再怎么花哨,性能不好那我们也免谈
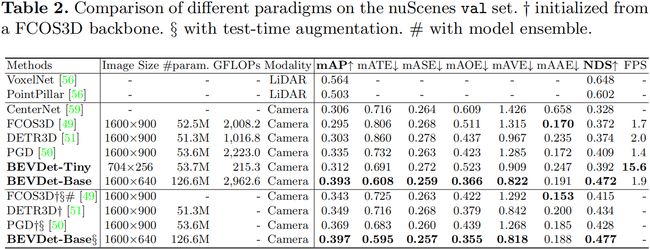
那表 2 这里其实给出了不同版本的 BEVDet 在 nuScenes 验证集上的一个性能结果,和同期算法相比 BEVDet 还是不错的,比 DETR3D 要高出 0.036,Tiny 模型高 0.006 其实可以认为是等量模型。
然后我们简单看一下消融实验,如表 4 所示,前面 IDA(Image Date Augmentation)表示图像数据的数据增强,BDA(BEV Date Augmentation)是 BEV 空间的数据增强,后面的 BE 是 BEV Encoder,我们发现如果仅仅使用图像数据增强也就是说仅仅使用 IDA 模块性能从 0.174 变到了 0.178 基本没变化,而我们仅仅使用 BEV 空间的数据增强也就是说仅仅使用 BDA 模块性能从 0.174 变到了 0.236 提升了近六个点,那大家思考下,这是为什么呢,为什么单纯图像数据增强远不如单纯 BEV 空间数据增强的性能提升呢
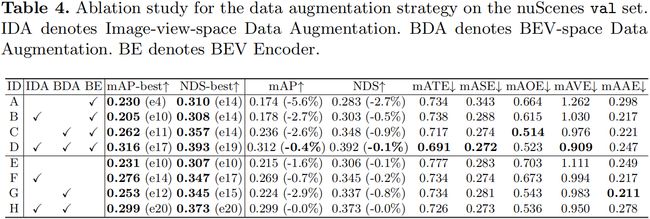
其实我们前面也提到了,这是因为图像数据的增广其实是不会影响到 BEV Encoder 的表征的,那对于 nuScenes 数据集而言本身图像 Encoder 的输入就是 BEV Encoder 的 6 倍,而无论图像怎么变化其在 BEV 空间中的表征是不变的,原本图像数据和 BEV 数据就有 6 倍的差距,图像数据再进行增广进一步拉开了这个差距,这将导致 BEV Encoder 训练的数据远远不如图像 Encoder 的训练数据从而导致严重的过拟合问题,所以我们也能看到单独的 BEV 空间的数据增强是有较大提升的,因为它平衡了图像 Encoder 训练数据和 BEV Encoder 的训练数据,此外我们还能看到图像增强和 BEV 增强一起使用即 IDA 和 BDA 一起使用时提升是最大的,说明图像数据的增广也是能带来很大增益的,不过要平衡 BEV 数据的增广。
OK,BEVDet 的内容到这里就结束了,那我们说 BEVDet 这篇工作还是偏向于工程应用性质的,它本身并没有提出任何新的模块,而是将 BEV 应用到 3D 目标检测当中,此外它的性能也是非常好的,无论是速度还是精度,也是非常值得大家去尝试的,大家感兴趣的也可以去看看它在 GitHub 上源码
总结
本次课程我们学习了一个高性能的环视 BEV 感知算法 BEVDet,BEVDet 作者本身其实并没有提出任何创新的模块而是更关注于 BEV 去做 3D 目标检测的可行性。它的完整流程也非常简单,多视角输入图像经过 Image-view Encoder 提取图像特征,图像特征经过 View Transformer 视角转换转换到 BEV 空间得到 BEV 表征,接着通过 BEV Encoder 进一步编码 BEV 特征,最后送入检测头得到检测结果。那在训练过程中 BEVDet 的作者发现 BEV Encoder 存在严重的过拟合问题,这是由于图像层面的增广并没有提升 BEV Encoder 的表征能力,无论原始图像怎么变 BEV 空间的表征是不变的,此外图像 Encoder 的输入是 6 个相机而 BEV Encoder 的输入只有一个,训练数据的不足也进一步导致了 BEV Encoder 的过拟合问题,因此 BEVDet 作者将两个 Encoder 编码器的数据增广分开来做了,保证 BEV Encoder 也能得到充分训练。另外 BEVDet 作者还提出了 Scale-NMS,由于 BEV 空间中有些目标占比很小导致冗余的框与 GT 之间并无交集,在进行 NMS 时无法充分过滤掉这些冗余的框,于是 BEVDet 的作者提出了 Scale-NMS 先将每个对象类别先进行一定大小的缩放再进行 NMS 之后 rescaling 回来。
OK,以上就是 BEVDet 的全部内容了,下节我们一起去学习下 BEVDet 的延伸 BEVDet4D,敬请期待
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- [1 ] Huang et al. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view