Stable Diffusion 微调及推理优化实践指南
随着 Stable Diffsuion 的迅速走红,引发了 AI 绘图的时代变革。然而对于大部分人来说,训练扩散模型的门槛太高,对 Stable Diffusion 进行全量微调也很难入手。由此,社区催生了一系列针对 Stable Diffusion 的高效微调方案,在保留原模型泛化能力的同时,实现自定义风格的融合,最关键的是,操作简单且资源消耗量低。
本文将介绍 Stable Diffsuion 微调方案选型,以及如何使用 Dreambooth 和 LoRA 进行微调实践,最后,我们会使用腾讯云 TACO 对微调后的 Dreambooth 和 LoRA 模型进行推理优化。
Stable Diffusion 微调
Stable Diffusion 微调的目标,是将新概念注入预训练模型,利用新注入的概念以及模型的先验知识,基于文本引导条件生成自定义图片。目前主流训练 Stable Diffusion 模型的方法有 Full FineTune、Dreambooth、Text Inversion 和 LoRA,不同方法的实现逻辑和使用场景不同,选型简单对比如下:
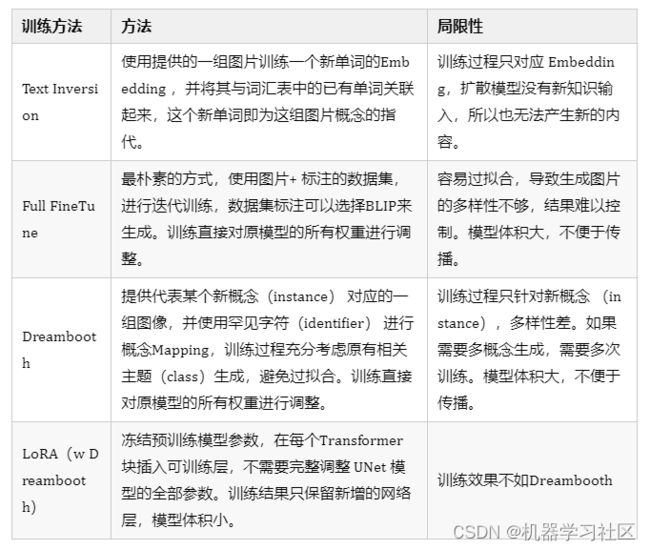
需要注意的是,LoRA 是一种加速训练的方法,Stable Diffusion 从大语言模型微调中借鉴而来,可以搭配 Full FineTune 或 Dreambooth 使用。针对上述几种训练方法,我们在 A10-24G 机型上进行测试,5-10张训练图片,所需资源和时长对比如下:

接下来,我们重点介绍如何使用 Dreambooth 和 Lora(w Dreambooth) 对 Stable Diffusion 模型进行微调。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术答疑、交流群!想要进交流群、需要资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
资料1
资料2

Dreambooth
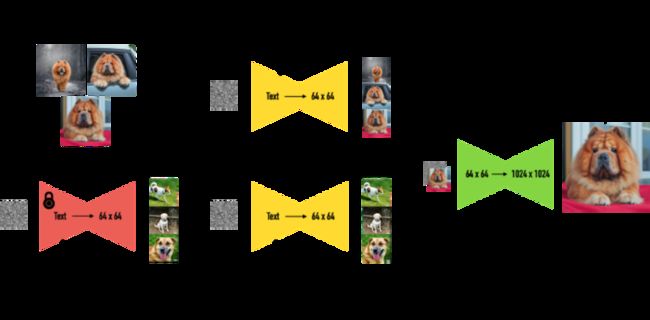
Dreambooth 用一个罕见字符(identifier)来代表训练图片的概念,对 UNet 模型的所有权重进行调整。这里选择罕见字符(identifier),是希望原模型没有该 identifier 的先验知识,否则容易在模型先验和新注入概念(instance)间产生混淆。
对比 Full FineTune,虽然都会调整原模型的所有权重,但 Dreambooth 的创新点在于,它会使用 Stable Diffusion 模型去生成一个已有相关主题(class) 的先验知识,并在训练中充分考虑原 class 和新 instance 的 prior preservation loss,从而避免新 instance 图片特征渗透到其他生成里。
另外,训练中加入一个已有的相关主题(class)的描述,可以将 instance 和 class 进行绑定,这样新 instance 也可以使用到 class 对应的先验知识。
我们使用 Huggingface 提供的训练代码,准备5-10张图片,在A10上使用以下脚本启动训练:
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--mixed_precision=fp16 \
--instance_prompt="a photo of az baby" \
--class_prompt="a photo of baby" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
其中 --instance_data_dir 为新 instance 的图片目录,在 --instance_prompt 参数里设置对应的 identifier,在 --class_prompt 设置相关 class 描述。训练代码
训练集图片示例:

训练完毕后,输入“a photo of az baby”,可以看到生成的图片具备训练集人物特征。

训练好的模型,如果需要在 Stable Diffusion Web UI 上使用,先通过脚本进行转换,输出ckpt或者safetensors格式,再放入 $HOME/stable-diffusion-webui/models/Stable-diffusion 目录。脚本链接
python ../scripts/convert_diffusers_to_original_stable_diffusion.py --model_path ./dreambooth_baby --checkpoint_path dreambooth_baby.safetensors --use_safetensors
LoRA(w Dreambooth)
LoRA(Low-Rank Adaptation of Large Language Models ) 是一种轻量级的微调方法,通过少量的图片训练出一个小模型,然后和基础模型结合使用,并通过插层的方式影响模型结果。
LoRA 的一个创新点,是通过“矩阵分解”的方式,优化插入层的参数量。我们可以将一个权重矩阵分解为两个矩阵进行存储,如果W是d*d维矩阵,那么A和B矩阵的尺寸可以减小到d*n,这样n远小于d,大幅度减少存储空间。
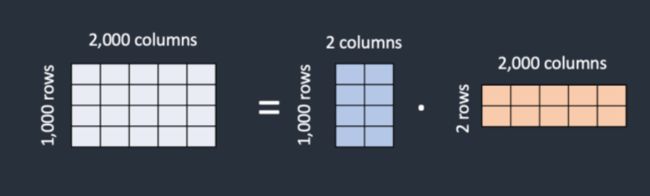
训练会冻结预训练模型的参数,通过 W’ = W +△W 的方式来调整模型参数,这里的△W= ABT,其中AB矩阵就是我们的训练目标。如下图所示:

LoRA 的优势在于生成的模型较小,训练速度快,但推理需要同时使用 LoRA 模型和基础模型。LoRA 模型虽然会向原有模型中插入新的网络层,但最终效果还是依赖基础模型。
我们使用 Huggingface 提供的训练代码,准备好图片后,在A10上使用以下脚本启动训练:
accelerate launch train_dreambooth_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of az baby" \
--class_prompt="a photo of baby" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--checkpointing_steps=100 \
--learning_rate=1e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--validation_prompt="a photo of az baby" \
--validation_epochs=50 \
--seed="0"
因为我们采用 Dreambooth-LoRA 方式进行训练,所以超参数基本与前述的 Dreambooth 一致。训练代码
LoRA 输出默认为 Pytorch 文件格式,如果需要在 Stable Diffusion Web UI 里使用,先将模型转化为 safetensors 格式,然后放入 $HOME/stable-diffusion-webui/models/Lora 目录使用。脚本链接
python diffusers-lora-to-safetensors.py --file pytorch_lora_weights.bin
Stable Diffusion 性能优化
与训练阶段侧重于准确预测标签和提高模型精度不同,推理阶段更看重高效处理输入并生成预测结果,同时减少资源消耗,在一些应用场景里,还会采用量化技术,在精度和性能之间取得平衡。
Stable Diffusion 是一个多模型组成的扩散Pipeline,由三个部分组成:变分自编码器 VAE、UNet 和文本编码器 CLIP。模型的推理耗时主要集中在 UNet,我们选择对这部分进行优化,提高推理性能和效率。

目前社区和硬件厂商提供了多种优化方案,但这些方案接口定义复杂,使用门槛高,使得难以被广泛采用。腾讯云 TACO 只需简单操作,即可实现 Stable Diffusion 推理优化,轻松应用只被少数专家掌握的技术。
腾讯云 TACO 使用自研的编译后端,对 UNet 模型以静态图方式进行编译优化,同时根据不同的底层硬件,动态选择 Codegen 优化策略,输出更高效的机器代码,提升推理速度,减少资源占用。
Dreambooth 优化
复用训练使用的 A10 GPU 服务器,参考TACO Infer 优化 Stable Diffusion 模型,安装 Docker runtime,并拉取预置优化环境的 sd_taco:v3 镜像。因涉及编译生成机器码,最终部署的目标 GPU 型号,需要和优化时的 GPU 型号保持一致。
使用-v命令挂载微调后的 Dreambooth diffusers 模型目录,交互式启动容器。
docker run -it --gpus=all --network=host -v /[diffusers_model_directory]:/[custom_container_directory] sd_taco:v3 bash
在镜像里执行 python export_model.py,采用 TorchScript tracing 生成序列化的 UNet 模型文件。
script_model = torch.jit.trace(model, test_data, strict=False)
script_model.save("trace_module.pt")
在镜像里执行 python demo.py,对导出的 UNet Model 进行性能优化。这一步 TACO sdk 会对导出的 IR 进行编译优化,包括计算图结构优化、算子优化、以及其他针对代码生成和执行的优化技术。
完成后,使用 jit 方式加载优化后的 UNet Model。对模型输入 a. 图像隐空间向量【batchsize,隐空间通道,图片高度/8,图片宽度/8】b. timesteps值 【batchsize】c. 【batchsize,文本最大编码长度,向量大小】,即可对优化结果进行测试。代码参考如下:
import torch
import taco
import os
taco_path = os.path.dirname(taco.__file__)
torch.ops.load_library(os.path.join(taco_path, "torch_tensorrt/lib/libtorchtrt.so"))
optimized_model = torch.jit.load("optimized_recursive_script_module.pt")
pic = torch.rand(1, 4, 64, 64).cuda() // picture
timesteps = torch.tensor([1]*1) // timesteps
context = torch.randn(1, 77, 768) // text embedding
with torch.no_grad():
output = optimized_model(pic, timesteps, context)
print(output)
对比社区方案,TACO 优化后模型出图速度提高50%,效果见下图:
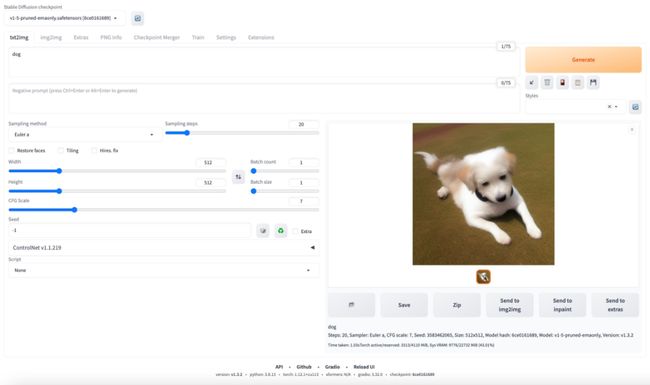
(20 steps,Euler a,512 * 512,torch 1.12,无xformers,1s出图)
LoRA 优化
使用 LoRA合并脚本,将训练得到的 LoRA 文件,和基础模型进行合并。命令参考:
python networks/merge_lora.py --sd_model ../v1-5-pruned-emaonly.safetensors --save_to ../lora-v1-5-pruned-emaonly.safetensors --models <LoRA文件目录> --ratios <LoRA权重>
参考上述 Dreambooth 的优化方法,对合并后的模型进行导出和优化。效果见下图:

(20 steps,Euler a,512 * 512,anime-tarot-card,torch 1.12,无xformers,1s出图)
ControlNet 优化
Dreambooth 及 LoRA 优化模型,依然适用于 ControlNet 使用场景,对比社区方案,TACO 优化后 ControlNet 的出图速度可以提高30%以上,效果见下图:
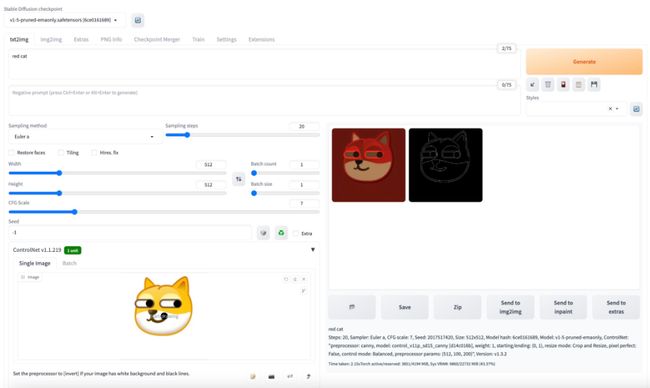
(20 steps,Euler a,512 * 512,ControlNet-canny,torch 1.12,无xformers,2s出图)
经过 TACO 优化后的 UNet 模型,测试表明前向推理速度提高至开源方案的4倍。在实际应用中,512*512,20 steps 的配置下,Stable Diffusion Web UI 端到端的推理时间缩短 1 秒。以上优化详细过程及环境获取,参考 TACO Infer 优化 Stable Diffusion 系列模型。
总结
本文介绍了 Dreambooth 和 LoRA 在腾讯云A10机型上的微调实践,以及针对这两种模型的 TACO 推理优化过程。感兴趣的同学可以在文章的基础上,尝试训练风格独特的模型,辅以 TACO 推理优化能力,创造符合自身业务的云上 Stable Diffusion。