提升R语言分析效率:如何精准定位CRAN中你想要的高质量R包?
对于数据科学家和R语言爱好者来说,寻找合适的R包以满足特定需求是一项重要但往往令人困惑的任务。CRAN(Comprehensive R Archive Network)拥有数以万计的R包,涵盖了数据处理、可视化、建模和其他众多领域。当你在处理数据分析、可视化或其他相关任务时,可能需要寻找特定功能的R包。在这个庞大的R包宝库中,找到目标R包就像在大海捞针一般困难。
读者可能会遇到以下几种困惑:
无法确定关键词:在查找特定功能的R包时,可能难以确定恰当的关键词。一些关键词可能过于宽泛,导致搜索结果过多;而其他关键词可能过于狭义,无法找到相关R包。
信息过载:当使用CRAN进行检索时,可能会遇到大量的搜索结果。逐一查看这些结果以了解它们的功能和用途将花费大量时间和精力。
难以评估R包质量:在搜索结果中,可能难以确定哪个R包最适合自己的需求。同时,由于缺乏关于下载量和更新日期等方面的信息,难以评估这些R包的质量和可靠性。
结果排序不合理:CRAN的默认搜索结果排序可能并不符合用户的期望,这会导致有用的R包被埋没在大量不相关或质量较低的结果中。
因此,为了解决这些困惑,我们需要一款能够根据关键词快速、准确地检索到相关R包的工具,同时提供一定程度的结果筛选和排序功能,帮助读者更高效地找到目标R包。
本教程的重点包括:
Ø如何获取CRAN中所有R包的信息及下载量,借助网页抓取技术从CRAN网页提取数据。
Ø提供了一个名为Find_CRAN_pkg的自定义函数,通过输入关键词,您可以迅速找到与关键词相关的R包。
Ø详细解释了函数的各个参数,包括:关键词、是否区分大小写、返回结果的数量,以及是否在R包描述中搜索关键词。
首先,我们需要载入本次分析所需的R包。
# devtools::install_github("metacran/cranlogs")
rm(list=ls())
pacman::p_load(tidyverse,cranlogs,rvest)我们将从CRAN网站抓取所有可用R包的列表,包括它们的基本信息及下载量。在此过程中,我们利用了网页抓取技术,通过rvest包从CRAN网页上提取所需数据。
CRAN抓取所有可用R包:
url <- "https://cran.r-project.org/web/packages/available_packages_by_date.html"
packages <- url %>%
read_html() %>%
html_table(fill = TRUE) %>%
.[[1]]
head(packages)
接下来需要统计R包被下载的次数,我们统计1周时间,所有CRAN包的下载量,下载速度慢,这里直接载入下载好的数据。
载入下载好的数据:
load('r.rda')在获得所有R包信息后,我定义了一个名为Find_CRAN_pkg的函数,它可以根据您输入的关键词,协助您找到相关R包。
定义主函数Find_CRAN_pkg:
# 定义函数
Find_CRAN_pkg <- function(char, ignore.case = TRUE, top = 10, Title = TRUE){
if(Title){
if(ignore.case){
# 查询包描述文件
a1 <- grep(char, d$Title, ignore.case = TRUE, value = TRUE)
d1 <- d %>%
filter(Title %in% unique(a1))
# 查询包名
a2 <- grep(char, d$Package, ignore.case = TRUE, value = TRUE)
d2 <-
d %>%
filter(Package %in% a2)
rbind(d1, d2) %>%
.[!duplicated(.$Package),] %>%
arrange(desc(count)) %>%
head(top)
}else{
# 查询包描述文件
a1 <- grep(char, d$Title, ignore.case = FALSE, value = TRUE)
d1 <- d %>%
filter(Title %in% unique(a1))
# 查询包名
a2 <- grep(char, d$Package, ignore.case = FALSE, value = TRUE)
d2 <-
d %>%
filter(Package %in% a2)
rbind(d1, d2) %>%
.[!duplicated(.$Package),] %>%
arrange(desc(count)) %>%
head(top)
}
}else{
if(ignore.case){
# 查询包描述文件
a1 <- grep(char, d$Title, ignore.case = TRUE, value = TRUE)
d1 <- d %>%
filter(Title %in% unique(a1))
# 查询包名
a2 <- grep(char, d$Package, ignore.case = TRUE, value = TRUE)
d2 <-
d %>%
filter(Package %in% a2)
rbind(d1, d2) %>%
.[!duplicated(.$Package),] %>%
arrange(desc(count)) %>%
head(top) %>%
select(-4)
}else{
# 查询包描述文件
a1 <- grep(char, d$Title, ignore.case = FALSE, value = TRUE)
d1 <- d %>%
filter(Title %in% unique(a1))
# 查询包名
a2 <- grep(char, d$Package, ignore.case = FALSE, value = TRUE)
d2 <-
d %>%
filter(Package %in% a2)
rbind(d1, d2) %>%
.[!duplicated(.$Package),] %>%
arrange(desc(count)) %>%
head(top) %>%
select(-4)
}
}
}该函数的主要参数包括:
-
char:您输入的关键词。
-
ignore.case:是否区分大小写,默认为TRUE,即不区分大小写。
-
top:返回结果的数量,默认为10。
-
Title:是否在R包描述中搜索关键词,默认为TRUE。
以下是一些使用示范:
# 查询与绘制heatmap相关的R包,返回前30个结果
Find_CRAN_pkg('heatmap')
可以看到:返回的结果中列出了与heatmap有关的R包的名称、下载量(一周)、上次更新日期和功能描述;默认输出前10个R包,根据下载量进行降序排列。
查询与机器学习有关的R包:
Find_CRAN_pkg('machine learning')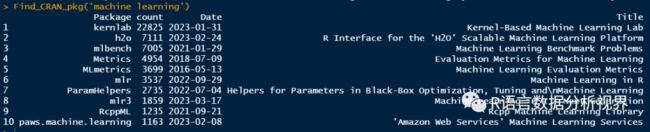
# 查询ggplot2及其庞大的拓展家族:下载量前100
Find_CRAN_pkg('ggplot2', top = 100) %>% .[,1]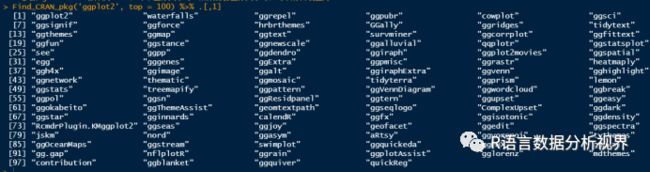
# 查询与ROC相关的R包,返回前30个结果
Find_CRAN_pkg('ROC', top = 20)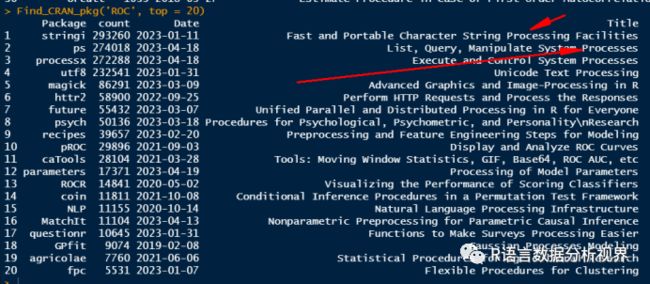
细心的话你会发现“roc”正好是英文单次“process”的字段,因此找到的前面几个包,其实与ROC分析并没有关系,这时就需要借助 ignore.case = FALSE参数,我们只查找大写的“ROC”内容
# 区分大小写查询与ROC相关的R包,返回前20个结果
Find_CRAN_pkg('ROC', ignore.case = FALSE, top = 20)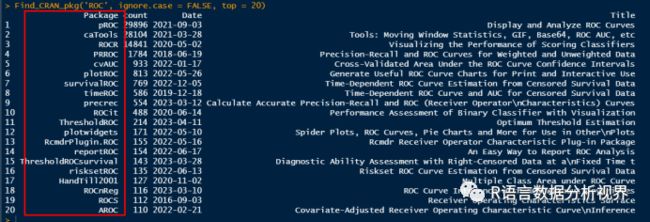
这时可以看到,这些都是ROC分析过程中被大家广泛使用的R包,更多有意思的功能期待你的发现!
下期我们将继续介绍Bioconductor源上面所有R包的详细查询方法,敬请期待~~~
创作不易,喜欢本期内容的童鞋们请关注我们的微信公众号,后台留言免费取得本期代码和数据~~