Java的日志框架之Logback
前言
在Java的日志系统里面,有两个概念,一个叫做日志框架,如我们熟悉的Logback, Log4j, Log4j2, JDK自带的java.util.logging等;一个叫做日志门面,如Slf4j(Simple Logging Facade For Java)。
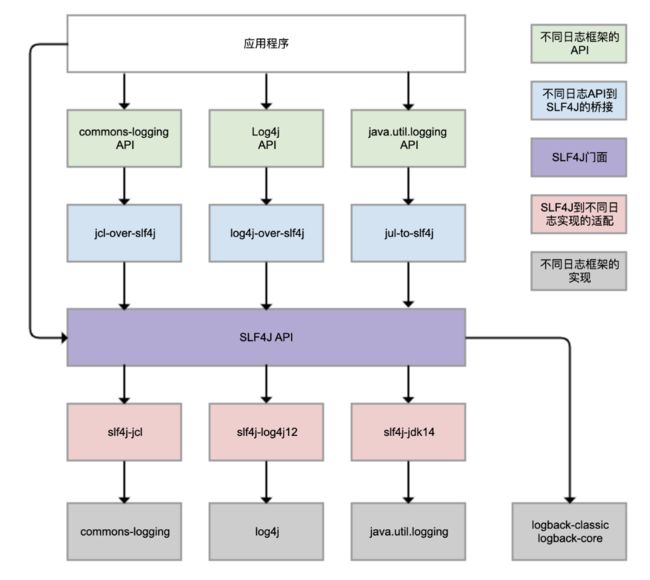
门面可以理解为一个统一的记录日志的接口,但后面具体产生日志写到文件等等的工作是由不同的日志框架来实现,有的需要在slf4j提供的api到日志框架中增加一个适配器,有的像logback直接实现了slf4j,不用另外适配,如下图:
在代码中记录日志非常方便,如下:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HelloWorld{
private static final Logger logger = LoggerFactory.getLogger(HelloWorld.class);
public static void main(String[] args) {
logger.info("hello rachel !");
}
}
如果项目中使用了lombok的@Slf4j,使用变成如下:
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class HelloWorld{
public static void main(String[] args) {
log.info("hello rachel !");
}
}
@Slf4j会自动生成如下代码:
private static final org.slf4j.Logger log = org.slf4j.LoggerFactory.getLogger(HelloWorld.class);
logback执行记录日志的过程图:
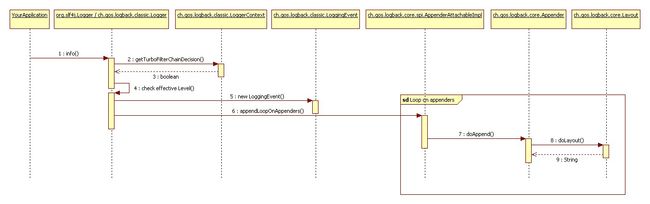
logback构建在三个主要的类上:Logger,Appender和Layouts,接下来将一一介绍。
Logger
Logger有两个非常重要的属性,一个是命名(name),一个是层级(level)。
命名
Logger的命名是大小写敏感的,且通过.来构建继承关系, 例如名为com.foo的logger是名为com.foo.bar的logger的父级。
root logger是最高层级的logger。
名字相同则为同一个logger实例,使用类的全限定名对logger进行命名是最好的方式。
层级
logger的层级有以下几个等级,从高级别到低级别依次是
ERROR
> WARN
> INFO
> DEBUG
> TRACE
可以给每个logger指定一个等级,如果没有指定等级,那么logger会继承最近的父级的等级,一个logger的有效等级是从自身一直回溯到root logger。即,若父级,父级的父级...都没有指定等级,该logger最后会使用root logger的等级作为自己的等级。root logger 默认的层级是DEBUG。
基本规则
logger的等级和我们代码中指定的日志等级共同作用,决定该日志是否会被打印,这点是非常基础和重要的。
即日志的打印级别为 p,Logger 实例的级别为 q,如果 p >= q,则该条日志可以打印出来。
我们代码中可以通过log.info(),log.debug()等等指定日志等级,但如果该logger的有效层级大于了指定的等级,则日志不会打印出来。
配置
我们可以在logback.xml中配置logger, 例如:
name和level就是我们上述的命名和层级,挂载的Appender,将在下面介绍。
Appender
Appender可以理解为一个日志输出的目的地。一个logger可以有多个appender,即这条日志将会被输出到不同文件(假如目的地是文件)。
叠加性规则
appender有一个属性叫做additivity,默认是true。
即, 由logger L 打印的日志会遍历L和它父级中的所有appender, 都会从这些appender输出。
如果 L 的某个父级P, 设置了additivity = fasle, 那么logger L 打印的日志只会在L到P之间(L <= x <= P)的所有logger的appender输出,P级以上appender不会输出。
类型
ConsoleAppender
ConsoleAppender是将日志输出到控制台,通过System.out或者System.err来进行输出。
| 属性名 | 类型 | 描述 |
|---|---|---|
| encoder | Encoder | 见 OutputStreamAppender 属性 |
| target | String | System.out 或 System.err。默认为 System.out |
| withJansi | boolean | withJansi 的默认值为 false。设置 withJansi 为 true 可以激活 Jansi 在 windows 使用 ANSI 彩色代码。在 windows 上如果设置为 true,你应该将 org.fusesource.jansi:jansi:1.9 这个 jar 包放到 classpath 下。基于 Unix 实现的操作系统,像 Linux、Max OS X 都默认支持 ANSI 才彩色代码。 |
FileAppender
FileAppender是将日志输出到文件,通过file来指定目标文件。
| 属性名 | 类型 | 描述 |
|---|---|---|
| append | boolean | 如果为 true,日志事件会被追加到文件中,否则的话,文件会被截断。默认为 true |
| encoder | Encoder | 参见 OutputStreamAppender 的属性 |
| file | String | 要写入文件的名称。如果文件不存在,则新建。在 windows 平台上,用户经常忘记对反斜杠进行转义。例如,c:\temp\test.log 不会被正确解析,因为 '\t' 是一个转义字符,会被解析为一个 tab 字符 (\u0009)。正确的值应该像:c:/temp/test.log 或者 c:\\temp\\test.log。没有默认值。 |
| prudent | boolean | 在严格模式下,FileAppender 会将日志安全的写入指定文件。即使在不同的 JVM 或者不同的主机上运行 FileAppender 实例。默认的值为 false。严格模式可以与 RollingFileAppender 结合使用。严格模式也意味着 append 属性被自动设置为 true。严格模式依赖排他文件锁。实验证明,文件锁大概是写入日志事件成本的 3 倍,应该避免使用严格模式。 |
RollingFileAppender
RollingFileAppender继承自FileAppender, 是输出到日志文件且具有轮转功能。与轮转相关的有两个子属性,一个是RollingPolicy一个是TriggeringPolicy。这两个必须同时设置,如果RollingPolicy也实现了TriggeringPolicy接口,那只需要设置RollingPolicy。
| 属性名 | 类型 | 描述 |
|---|---|---|
| file | String | 参见 FileAppender |
| append | boolean | 参见 FileAppender |
| encoder | Encoder | 参见 OutputStreamAppender |
| rollingPolicy | RollingPolicy | 当轮转发生时,指定 RollingFileAppender 的行为。下面将会详细说明 |
| triggeringPolicy | TriggeringPolicy | 告诉 RollingFileAppender 什么时候发生轮转行为。下面将会详细说明 |
| prudent | boolean | / |
TimeBasedRollingPolicy
TimeBasedRollingPolicy即基于时间的轮转策略,它实现了RollingPolicy和TriggeringPolicy的接口,且必须配置一个强制属性fileNamePattern,TimeBasedRollingPolicy配置的属性如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| fileNamePattern | String | 该属性定义了轮转时的属性名。它的值应该由文件名加上一个 %d 的占位符。%d 应该包含 java.text.SimpleDateFormat 中规定的日期格式。如果省略掉这个日期格式,那么就默认为 yyyy-MM-dd。轮转周期是通过 fileNamePattern 推断出来的。 注意:可以选择对 RollingFileAppender(TimeBasedRollingPolicy 的父类)中的 file 属性进行设置,也可以忽略。通过设置 FileAppender 的 file 属性,你可以将当前活动日志的路径与归档日志的路径分隔开来。当前日志永远会是通过 file 指定的文件。它的名字不会随着时间的推移而发生变化。但是,如果你选择忽略 file 属性,当前活动日志在每个周期内将会根据 fileNamePattern 的值变化。稍后的例子将会说明这一点。 %d{} 中的日期格式将会遵循 java.text.SimpleDateFormat 中的约定。斜杆 '/' 或者反斜杠 '' 都会被解析成目录分隔符。 foo.%d.log/foo.%d{yyyy-MM-dd}.log - 每天轮转 foo.%d{yyyy/MM}.log - 每月轮转 foo.%d.gz - 每天轮转归档,0点压缩 |
| maxHistory | int | 这个可选的属性用来控制最多保留多少数量的归档文件,将会异步删除旧的文件。比如,你指定按月轮转,指定 maxHistory = 6,那么 6 个月内的归档文件将会保留在文件夹内,大于 6 个月的将会被删除。注意:当旧的归档文件被移除时,当初用来保存这些日志归档文件的文件夹也会在适当的时候被移除。 |
| totalSizeCap | int | 这个可选属性用来控制所有归档文件总的大小。例如磁盘100G,可以设置一个小于100G的日志大小限制。当达到这个大小后,旧的归档文件将会被异步的删除。使用这个属性时还需要设置 maxHistory 属性。而且,maxHistory 将会被作为第一条件,该属性作为第二条件。 |
| cleanHistoryOnStart | boolean | 如果设置为 true,那么在 appender 启动的时候,归档文件将会被删除。默认的值为 false。 归档文件的删除通常在轮转期间执行。但是,有些应用的存活时间可能等不到轮转触发。对于这种短期应用,可以通过设置该属性为 true,在 appender 启动的时候执行删除操作。 |
SizeAndTimeBasedRollingPolicy
这个策略是在时间轮转的策略上多了一个轮转大小限制,除了%d以外还需要%i,这两个占位符都是强制要求的。在当前时间还没有达到轮转周期前,但日志文件达到了maxFileSize指定的大小,会进行归档,索引递增从0开始
| 属性名 | 类型 | 描述 |
|---|---|---|
| maxFileSize | int | 日志文件达到size将会进行归档 |
AsyncAppender
AsyncAppender异步地打印ILoggingEvent,仅为一个事件调度器,必须调用其他的appender来完成操作。
| 属性名 | 类型 | 描述 |
|---|---|---|
| queueSize | int | 队列的最大容量,默认为 256 |
| discardingThreshold | int | 默认,当队列还剩余 20% 的容量时,会丢弃级别为 TRACE, DEBUG 与 INFO 的日志,仅仅只保留 WARN 与 ERROR 级别的日志。想要保留所有的事件,可以设置为 0 |
| includeCallerData | boolean | 获取调用者的数据相对来说比较昂贵。为了提高性能,默认情况下不会获取调用者的信息。默认情况下,只有像线程名或者 MDC 这种"便宜"的数据会被复制。设置为 true 时,appender 会包含调用者的信息 |
| maxFlushTime | int | 根据所引用 appender 队列的深度以及延迟, AsyncAppender 可能会耗费长时间去刷新队列。当 LoggerContext 被停止时, AsyncAppender stop 方法会等待工作线程指定的时间来完成。使用 maxFlushTime 来指定最大的刷新时间,单位为毫秒。在指定时间内没有被处理完的事件将会被丢弃。这个属性的值的含义与 Thread.join(long) 相同 |
| neverBlock | boolean | 默认为 false,在队列满的时候 appender 会阻塞而不是丢弃信息。设置为 true,appender 不会阻塞你的应用而会将消息丢弃 |
AsyncAppender & FileAppender
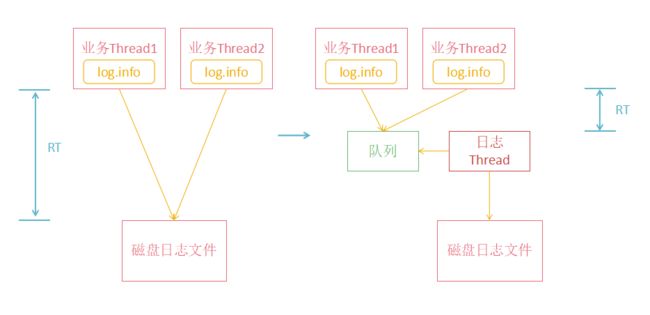
系统设计中常常会有cache和buffer的设计,cache是因为设备的速度差,高速设备访问低速设备造成的高速设备的等待,两者直接加入cache; buffer是化零为整,少量多次变成多量少次。
FileAppender属于buffer级方案,AsyncAppender属于cache级方案。
FileAppender内部有缓存buffer, buffer读写都加锁,logger写buffer, buffer写盘。AsyncAppender把日志写盘变为日志写内存,减少日志的RT(Response Time)。
配置:
mylog.txt
mylog-%d{yyyy-MM-dd}.%i.txt
100MB
60
20GB
%msg%n
0
512
Encoder & Layout
Encoder
encoder是appender的一个属性,它将日志事件转换为字节数组,同时将字节数据写入到一个OutputStream中。
Layout
layout是将日志事件转化为字符串。
PatternLayout
常见的转换字符
| 转换字符 | 效果 |
|---|---|
| %logger | 生成logger名称,假设logger的名字为com.hello.rachel.service.SayService 则: %logger{0} ---> SayService %logger{10} ---> c.h.r.s.SayService %logger{25} ---> c.h.rachel.service.SayService |
| %d{pattern} %date |
生成日期: %d ---> 2022-07-05 19:00:00,000 |
| %caller | 生成日志调用者的位置信息,依赖JVM实现 %caller{2} ---> 0 [main] DEBUG - logging statement Caller+0 at mainPackage.sub.sample.Bar.sampleMethodName(Bar.java:22) Caller+1 at mainPackage.sub.sample.Bar.createLoggingRequest(Bar.java:17) |
| %line/%L | 生成日志请求所在的行号 |
| %m/%msg/%message | 生成日志具体信息 |
| %n | 行分隔符 |
| %p/%level | 生成日志级别 |
| %t/%thread | 生成日志事件的线程名 |
| %X{key:-defaultVal} /%mdc |
生成日志事件线程的MDC内容 |
| %replace(p) | 在子模式p产生的字符中,将所有出现正则表达式r的地方替换成t |
格式修改器
可以使用格式修改器对数据字段进行对齐;第一个可选的为减号(-)为左对齐;然后是最小字段宽度,如果字段包含很好数据会padding(默认填充左边,右对齐)
例如%-30logger(%date %level) [%thread] 将会出现thread之后的日志信息左对齐的样式
着色
可以使用圆括号分组对子模块进行着色,如%blue(...), %cyan(...), %magenta(...)等等;
注,windows上appender需要添加
MDC
在分布式系统中通常需要用不同的线程处理不同的客户端,为了给每个客户端请求打上唯一的标记,用户可以将上下文信息放到MDC(Mapped Diagnostic Context, 诊断上下文)中。MDC中只包含静态方法,让开发人员可以在MDC中放置信息,然后通过特定的logback组件获取。注意,子线程不会自动继承父线程的MDC。
package org.slf4j;
public class MDC {
// 将上下文的值作为 MDC 的 key 放到线程上下的 map 中
public static void put(String key, String val);
// 通过 key 获取上下文标识
public static String get(String key);
// 通过 key 移除上下文标识
public static void remove(String key);
// 清除 MDC 中所有的 entry
public static void clear();
}
在PatternLayout中的%X{key}就可以获取MDC中的值。
参考资料
logback 中文 tutorial
日志采坑总结
log4j2 英文 tutorial
log4j2 中文 tutorial
logback性能优化
动态修改log等级