系列九、SpringBoot + MyBatis + Redis实现分布式缓存
一、缓存介绍
1.1、概述
缓存是计算机内存中的一段数据(PS:内存中的数据具有读写快、断电立即消失的特点),合理地使用缓存能够提高网站的吞吐量和运行效率,减轻数据库的访问压力。那么哪些数据适合缓存呢?使用缓存时,一定是数据库中的数据极少发生改变,更多用于查询的情况,例如:省、市、区、县、村等数据。
1.2、本地缓存 vs 分布式缓存
本地缓存:存储在应用服务器内存中的数据称之为本地缓存(local cache);
分布式缓存:存储在当前应用服务器内存之外的数据称之为分布式缓存(distribute cache);
集群:将同一服务的多个节点放在一起,共同为系统提供服务的过程称之为集群(cluster);
分布式:由多个不同的服务集群共同对系统提供服务,那么这个系统就被称之为分布式系统(distribute system);
1.3、MyBatis默认的缓存策略
关于MyBatis的一级缓存、二级缓存请参考 MyBatis系列文章,这里不再赘述。单机版的mybatis一级缓存默认是开启的,开启二级缓存也很简单,再mybatis的核心配置文件和xxxMapper.xml中分别添加如下配置即可激活MyBatis的二级缓存:
二级缓存也叫SqlSeesionFactory级别的缓存,其特点是所有会话共享。不管是一级缓存还是二级缓存,这些缓存都是本地缓存,适用于单机版。互联网发展的今天,生产级别的服务,不可能再使用单机版的了,基本都是微服务+分布式那一套,如果还使用MyBatis默认的缓存策略,显然是行不通的,为了解决这个问题,分布式缓存应运而生。

二、MyBatis中使用分布式缓存
2.1、基本思路
(1)自定义缓存实现Cache接口;
(2)在xxxMapper.xml中开启二级缓存时指明缓存的类型;
2.2、代码实战
2.2.1、项目概览

2.2.2、pom
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-devtools
mysql
mysql-connector-java
8.0.26
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.3.1
com.alibaba
druid-spring-boot-starter
1.1.10
org.springframework.boot
spring-boot-starter-data-redis
org.projectlombok
lombok
1.18.30
cn.hutool
hutool-all
5.8.21
org.apache.commons
commons-lang3
org.apache.commons
commons-collections4
4.4
com.alibaba.fastjson2
fastjson2
2.0.25
2.2.3、yml
server:
port: 9999
spring:
redis:
host: xxxx
port: 6379
database: 0
password: 123456
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/20231018_redis?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=GMT
username: root
password: 123456
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: org.stat.entity.model
configuration:
map-underscore-to-camel-case: true
logging:
level:
org:
star:
mapper: debug
2.2.4、MyRedisConfig
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 15:28
* @Description:
*/
@Configuration
public class MyRedisConfig {
/**
* RedisTemplate k v 序列化
* @param connectionFactory
* @return
*/
@Bean
public RedisTemplate redisTemplate(LettuceConnectionFactory connectionFactory) {
RedisTemplate redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
} 2.2.5、MyRedisCache
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 15:30
* @Description:
*/
public class MyRedisCache implements Cache {
/**
* id为mapper中的namespace
*/
private final String id;
private RedisTemplate getRedisTemplate() {
RedisTemplate redisTemplate = (RedisTemplate) MyApplicationContextAware.getBean("redisTemplate");
return redisTemplate;
}
/**
* 必须存在构造方法
*
* @param id
*/
public MyRedisCache(String id) {
System.out.println("RedisCache id============>" + id);
this.id = id;
}
/**
* 返回Cache的唯一标识
*
* @return
*/
@Override
public String getId() {
return this.id;
}
/**
* 往Redis缓存中存储数据
* @param key
* @param value
*/
@Override
public void putObject(Object key, Object value) {
System.out.println("putObject key : " + key);
System.out.println("putObject value : " + value);
getRedisTemplate().opsForHash().put(Convert.toStr(id),key2MD5(Convert.toStr(key)),value);
}
/**
* 从Redis缓存中取数据
* @param key
* @return
*/
@Override
public Object getObject(Object key) {
System.out.println("getObject key : " + key);
return getRedisTemplate().opsForHash().get(Convert.toStr(id),key2MD5(Convert.toStr(key)));
}
/**
* 主要事项:这个方法为MyBatis的保留方法,默认没有实现,后续版本可能会实现
* @param key
* @return
*/
@Override
public Object removeObject(Object key) {
System.out.println("removeObject key(根据指定Key删除缓存) : " + key);
return null;
}
/**
* 只要执行了增删改操作都会执行清空缓存的操作
*/
@Override
public void clear() {
System.out.println("清空缓存");
getRedisTemplate().delete(Convert.toStr(id));
}
/**
* 计算缓存数量
* @return
*/
@Override
public int getSize() {
Long size = getRedisTemplate().opsForHash().size(Convert.toStr(id));
return size.intValue();
}
/**
* 将Key进行MD5加密
* @param key
* @return
*/
private String key2MD5(String key) {
return DigestUtils.md5DigestAsHex(key.getBytes(StandardCharsets.UTF_8));
}
}2.2.6、DepartmentDO
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 12:48
* @Description:
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
@ToString(callSuper = true)
public class DepartmentDO implements Serializable {
/**
* 编号
*/
private Integer id;
/**
* 部门名称
*/
private String departmentName;
}2.2.7、DepartmentMapper
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 12:50
* @Description:
*/
public interface DepartmentMapper {
/**
* 查询所有部门
* @return
*/
List listAllDepartment();
} 2.2.8、DepartmentMapper.xml
2.2.9、DepartmentMapperTest
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 12:51
* @Description:
*/
@SpringBootTest
public class DepartmentMapperTest {
@Autowired
private DepartmentMapper departmentMapper;
@Test
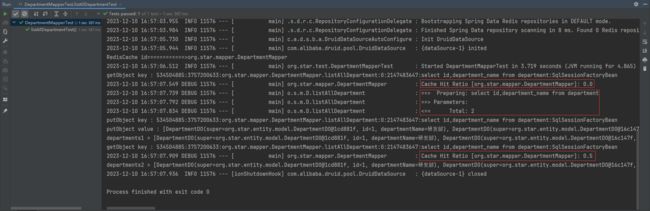
public void listAllDepartmentTest() {
List departments1 = departmentMapper.listAllDepartment();
System.out.println("departments1 = " + departments1);
List departments2 = departmentMapper.listAllDepartment();
System.out.println("departments2 = " + departments2);
}
} 
 2.3、存在的问题
2.3、存在的问题
2.3.1、问题说明
项目中如果某个业务涉及到的查询仅仅是单表查询,即类似上述的查询,这样使用分布式缓存一点问题没有,但是当有多张表关联查询时,将会出现问题。会出现什么问题呢?假设当前有两个持久化类,它们具有一对一的关联关系,例如员工 & 部门,从员工的角度看一个员工属于一个部门,部门表查询会缓存一条数据,员工表查询时也会缓存一条数据,下次再查询时将不会从DB中查询了,而是从缓存中取,那么当员工表中执行级联更新(增、删、改)时,将会清空员工对应的缓存 & 更新DB中员工表和部门表的数据,这个时候如果再次查询部门表中的数据,由于缓存中的数据还在,再次查询时直接从缓存中取数据了,导致查询到的数据(缓存中的数据)和实际数据库表中的数据不一致!案例演示(基于上边的案例,增加员工信息):
2.3.2、EmployeeDO
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 15:38
* @Description:
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
@ToString(callSuper = true)
public class EmployeeDO implements Serializable {
/**
* 员工编号
*/
private Integer id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 部门
*/
private DepartmentDO department;
}2.3.3、EmployeeMapper
public interface EmployeeMapper {
/**
* 查询指定id员工的个人信息和部门信息
* @param id
* @return
*/
EmployeeDO getDetail(Integer id);
/**
* 级联更新员工信息(更新员工信息 & 部门信息)
* @param param
*/
void updateEmployeeCascade(EmployeeDO param);
}2.3.4、EmployeeMapper.xml
update employee e left join department d
on e.department_id = d.id
e.name = #{name},
e.age = #{age},
d.department_name = #{department.departmentName}
where e.id = #{id}
2.3.5、EmployeeMapperTest
/**
* @Author : 一叶浮萍归大海
* @Date: 2023/12/10 15:42
* @Description:
*/
@SpringBootTest
public class EmployeeMapperTest {
@Autowired
private EmployeeMapper employeeMapper;
@Autowired
private DepartmentMapper departmentMapper;
@Test
public void listAllUserTest() {
List employeeDOS1 = employeeMapper.listAllEmployee();
System.out.println("employeeDOS1 = " + employeeDOS1);
List employeeDOS2 = employeeMapper.listAllEmployee();
System.out.println("employeeDOS2 = " + employeeDOS2);
}
@Test
public void getUserByIdTest() {
EmployeeDO employee1 = employeeMapper.getEmployeeById(2);
System.out.println("employee1 ============> " + employee1);
EmployeeDO employee2 = employeeMapper.getEmployeeById(2);
System.out.println("employee2 ============> " + employee2);
}
@Test
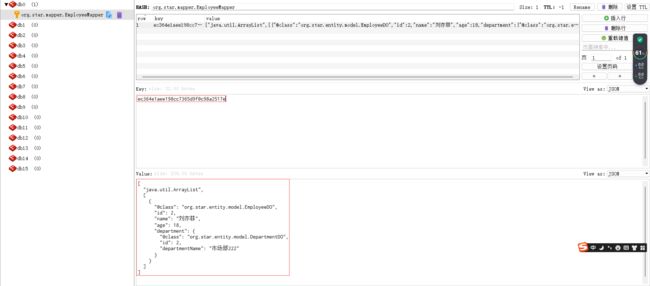
public void getDetailTest() {
EmployeeDO employeeDO1 = employeeMapper.getDetail(2);
System.out.println("employeeDO1 = " + employeeDO1);
EmployeeDO employeeDO2 = employeeMapper.getDetail(2);
System.out.println("employeeDO2 = " + employeeDO2);
}
@Test
public void relationShipTest() {
EmployeeDO employeeDO = employeeMapper.getDetail(2);
System.out.println("employeeDO = " + employeeDO);
List departmentDOS = departmentMapper.listAllDepartment();
System.out.println("departmentDOS = " + departmentDOS);
}
@Test
public void updateEmployeeCascadeTest() {
EmployeeDO employeeDO = new EmployeeDO()
.setId(2)
.setName("刘亦菲")
.setAge(18)
.setDepartment(
new DepartmentDO()
.setId(2)
.setDepartmentName("市场部")
);
employeeMapper.updateEmployee(employeeDO);
}
} 2.3.6、测试
(1)执行EmployeeMapperTest #getDetailTest
(2)执行 DepartmentMapperTest #listAllDepartmentTest
(3)级联更新 EmployeeMapperTest #updateEmployeeCascadeTest,将id为2的部门名称改为市场部,执行完此操作后,redis中员工相关的缓存将被清空;
(4)再次执行DepartmentMapperTest #listAllDepartmentTest
结果分析:查询到的数据和数据库中的数据不符。
原因:
具有级联关系的查询,当执行级联更新(增、删、改)时将会触发清空redis缓存,而清空缓存是按照mapper中配置的namespace进行删除的,导致被关联的那一方即使DB中的数据被更新了,redis中对应的缓存也不会被清空。



2.3.7、解决方案
在级联更新的xxxMapper.xml中使用
进行级联清空缓存,如下: