ElasticSearch搜索相关性及打分的相关原理
文章目录
- 一、相关性和打分简介
- 二、TF-IDF得分计算公式
- 三、BM25(Best Matching 25)
- 四、使用explain查看TF-IDF
- 五、通过Boosting控制相关度
一、相关性和打分简介

举个例子来说明:
-
假设有一个电商网站,用户在搜索框中输入了关键词"手机",然后触发了搜索操作。Elasticsearch会根据用户的查询,在索引中找到所有包含"手机"的文档,并按照相关性对这些文档进行打分。
-
相关性评分的目的是确定搜索结果的质量和排序。相关性评分越高,表示搜索结果与用户查询的匹配程度越好。
-
例如,对于一个包含"手机"关键词的文档,如果它在标题、描述和其他字段中多次出现"手机",那么它的相关性评分可能会很高。而对于一个只在描述中出现一次"手机"的文档,它的相关性评分可能会较低。
-
在Elasticsearch 5.0版本之前,Elasticsearch使用的是TF-IDF(Term Frequency-Inverse Document Frequency)算法来进行相关性判断和打分。
-
TF-IDF算法是一种经典的信息检索算法,它考虑了词频(Term Frequency)和逆文档频率(Inverse Document Frequency)
词频表示词在文档中的出现次数
逆文档频率表示词在整个文档集合中的普遍程度。 -
根据TF-IDF算法,搜索词在文档中出现的次数越多,这个词对文档的相关性贡献越大。但是,如果这个词在整个文档集合中出现的次数越多,它对文档的相关性贡献越小,因为它在整个集合中普遍存在,不足以区分文档的重要性。
-
从Elasticsearch 5.0版本开始,默认使用了BM25(Best Matching 25)算法来进行相关性判断和打分。BM25算法在计算相关性得分时,考虑了文档的长度和搜索词的位置等因素。
-
BM25算法相对于TF-IDF算法更为先进和准确,它在实际应用中表现更好。所以,对于Elasticsearch 5.0及以后的版本,推荐使用BM25算法来进行相关性判断和打分。
二、TF-IDF得分计算公式
TF-IDF(Term Frequency-Inverse Document Frequency)得分计算公式是一种用于衡量词语在文档集合中重要性的指标。其计算公式如下:
TF-IDF = TF * IDF
其中,TF(Term Frequency)表示词语在文档中的频率,可以通过以下公式计算:
TF = (词语在文档中出现的次数) / (文档中总词语数)
IDF(Inverse Document Frequency)表示逆文档频率,可以通过以下公式计算:
IDF = log((文档集合中文档总数) / (包含词语的文档数))
TF-IDF得分越高,表示词语在文档集合中越重要。它的核心思想是:当一个词语在某个文档中频繁出现(高TF值),同时在其他文档中较少出现(高IDF值)时,该词语对于该文档的重要性较高。
TF-IDF常用于信息检索、文本分类、关键词提取等自然语言处理任务中。
三、BM25(Best Matching 25)
BM25(Best Matching 25)算法可以被视为对TF-IDF算法的改进和扩展。BM25算法是一种用于信息检索的评分算法,相较于TF-IDF算法,它在一些方面进行了改进,以提高检索结果的质量。

主要的改进包括以下几个方面:
-
考虑文档长度:TF-IDF算法仅仅考虑了词频,对文档长度没有考虑。而BM25算法引入了文档长度因子,可以更好地处理文档长度不同的情况。
-
调整词频饱和度:TF-IDF算法中,词频的值会随着出现次数的增加而线性增长,容易导致过度强调高频词语。而BM25算法使用了对数函数来调整词频的饱和度,使得高频词语的权重增长趋于饱和。
-
引入文档频率饱和度:BM25算法引入了文档频率的饱和度因子,用于调整文档频率的影响。这可以避免过度强调出现在大多数文档中的常见词语。
-
综上所述,BM25算法在TF-IDF算法的基础上进行了改进,更加准确地评估了词语在文档集合中的重要性,提高了信息检索的效果。
四、使用explain查看TF-IDF
通过使用Elasticsearch的Explain API,你可以查看特定查询的TF-IDF得分。以下是一个示例,展示如何使用Explain API来计算TF-IDF得分:
- 首先,在Kibana的Dev Tools中执行以下命令,创建一个新的索引并索引一些文档数据:
PUT my_index
{
"mappings": {
"properties": {
"text": {
"type": "text"
}
}
}
}
POST my_index/_doc
{
"text": "This is the first document."
}
POST my_index/_doc
{
"text": "This document is the second document."
}
POST my_index/_doc
{
"text": "And this is the third one."
}
POST my_index/_doc
{
"text": "Is this the first document?"
}
执行如下:

2. 然后,使用Explain API来查看TF-IDF得分。在Kibana的Dev Tools中执行以下命令:
GET my_index/_search
{
"explain": true,
"query": {
"match": {
"text": "this is the first document"
}
}
}
以上命令将返回查询结果,并在每个匹配的文档中提供一个_explanation字段,其中包含有关得分计算的详细信息,包括TF-IDF得分。

请注意,Explain API返回的_explanation字段中包含了与得分相关的详细信息,如词频、文档频率、字段长度等。你可以通过解析_explanation字段来提取和分析TF-IDF得分。
3. explain内容如下:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.4186639,
"hits" : [
{
"_shard" : "[my_index][0]",
"_node" : "NkTFrxzGQuOf4zelToSeKQ",
"_index" : "my_index",
"_type" : "_doc",
"_id" : "08FDOokBF8lAViln2DRj",
"_score" : 1.4186639,
"_source" : {
"text" : "This is the first document."
},
"_explanation" : {
"value" : 1.4186639,
"description" : "sum of:",
"details" : [
{
"value" : 0.10943023,
"description" : "weight(text:this in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10943023,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10943023,
"description" : "weight(text:is in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10943023,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10943023,
"description" : "weight(text:the in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10943023,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.7199211,
"description" : "weight(text:first in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7199211,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.3704521,
"description" : "weight(text:document in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.3704521,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.35667494,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
},
{
"_shard" : "[my_index][0]",
"_node" : "NkTFrxzGQuOf4zelToSeKQ",
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1sFEOokBF8lAVilnADS4",
"_score" : 1.4186639,
"_source" : {
"text" : "Is this the first document?"
},
"_explanation" : {
"value" : 1.4186639,
"description" : "sum of:",
"details" : [
{
"value" : 0.10943023,
"description" : "weight(text:this in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10943023,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10943023,
"description" : "weight(text:is in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10943023,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10943023,
"description" : "weight(text:the in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10943023,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.7199211,
"description" : "weight(text:first in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7199211,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.3704521,
"description" : "weight(text:document in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.3704521,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.35667494,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.472103,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
},
{
"_shard" : "[my_index][0]",
"_node" : "NkTFrxzGQuOf4zelToSeKQ",
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1MFDOokBF8lAViln6TSq",
"_score" : 0.78294927,
"_source" : {
"text" : "This document is the second document."
},
"_explanation" : {
"value" : 0.78294927,
"description" : "sum of:",
"details" : [
{
"value" : 0.10158265,
"description" : "weight(text:this in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10158265,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.43824703,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10158265,
"description" : "weight(text:is in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10158265,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.43824703,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10158265,
"description" : "weight(text:the in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10158265,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.43824703,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.47820133,
"description" : "weight(text:document in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.47820133,
"description" : "score(freq=2.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.35667494,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.6094183,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
},
{
"_shard" : "[my_index][0]",
"_node" : "NkTFrxzGQuOf4zelToSeKQ",
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1cFDOokBF8lAViln9jS-",
"_score" : 0.30474794,
"_source" : {
"text" : "And this is the third one."
},
"_explanation" : {
"value" : 0.30474794,
"description" : "sum of:",
"details" : [
{
"value" : 0.10158265,
"description" : "weight(text:this in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10158265,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.43824703,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10158265,
"description" : "weight(text:is in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10158265,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.43824703,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.10158265,
"description" : "weight(text:the in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.10158265,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.43824703,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
}
]
}
}
五、通过Boosting控制相关度
在搜索引擎和信息检索领域中,Boosting可以用来提升或降低文档的相关度得分,以便更好地满足用户的查询需求。
Boosting可以在不同的层次上进行,包括查询级别的Boosting和文档级别的Boosting。
1、查询级别的Boosting:在查询级别上,可以使用Boosting来提高或降低特定查询的相关度得分。这种Boosting通常通过设置查询子句的权重或使用特定的查询类型来实现。例如,可以使用更高的权重来突出某些关键词,或使用更复杂的查询类型(如布尔查询、模糊查询)来调整相关度得分。
2、文档级别的Boosting:在文档级别上,可以使用Boosting来提高或降低特定文档的相关度得分。这种Boosting通常通过为文档定义一个额外的因子或属性来实现。例如,可以为某些文档设置更高的权重,以便它们在搜索结果中排名更靠前,或者可以为某些文档设置更低的权重,以便它们在搜索结果中排名更靠后。
通过使用Boosting技术,可以根据具体需求和优先级来调整搜索结果的相关度得分,从而提供更好的用户体验和更精确的搜索结果。
以下是一个使用boost参数的示例:
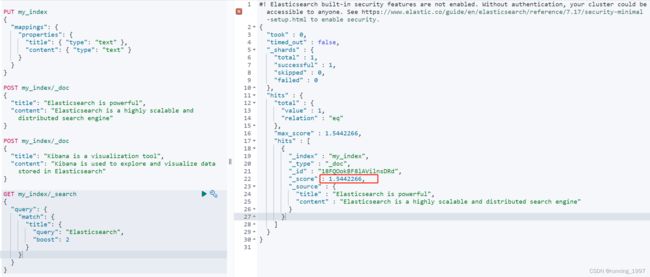
1、首先,使用Kibana的Dev Tools或者其他方式创建一个索引,并添加一些文档。例如,创建一个名为my_index的索引,并添加一些包含title和content字段的文档:
PUT my_index
{
"mappings": {
"properties": {
"title": { "type": "text" },
"content": { "type": "text" }
}
}
}
POST my_index/_doc
{
"title": "Elasticsearch is powerful",
"content": "Elasticsearch is a highly scalable and distributed search engine"
}
POST my_index/_doc
{
"title": "Kibana is a visualization tool",
"content": "Kibana is used to explore and visualize data stored in Elasticsearch"
}
2、然后,执行一个带有boost参数的查询来调整字段的相关度得分。例如,执行一个查询,将title字段的相关度得分提高两倍:
GET my_index/_search
{
"query": {
"match": {
"title": {
"query": "Elasticsearch",
"boost": 2
}
}
}
}
在上述查询中,我们使用了match查询来搜索包含关键词"Elasticsearch"的文档。
通过在match查询中设置boost参数为2,我们将title字段的相关度得分提高了两倍。
这意味着包含关键词"Elasticsearch"的文档在结果中会更加相关。
- 当boost大于1时,提高字段的相关度得分,使其在结果排序中具有更高的权重。
- 当0 < boost < 1时,降低字段的相关度得分,使其在结果排序中具有较低的权重。
- 当boost小于0时,会为字段贡献负分,可能导致字段在结果排序中的得分变为负数。