Set接口下的实现类HashSet,和Map接口下的HashMap的相关内容
Set接口的相关细节:
1.实现Set接口的类中不能添加重复的元素(会进行源码分析),且只能存在一个null值。
2.添加和取出的元素顺序是不一致的即无序,且没有索引。
3.Set接口也是Collection接口的子接口,所以Set接口的方法和List接口的方法一样。
4.遍历方式可以使用迭代器,增强for,但是不能通过索引来遍历。
HashSet的相关细节:
HashSet实现了Set接口;
HashSet的底层其实调用的是HashMap,源码如下:

可以存放null值,但是只能存放一个。
HashSet的实例演示:
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
@SuppressWarnings({"all"})
public class myHashSet {
public static void main(String[] args) {
Set set = new HashSet();
set.add("jack");
set.add("jack");
set.add("jhon");
set.add("mack");
System.out.println(set);
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
Object next = iterator.next();
System.out.println(next);
}
}
}
这里我们发现不能添加重复的元素,这里我们来看一下是如何判断元素是否相同的。
这里我们来看一下源码:

这里我们会进入一个putVal()这个方法当中这里我们发现该方法应该传入两个参数,但是我们只传入了一个,其实value值我们这边是用了一个默认的值来进行填充,这里也不做过多的分析;
当我们第一次执行add语句的时候我们就会进行一个容量的初始话,至于第一次扩容是多少我们来分析一下:
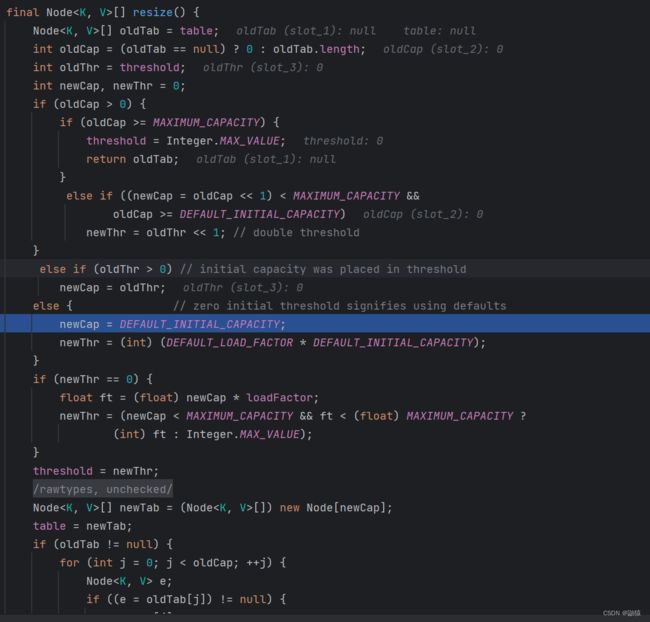
我们oldcap一开始的长度为0,所以肯定是满足不了上述条件的,所以这里就直接进入到
newCap = DEFAULT_INITIAL_CAPACITY;这段代码中至于这个值是多少我们可以查看一下:

这里我们发现该数值为16,那我们待会看一下初始化之后是否为16;

该源码中我们发现table就是HashSet的一个数组,类型是Node[],这里通过table是否为空和长度是否为0来进行判断是否需要扩容这里我们也很明显能看出来第一次扩容就为16,接下来我们通过key来算出其对应的hash值,再通过该hash值来算出对应的索引位置即该元素的存放位置,并赋值给p,并判断是否为空如果为空则插入(提示:这里key算出来的hash值并不是自身真正的hash值它是进行处理过后的hash值)如下图:

它是通过hash这个静态方法来进行一系列的处理。

这里就是将我们新的元素添加到Node[]数组中操作,这里我们会发现我们返回的是个布尔类型,这也我们判断是否添加元素的关键,因为原数组中没有元素,所以不会进行比较,接下来我们来添加相同和不同的元素时的方法调用情况:
1.相同的元素:

前面的调用跟前面的时完全相同的,不同点就是在这,它首先对你的hash值进行一个判断,看是否存放在同一个索引位置,如果相同则进行equals()进行比较看是否数组中已存在相同的元素,即比较俩者是否为同一个对象,相同的话前面的add方法中的return则返回的是false。
这就是我们HashSet的一大特点,接下来我们来了解一下HashSet的底层机理,HashSet的底层其实调用的是HashMap,HashMap的底层则是(数组+链表+红黑树)。
这里我们看源码的时候会发现我们Node[]数组中的元素为HashMap$Node,该对象中含有四个属性:

这里的next大家是不是很熟悉,这就是实现我们链表功能需要的,其实一个索引位置不一定只能存放一个值,不同元素如果hash值算得的索引值相同就会通过next将其接在后面待会会进行演示。接下来我们来了解一下红黑树机制,红黑树其实才是能存放很多元素的关键,这个待会深入了解,

这里就是两个不同的对象,但是通过hash值算出来的索引位置相同,则直接接在该元素的后面。
我们先来聊一聊我们HashSet的扩容机制是怎么进行扩容:
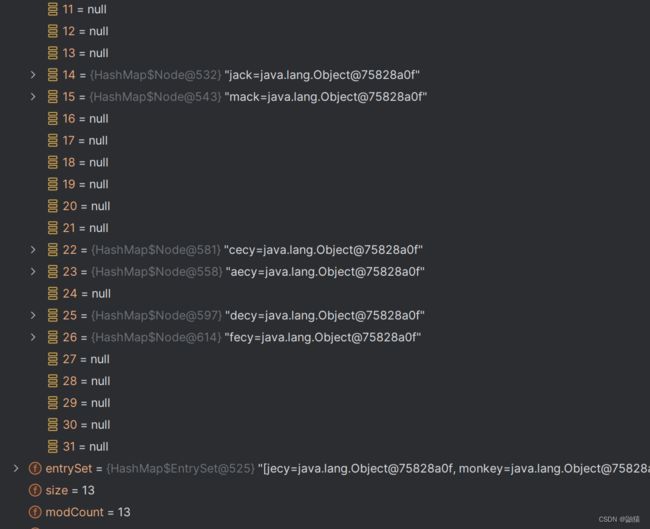
这里我们发现当我们存储到12个的时候继续存储就会自动的从16变成32为什么不是等到存满了再进行扩容,这就是我们HashSet的精妙之处,它设定了一个临界值,当达到这个值的时候就会自动扩容,避免发生堵塞现象,我们来看一下它的方法调用:

这里就是判断是否进行扩容的判断这里的threshold就是我们所说的临界值,但是为什么是12?这个我们来追一下源码:
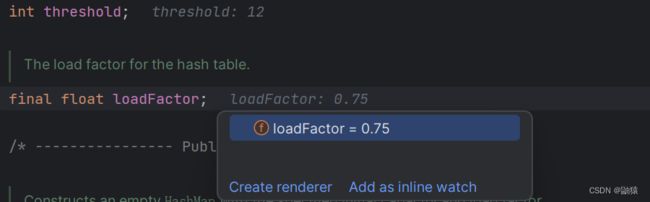
16 * 0.75 = 12,12这个值就是这么来的。
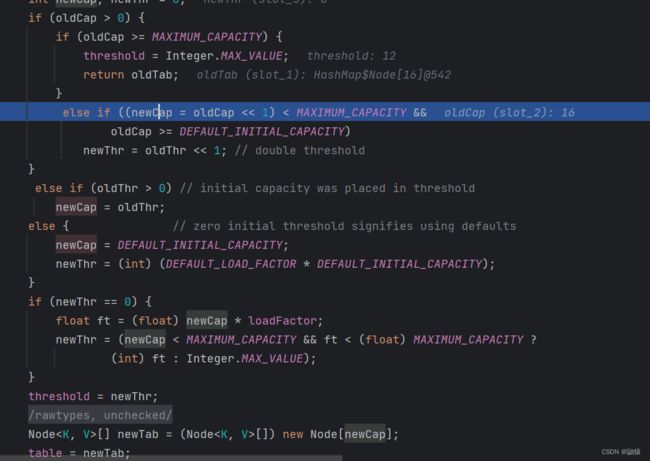
这里就进入了它真正扩容的地方即方法resize()我们发现它是通过位运算符将其向左移动一位即*2所以扩容成原来的两倍。
接下来我们来看一下红黑树是如何生成的,我们先来说明一下树化的条件是什么,单个链表的长度大于8,而且数组的容量大于64,则会进行树化,这俩个条件必须满足有一条不满足都不会进行树化(提示:同一个索引位置包含多少元素就算多少个,不是一个索引位置就算一个)
import java.util.HashSet;
@SuppressWarnings({"all"})
public class myHashSet {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
hashSet.add(new cat("小明",10));
}
}
class cat{
public String name;
public int age;
public cat(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return 100;
}
@Override
public String toString() {
return "cat{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}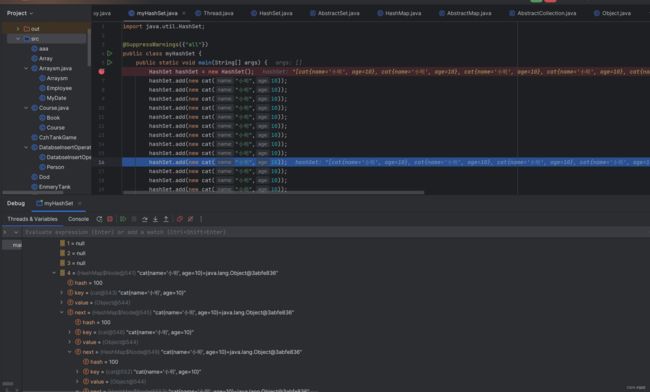
这里我们将cat类中的hashCode设置成固定的值100,这样我们new cat计算出来的索引位置肯定是同一个这里算出来是4我们发现我们存储进去9次,但是我们发现我存储的对象的属性都是相同的,但是却能存储进去,这是因为我是new出来的对象,而且没有进行任何处理,所以肯定不是同一个对象使用可以存储,我们发现现在单链已经到8了,但是却没有进行树化那是因为我们总容量并没有到64,我们继续添加看看效果:
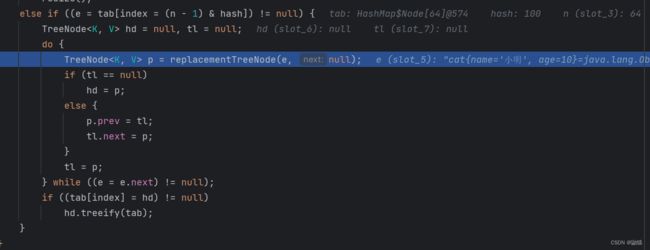
这里就是我们进行树化的源码有兴趣的可以追一下。
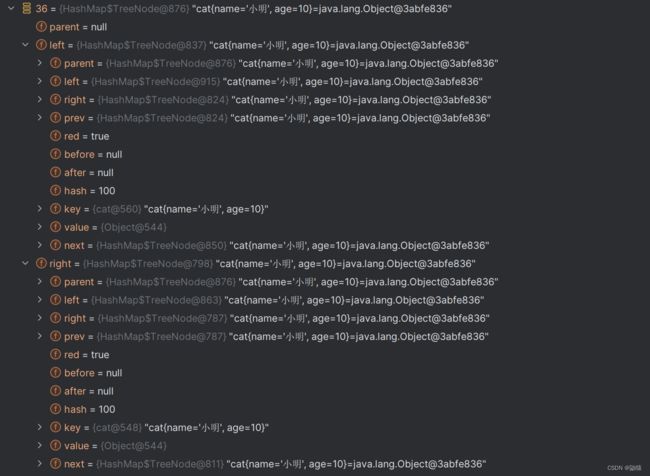
我们发现进行树化后多出来了两个属性,一个right还有一个left就相当于二叉树的左右两支。
接下来我们来说一下HashMap的相关细节:
首先我们知道Hashset的底层掉的就是HashMap所以基本上都调用的是相同源码
但是HashMap它存储的元素是k-v值,即键值对,它可以设置value值,并且可以通过key值来查询到相关的value值,key值不能重复,但是value可以重复。
import java.util.HashMap;
import java.util.Map;
@SuppressWarnings({"all"})
public class myHashSet {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1", "郭靖");//k-v
map.put("no2", "张无忌");//k-v
map.put("no1", "张三丰");//当有相同的 k , 就等价于替换. map.put("no3", "张三丰");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等价替换
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "赵敏");//k-v
map.put(new Object(), "金毛狮王");//k-v
// 通过 get 方法,传入 key ,会返回对应的 value
System.out.println(map.get("no2"));//张无忌
System.out.println("map=" + map);
}
}这里就是相关代码的演示,也不多深入讨论了,接下来我们说一个HashMap的不同点;
由于k-v值是存放在HashMap$Node这个对象中,而且Node实现了Entry接口,所以k-v就相当于是一个Entry,Entry可以包装到EntrySet当中,EntrySet当中有keySet,Values两个数组分别存储key和value,但是它们还是一一对应起来的。

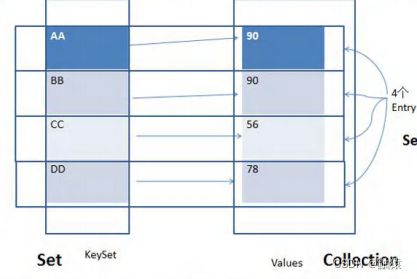
就像该图演示的效果一样,这样就可以单独提取出我们想要的值,但是前提必须对其进行包装。